此处依旧书接上回,话不多说且看内容!
函数
此部分主要包含 Cypher 查询语言中的所有函数的信息。
断言(Predicate)函数
断言函数是对给定的输入返回 true 或者 false 的布尔函数,他们主要用于查询的 WHERE 部分过滤子图。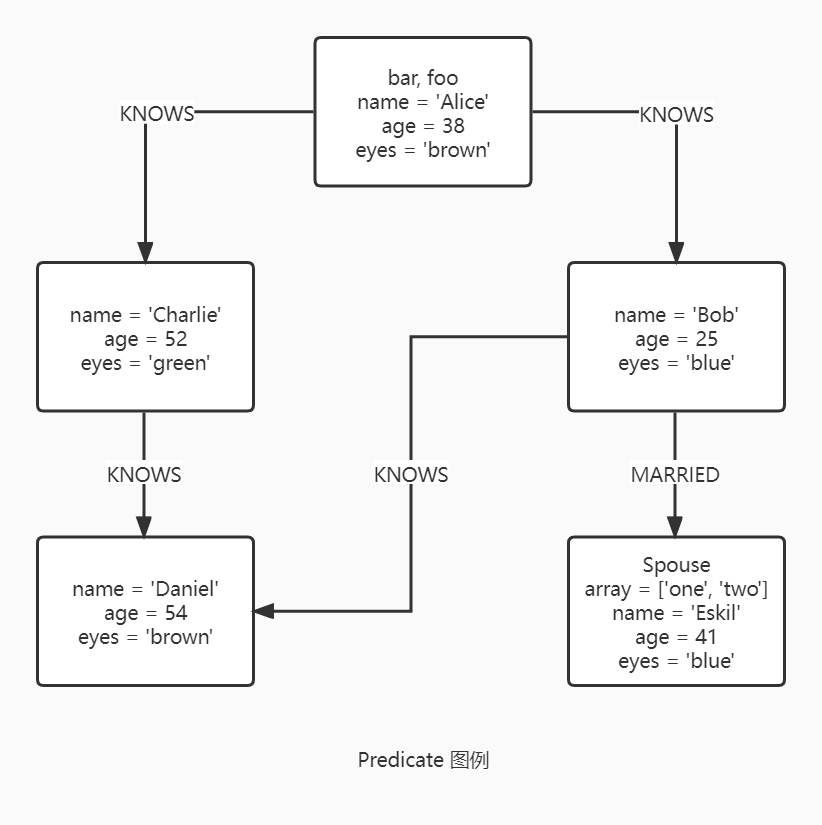
all()
判断断言是否适用于列表中的所有元素。
语法: all(variable IN list WHERE predicate)
参数:
list:返回列表的表达式variable:用于断言中的变量predicate:用于测试列表中所有元素的断言
1 | // 返回路径的节点中都有一个 age 大于 30 的属性 |
any()
判断断言是否至少适用于列表中的一个元素。
语法: any(variable IN list WHERE predicate)
参数:
list:返回列表的表达式variable:用于断言中的变量predicate:用于测试列表中所有元素的断言
1 | // 返回路径的节点中的 array 属性中至少有一个值 one |
none()
判断断言不适用于列表中的所有元素,则返回 true。
语法: none(variable IN list WHERE predicate)
参数:
list:返回列表的表达式variable:用于断言中的变量predicate:用于测试列表中所有元素的断言
1 | // 返回路径的节点没有 age 属性等于 25 |
single()
判断断言刚好只适用于列表中的某一个元素,则返回 true。
语法: single(variable IN list WHERE predicate)
参数:
list:返回列表的表达式variable:用于断言中的变量predicate:用于测试列表中所有元素的断言
1 | // 返回路径的节点中刚好有 eyes 属性值为 blue |
exists()
判断数据库中存在该模式或者节点中存在该属性,则返回 true。
语法: exists(pattern-or-property)
参数:
pattern-or-property:模式或者属性
1 | // 返回节点的 name 属性和一个是否结婚的标识 |
标量(Scalar)函数
标量函数返回一个单值。length() 与 size() 函数非常相似,但他们是完全不同的函数。length() 目前用于字符串、路径、列表和模式表达式。
size()
返回表中元素的个数。
语法:size(list)
参数:
list:返回列表的表达式
1 | // 返回列表中元素的个数 |
模式表达式的 size()
这里的 size() 的参数不是列表,而是一个模式表达式匹配到的查询结果集。这里计算的是结果集元素的个数,而不是表达式本身的长度。
语法:size(pattern expression)
参数:
pattern expression:返回列表的模式表达式
1 | // 返回模式表达式匹配到的子图的个数 |
length()
返回路径的长度。
语法:length(path)
参数:
path:返回路径的表达式
1 | // 返回路径的长度 |
字符串 length()
返回字符串的长度。
语法:length(string)
参数:
string:返回字符串的表达式
1 | // 返回 name 为 Alice 的长度 |
type()
返回字符串代表的关系类型。
语法:type(relationship)
参数:
relationship:一个关系
1 | // 返回路径的长度 |
id()
返回节点或者关系的 id。
语法:id(property-container)
参数:
property-container:一个节点或者关系
1 | // 返回节点的 ID |
coalesce()
返回表达式列表中的第一个非空的值。如果所有的实参都为空,则返回 null。
语法:coalesce(expression[, expression]*)
参数:
expression:表达式,可能返回 null
1 | MARCH (a) WHERE a.name = 'Alice' RETURN coalesce(a.hairColor, a.eyes) |
head()
返回列表中的第一个元素。
语法:head(expression)
参数:
expression:返回列表的表达式
1 | // 返回列表中的第一个元素 |
last()
返回列表中的最后一个元素。
语法:last(expression)
参数:
expression:返回列表的表达式
