引入
在之前的学习中,大致明白了 Neo4j 的基本操作、程序开发、数据库管理等操作,对于一些基本的操作已经足够,而现在则是通过一些高级的使用来探索其他功能的启发。
高级索引
主要介绍空间索引和中文全文索引两个部分。
空间索引
空间索引的程序库是 Neo4j Spatial,他的主要作用是对数据进行空间操作,开发人员可以向已经具有位置信息的数据添加空间索引,并且对数据进行空间计算操作。另外 Neo4j Spatial 提供了数据导入 GeoTools (Java 编写的开源 GIS 工具包),从而启用 GeoTools 的应用程序,比如 GeoServer (共享空间地理数据的开源服务器)和 uDig (开源地理桌面数据访问、编辑、呈现框架)。
Neo4j Spatial 的主要功能包括:
- 可以将
RESI Shapefile (SHP)和Open Street Map (OSM)文件导入Neo4j的应用程序。 - 支持常见的几何图形:点、线、多边形等。
- 用于快速搜索几何形状的
RTree结构。 - 支持搜索期间的拓扑操作(包含、属于、相交、覆盖等)。
- 只要提供从图形映射到几何形状的适配器,就可以对任何图形进行空间操作,而不负责其数据的存储方式。
- 能够使用预配置的过滤器将单个图层或数据拆分成多个之图层或视图。
基本使用
使用 Neo4j Spatial 最简单的方法就是获取 neo4j-spatial-*.**-neo4j-*.*.*-server-plugin,然后将其复制到 plugin 目录下,重新启动 Neo4j 服务即可使用。
使用 Cypher 查询一样调用 Neo4j 空间过程,为节点添加空间索引,并且执行多个空间点的距离、交叉查询等操作。
1 | // 创建 geom 的点图层 |
原理
Neo4j 空间索引是 RTree 索引,它是以扩展的方式开发的,允许在必要的时候添加其他索引。空间索引可以在数据生成的过程中添加,也可以为现有的空间数据添加索引,并且实际上可以导致不同的图结构。
需要在数据生产的过程中添加索引,最简单的方法就是创建合适的数据图层,最常用的两种:
SimplePointLayer:一个可编辑的数据图层,仅允许向数据库添加点数据。Editablelayer(Impl):默认的可编辑图层实现,可以处理任何简单的集合类型。存储格式为WKB,专门用于几何地理的二进制格式。
定义几何图形的集合叫图层,其中包含可用于查询的索引,如果在图层中添加和修改图形,则这个图层就是可编辑图层。
空间索引查询类型
RTree 索引可以实现的查询方式有:
- 包含(
Contian)。 - 覆盖(
Cover)。 - 被覆盖(
Covered By)。 - 交叉(
Cross)。 - 不相交(
Disjoint)。 - 相交(
Intersect)。 - 交叠(
Oberlap)。 - 接触(
Touch)。 - 包含(
Within)。 - 在一定距离内(
With Distance)。
Java 构建 Neo4j 空间索引
Neo4j 自带一个用于导入 ESRI Shapefile 数据的程序,ShapeFileImporter 将为每个导入的 Shapefile 创建一个新的图层,并将每个几何图形作为 WKB 存储在单个节点的单个属性中。
导入
shape文件
下面的代码将roads.shp导入到layer_roads图层中。1
2
3
4
5
6
7
8
9File storeDir = new File(dbPath);
GraphDatabaseService database = new GraphDatabaseFactory().newEmbeddedDatabase(storeDir);
try (Transaction tx = database.beginTx()) {
ShapefileImporter importer = new ShapefileImporter(database);
importer.importFile("roads.shp", "layer_roads");
tx.success();
} finally {
database.shutdown();
}使用
Neo4j Spatial过程调用,可以达到同样的效果1
2CALL spatial.addWKTLayer('layer_roads', 'geometry')
CALL spatial.importShapefileToLayer('layer_roads', 'roads.shp')导入开放街道地图文件(
OSM)
导入OSM文件要比SHP文件复杂很多,因为导入OSM文件需要分两个过程进行,而第一个过程需要批处理导入。1
2
3
4
5
6
7
8
9
10
11
12
13
14File dir = new File(dbPath);
// 设置图层名称
OSMImporter importer = new OSMImporter("OSM");
// 批量导入配置
Map<String, String> config = new HashMap<String, String>();
config.put("neostore.nodestore.db.mapped_memory", "90M");
config.put("dump_configuration", "true");
config.put("use_memory_mapped_buffers", "true");
BatchInserter batchInserter = new BatchInserterImpl(dir, config);
importer.importFile(batchInserter, "map.osm", false);
BatchInserter.shutdown();
GraphDatabaseService db = new GraphDatabaseFactory().newEmbeddedDatabase(dir);
importer.reIndex(db, 10000);
db.shutdown();
常见的 Cypher 查询
WithinDistance查询WithinDistance查询是空间查询中最常用的一种方式,使用的是球面距离,计算采用OrthodromicDistance算法。1
start n = node:geom('WithinDistance:[21.331937, 120.638154, 0.1]') return n limit 10
WithinWKTGeometry查询
查询由点(120.678966, 31.300864)与点(120.978966, 31.330864)构成的Ploygon多边形范围内的点1
start n = node.geoindex('WithinWKTGeometry:PLOYGON ((120.678966, 31.300864, 120.978966, 31.330864, 120.978966, 31.300864, 120.678966, 31.300868))') return n limit 10
bbox矩形查询
查询由点(120.678966, 31.300864)与点(120.978966, 31.330864)构成的BBox矩形范围内的点1
start n = node.geom('bbox:[120.678966, 120.978966, 31.300864, 31.330864]') return n limit 10
中文全文索引
Neo4j 也提供了全文索引机制,并且是基于 Lucene 实现的,但是在默认情况下 Lucene 只提供了基于英文的分词器,如果将之用于中文,则会将中文分割成单个的字,这样就破坏了中文的语义结构,而且针对特定领域的中文分词,可能还需要自定义词典。
IKAnalyzer 分词器
IKAnalyzer 是一个开源的、基于 Java 开发的轻量级中文分词工具包,但是目前官方仅支持 Luence 3.0 版本。
基本使用
自定义词典
词典文件:自定义词典文件后缀名为.dic的词典文件,必须使用UTF-8编码保存。
词典配置:IKAnalyzer.cfg.xml必须在src目录下。词典文件可以放置在任意位置,但是在配置文件中必须配置正确。1
2
3
4
5
6
7
<properties>
<commnet>IK Analyzer 扩展配置</commnet>
<entry key="ext_dict">ext.dic;</entry>
<entry key="ext_stopwords">stopwords.dic;</entry>
</properties>嵌入式模式下的中文全文索引
指定IKAnalyzer作为Luence分词的Analyzer,并对一个Label下的所有Node指定属