1 | // 返回列表中的最后一个元素 |
timestamp()
返回当前时间的时间戳,单位以毫秒计算。它在整个查询中始终返回一个值,即使在一个运行很长时间的查询中。
语法:timestamp()
1 | // 返回当前时间 |
startNode()
返回一个关系的开始节点。
语法:startNode(relationship)
参数:
relationship:返回关系的表达式
1 | // 返回列表中的最后一个元素 |
endNode()
返回一个关系的结束节点。
语法:endNode(relationship)
参数:
relationship:返回关系的表达式
1 | // 返回列表中的最后一个元素 |
properties()
将实参转为属性值的 map。如果实参是一个节点或者关系,则返回的就是节点或者关系的属性的 map;如果市场已经是 map,则原样返回。
语法:properties(expression)
参数:
expression:返回节点、关系或者map的表达式
1 | CREATE (p:Person {name: 'Stefan', city: 'Berlin'}) RETURN properties(p) |
toInt()
将实参转为一个整数。字符串会被解析成一个整数,如果解析失败则会返回 null。浮点数被强制转换为整数。
语法:toInt(expression)
参数:
expression:返回任意值的表达式
1 | RETURN toInt('42'), toInt('not a number') |
toFloat()
将实参转为一个浮点数。字符串会被解析成一个浮点数,如果解析失败则会返回 null。整数被强制转换为浮点数。
语法:toFloat(expression)
参数:
expression:返回任意值的表达式
1 | RETURN toFloat('42.2'), toFloat('not a number') |
列表(List)函数
列表函数返回列表中的元素。
nodes()
返回一条路径中的所有节点。
语法:nodes(path)
参数:
path:一条路径
1 | MATCH p = (a)-->(b)-->(c) WHERE a.name = 'Alice' AND c.name = 'Eskill' RETURN nodes(p) |
relationships()
返回一条路径中的所有关系。
语法:relationships(path)
参数:
path:一条路径
1 | MATCH p = (a)-->(b)-->(c) WHERE a.name = 'Alice' AND c.name = 'Eskill' RETURN relationships(p) |
labels()
以字符串列表的形式返回一条节点的所有标签。
语法:labels(node)
参数:
node:返回单个节点的任意表达式
1 | // 返回节点 a 的所有标签 |
keys()
以字符串列表的形式返回一条节点、关系或者 map 的所有属性的名称。
语法:keys(property-container)
参数:
property-container:一条节点、关系或者字面值的map
1 | // 返回节点 a 的所有属性的名称 |
extract()
返回节点或关系列表中返回单个属性或者某个函数的值。他将遍历整个列表,针对列表中的每个元素运行一个表达式,然后以列表的形式返回这些结果。他的工作方式类似于 Lisp 和 Scala 等函数式语言中的 map 方法。
语法:extract(variable IN list | expression)
参数:
list:返回列表的表达式variable:引用list中元素的变量,他在expression中会用到expression:针对列表中每个元素所运行的表达式,并产生一个结果列表
1 | // 返回路径中所有节点的 age 属性 |
extract()
返回节点或关系列表中返回单个属性或者某个函数的值。他将遍历整个列表,针对列表中的每个元素运行一个表达式,然后以列表的形式返回这些结果。他的工作方式类似于 Lisp 和 Scala 等函数式语言中的 map 方法。
语法:extract(variable IN list | expression)
参数:
list:返回列表的表达式variable:引用list中元素的变量,他在expression中会用到expression:针对列表中每个元素所运行的表达式,并产生一个结果列表
1 | // 返回路径中所有节点的 age 属性 |
filter()
返回列表中满足断言要求的所有元素。
语法:filter(variable IN list WHERE predicate)
参数:
list:返回列表的表达式variable:用于断言中的变量predicate:用于测试列表中所有元素的断言
1 | // 返回节点 a 的所有属性的名称 |
tail()
返回列表中除首元素之外的所有元素
语法:tail(expression)
参数:
expression:返回某个类型列表的表达式
1 | MATCH (a) WHERE a.name = 'Eskill' RETURN a.array, tail(a.array) |
range()
返回某个范围内的数值。值之间的默认步长为 1,范围包含起始边界。
语法:range(start, end[, step])
参数:
start:返回某个类型列表的表达式end:返回某个类型列表的表达式step:返回某个类型列表的表达式
1 | RETURN range(0, 10), range(2, 18, 3) |
reduce()
使用 reduce() 对列表中的每个元素执行一个表达式,将表达式结果存入一个累加器。他的工作方式类似于 Lisp 和 Scala 等函数式语言中的 fold 或者 reduce 方法。
语法:reduce(accumulator = initial, variable IN list | expression)
参数:
accumulator:用于累加每次迭代的部分结果initial:累加器的初始值list:返回列表的表达式variable:引用list中元素的变量,他在expression中会用到expression:针对列表中每个元素所运行的表达式,并产生一个结果列表
1 | // 本查询将路径中每个节点的 age 数值加起来,然后返回一个单值。 |
数学函数
这些函数仅适用于数值表达式。如果用于其他类型的值,将返回错误。
数值函数
abs()
返回数值的绝对值。
语法:abs(expression)
参数:
expression:数值表达式
1 | // 38 42 3 |
ceil()
返回大于或等于实参的最小参数。
语法:ceil(expression)
参数:
expression:数值表达式
1 | // 1 |
floor()
返回小于或等于表达式的最大的整数。
语法:floor(expression)
参数:
expression:数值表达式
1 | // 0 |
round()
返回距离表达式值最近的整数。
语法:round(expression)
参数:
expression:数值表达式
1 | // 3 |
sign()
返回一个数值的正负。如果值为零,则返回 0;如果为负数,则返回 -1;如果值为正数,则返回 1。
语法:sign(expression)
参数:
expression:数值表达式
1 | // -1, 1 |
rand()
返回 [0, 1) 之间的一个随机数,返回的数值在整个区间遵循均匀分布。
语法:rand()
1 | RETURN rand() |
对数函数
log()
返回表达式的自然对数。
语法:log(expression)
参数:
expression:数值表达式
1 | // 3.295836 |
log10()
返回表达式的常用对数(以 10 为底)。
语法:log10(expression)
参数:
expression:数值表达式
1 | // 1.4313637 |
exp()
返回 e^n ,这里 e 是自然对数的底,n 是表达式的实参值。
语法:exp(expression)
参数:
expression:数值表达式
1 | // 7.389056 |
e()
返回自然对数的底,即 e。
语法:e()
1 | RETURN e() |
sqrt()
返回数值的平方根。
语法:sqrt(expression)
参数:
expression:数值表达式
1 | // 16 |
三角函数
除非特别指明,所有的三角函数都是针对弧度制进行计算的。
sin()
返回表达式的正弦函数值。
语法:sin(expression)
参数:
expression:表示角的弧度的数值表达式
1 | // 0.4794255 |
cos()
返回表达式的余弦函数值。
语法:cos(expression)
参数:
expression:表示角的弧度的数值表达式
1 | // 0.8775825 |
tan()
返回表达式的正切值。
语法:tan(expression)
参数:
expression:表示角的弧度的数值表达式
1 | // 0.5463024 |
cot()
返回表达式的余切值。
语法:cot(expression)
参数:
expression:表示角的弧度的数值表达式
1 | // 1.8304877 |
asin()
返回表达式的反正弦值。
语法:asin(expression)
参数:
expression:表示角的弧度的数值表达式
1 | // 0.5235987 |
acos()
返回表达式的反余弦值。
语法:acos(expression)
参数:
expression:表示角的弧度的数值表达式
1 | // 1.0471975 |
atan()
返回表达式的反正切值。
语法:atan(expression)
参数:
expression:表示角的弧度的数值表达式
1 | // 0.4636476 |
atan2()
返回方位角,也可以理解为计算复数 x + y * i 的幅角。
语法:atan2(expression1, expression2)
参数:
expression1:表示复数x部分的数值表达式expression2:表示复数y部分的数值表达式
1 | // 0.6947382 |
pi()
返回常数 pi 的数值。
语法:pi()
1 | // 3.1415926 |
degrees()
将弧度转化为度。
语法:degrees(expression)
参数:
expression:表示角的弧度的数值表达式
1 | // 179.999847 |
radians()
将度转化为弧度。
语法:radians(expression)
参数:
expression:表示角度数的数值表达式
1 | // 3.1415926 |
haversin()
返回表达式的半正矢。
语法:haversin(expression)
参数:
expression:表示角的弧度的数值表达式
1 | // 0.06120871 |
字符串函数
下面的函数都是只针对字符串表达式。如果用于其他值,将返回错误。
replace()
返回被替代字符串替换后的字符串,他会替换所有出现过的字符串。
语法:replace(original, search, replace)
参数:
original:原字符串search:期望被替换的字符串replace:用于替换的字符串
1 | // hewwo |
substring()
返回原字符串的子串。他带有一个 0 为开始的索引值和长度作为参数。如果长度省略了,那么他返回从索引开始到结束的值字符串。
语法:substring(original, start[, length])
参数:
original:原字符串start:子串的开始位置length:子串的长度
1 | // ell |
left()
返回原字符串左边指定长度的子串。
语法:left(original, length)
参数:
original:原字符串length:左边子字符串的长度
1 | // hel |
right()
返回原字符串右边指定长度的子字符串。
语法:right(original, length)
参数:
original:原字符串length:右边子字符串的长度
1 | // llo |
ltrim()
返回原字符串移除左侧的空白字符后的字符串。
语法:ltrim(original)
参数:
original:原字符串
1 | // hello |
rtrim()
返回原字符串移除右侧的空白字符后的字符串。
语法:rtrim(original)
参数:
original:原字符串
1 | // hello |
trim()
返回原字符串移除两侧的空白字符后的字符串。
语法:trim(original)
参数:
original:原字符串
1 | // hello |
lower()
以小写的形式返回原字符串。
语法:lower(original)
参数:
original:原字符串
1 | // hello |
upper()
以大写的形式返回原字符串。
语法:upper(original)
参数:
original:原字符串
1 | // HELLO |
split()
返回以指定模式分隔后的字符串序列。
语法:split(original, splitPattern)
参数:
original:原字符串splitPattern:分隔字符串
1 | // ['one', 'two'] |
reverse()
返回原字符串的倒序字符串。
语法:reverse(original)
参数:
original:原字符串
1 | // margana |
toString()
将实参转化为字符串。他将整形、浮点型和布尔型转换为字符串。如果实参为字符串,则按原样返回。
语法:toString(expression)
参数:
expression:返回数值、布尔或者字符串的表达式
1 | RETURN toString(11.5), toString('already a string'), toString(TRUE) |
自定义函数
自定义函数用 Java 语言编写,可部署到数据库中,调用方式与其他 Cypher 函数一样。下面示例一个名为 join 的自定义函数。
调用自定义函数
调用自定义函数 org.neo4j.function.example.join()。
1 | // 'John, Paul, George, Ringo' |
编写自定义函数
自定义函数的白那些类似于过程(Procedure)的创建,但它采用 @UseFunction 注解,并且只返回一个单值。有效的输出类型包括 long, double, Double, boolean, Boolean, String, Node, RelationShip, Path, Map<String, Object>, List<T>,这里的 T 可以是任意支持的类型。
下面是一个简单的自定义函数例子,该函数将 List 中的字符串用指定的分隔符连接起来。
1 | public class Join { |
模式(Schema)
基于标签的概念,Neo4j 2.0 为图引入了可选模式。在索引的规范中的标签为图定义约束。索引和约束是图的模式。Cypher 引入了数据定义语言(Data Definition Language, DDL)来操作模式。
索引
数据库的索引是为了检索数据效率更高而引入的冗余信息。他的代价是需要额外的存储空间和写入时速度变慢为代价的。因此,决定哪些数据需要建立索引,哪些不需要是非常重要的工作。Cypher 允许所有节点的某个属性上有2特定的标签。索引一旦创建,他将自己管理并当图发生变化时自动更新。一旦索引创建并生效之后,Neo4j 将自动开始使用索引。
创建索引
使用 CREATE INDEX ON 可以在拥有某个标签的所有节点的某个属性上创建索引。注意,索引是在后台创建,并不能立刻生效。
1 | // 在拥有 Person 标签的所有节点的 name 属性上创建索引 |
Neo4j 中的标签类似关系数据库中的表名,属性名就相当于表的列名。
删除索引
使用 DROP INDEX 可以删除拥有某个标签的所有节点的某个属性上的索引。
1 | DROP INDEX ON :Person(name) |
使用索引
通常不需要在查询中指明使用哪个索引,Cypher 会自己决定。
1 | MATCH (person:Person {name: 'Andres'}) RETURN person |
在 WHERE 等式中使用索引
在 WHERE 语句中对索引的属性进行相等比较时,索引将会被自动使用。
1 | MATCH (person:Person) WHERE person.name = 'Andres' RETURN person |
在 WHERE 不等式中使用索引
在 WHERE 语句中对索引的属性进行不等(范围)比较时,索引将会被自动使用。
1 | MATCH (person:Person) WHERE person.name > 'B' RETURN person |
在 IN 中使用索引
针对 person.name 的 IN 断言将使用 Person(name) 索引。
1 | MATCH (person:Person) WHERE person.name IN ['Andres', 'Mark'] RETURN person |
在 STARTS WITH 中使用索引
针对 person.name 的 STARTS WITH 断言将使用 Person(name) 索引。
1 | MATCH (person:Person) WHERE person.name STARTS WITH 'And' RETURN person |
在检查属性存在性时使用索引
查询中的 has(p.name) 断言将使用 Person(name) 索引。
1 | MATCH (person:Person) WHERE exists(person.name) RETURN person |
约束
Neo4j 通过使用约束来保证数据完整性。约束可应用于节点和关系,可以创建节点属性的唯一性约束,也可以创建节点和关系的属性存在性约束。
可以使用属性的唯一性约束确保拥有特定标签的所有节点的属性的值是唯一的,唯一性约束并不意味着所有节点的属性都必须有一个唯一的值。这个规则不适用于没有该属性的节点。
可以使用属性的存在性约束确保拥有特定标签的所有节点或者拥有特定类型的所有关系的属性是存在的,所有的试图创建新的没有该属性的节点或关系,以及试图删除强制属性的查询都会失败。
属性存在性约束是在 Neo4j 企业版才支持的特性。
可以对某个给定的标签添加多个约束,也可以将唯一性约束和存在性约束同时添加到同一个属性上。
添加约束是一个花费时间较长的原子操作,因此在没有扫描完所有节点前是不会生效的。
节点属性的唯一性约束
创建唯一性约束
使用IS UNIQUE语法创建约束,他能确保数据库中拥有特定标签和属性值的节点是唯一的。1
CREATE CONSTRAINT ON (book:Book) ASSERT book.isbn IS UNIQUE
删除唯一性约束
使用DROP CONSTRAINT可以删除数据库中的一个约束。1
DROP CONSTRAINT ON (book:Book) ASSERT book.isbn IS UNIQUE
创建遵从属性唯一性约束的节点
创建一个数据库中不存在的isbn的Book节点。1
CREATE (book:Book {isbn: '144356265', title: 'Graph Databases'})
创建违背属性唯一性约束的节点
创建一个数据库中已经存在的isbn的Book节点。1
2// Node 0 already exissts
CREATE (book:Book {isbn: '144356265', title: 'Graph Databases'})因为冲突的节点而创建属性唯一性约束失败
当数据库存在两个Book节点拥有相同的isbn号时,在Book节点的的isbn属性上创建属性唯一性约束。1
2// unable to create CONSTRAINT ON (book:Book) ASSERT book.isbn IS UNIQUE; Multiple node with label 'Book' have property `isbn = '144356265'`: node(0), node(1)
CREATE CONSTRAINT ON (book:Book) ASSERT book.isbn IS UNIQUE
节点属性的存在性约束
创建节点属性存在性约束
使用ASSERT exists(variable.propertyName)创建约束,可确保有指定标签的所有节点都有一个特定的属性。1
CREATE CONSTRAINT ON (book:Book) ASSERT exists(book.isbn)
删除节点属性存在性约束
使用DROP CONSTRAINT可以删除数据库中的一个约束。1
DROP CONSTRAINT ON (book:Book) ASSERT exists(book.isbn)
创建遵从属性存在性约束的节点
创建一个数据库中不存在的isbn的Book节点。1
CREATE (book:Book {isbn: '144356265', title: 'Graph Databases'})
创建违背属性存在性约束的节点
在有:Book(isbn)属性存在性约束的情况下,创建一个没有的isbn属性的Book节点。1
2// Node 1 with labek "Book" must have the property "isbn" due to a constraint
CREATE (book:Book {title: 'Graph Databases'})删除有存在性约束的节点属性
在有:Book(isbn)属性存在性约束的情况下,删除一个Book节点的isbn属性。1
2// Node 0 with label "Book" must have the property "isbn" due to a constraint
MATCH (book:Book {title: 'Graph Databases'}) REMOVE book.isbn因已存在的节点而创建节点属性存在性约束失败
当数据库的Book节点没有isbn属性时,试图为Book节点创建isbn的属性存在性约束。1
2// unable to create CONSTRAINT ON (book:Book) ASSERT exists(book.isbn): Node(0) wi8th label 'Book' has no value for property `isbn`
CREATE CONSTRAINT ON (book:Book) ASSERT exists(book.isbn)
关系属性存在性约束
创建关系属性存在性约束
使用ASSERT exists(variable.propertyName)创建约束,可确保有指定类型的所有关系都有一个特定的属性。1
CREATE CONSTRAINT ON ()-[like:LIKED]-() ASSERT exists(like.day)
删除关系属性存在性约束
使用DROP CONSTRAINT可以删除数据库中的一个约束。1
DROP CONSTRAINT ON ()-[like:LIKED]-() ASSERT exists(like.day)
创建遵从属性存在性约束的关系
创建一个存在的day属性的LIKED关系。1
CREATE (user:User)-[like:LIKED {day: 'yesterday'}]->(book:Book)
创建违背属性存在性约束的关系
在有:LIKED(day)属性存在性约束的情况下,创建一个没有的day属性的LIKED关系。1
2// relationship 1 with type "LIKED" must have the property "day" due to a constraint
CREATE (user:User)-[like:LIKED]->(book:Book)删除有存在性约束的关系属性
在有:LIKEd(day)属性存在性约束的情况下,删除一个LIKED节点的day属性。1
2// relationship 0 with type "LIKED" must have the property "day" due to a constraint
MATCH (user:User)-[like:LIKED]->(book:Book) REMOVE like.day因已存在的关系而创建关系属性存在性约束失败
当数据库存在LIKED节点没有day属性时,试图为LIKED节点创建day的属性存在性约束。
这种情况因为与已存在的数据冲突,因此约束创建失败。可以选择移除冲突的关系,然后再重新创建约束。1
2// unable to create CONSTRAINT ON ()-[like:LIKED]-() ASSERT exists(like.day): relationship(0) with type `LIKED` has no value for property `day`
CREATE CONSTRAINT ON ()-[like:LIKED]-() ASSERT exists(like.day)
统计
当执行一个 Cypher 查询时,他将先编译为一个执行计划 (Execution Plan),该计划可以运行并响应查询。
为了给查询提供一个高效的计划,Neo4j 需要数据库的信息,如模式的索引和约束;也需要统计信息来保持数据库优化执行计划,有了这些信息,就能决定采用哪种模式将获得最好的执行计划。
需要的统计信息如下:
- 拥有特定标签的节点的数量。
- 每个索引的可选择性。
- 按类型分的关系的数量。
- 以拥有指定标签的节点开始或者结束关系,按类型分各自的数量。
Neo4j 以两种方式来保持这些统计信息的更新。以标签数量为例,每当设置或者删除一个节点的标签的时候,这些数量都会被更新。Neo4j 需要扫描所有索引以获得可选择的数量。
配置选项
当产生执行计划的统计信息发生变化时,缓存的执行计划将被重新生成。下面的配置项可以控制执行计划的更新。
dbms.index_sampling.background_enabled
控制当需要更新时索引是否会自动重新采样。Cypher查询计划依赖于准确的统计信息来创建执行计划,因此当数据库更新时保持同步是很重要的。dbms.index_sampling.update_percentage
控制多大比例的索引被更新后才触发新的采样。cypher.statistics_divergence_threshold
控制一个执行计划被认为过时并必须重新生成前,允许多少统计信息发生变化。任何统计信息的相对变化超过临界值,原有执行计划将被丢弃并创建一个新的计划。
手动索引采样
索引重采样可使用内嵌的 db.resampleIndex() 和 dbms.resampleOutdateIndexes() 两个内嵌过程来触发。
1 | cypher-shell 'CALL db.resampleIndex(":Person(name)");' |
引用
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!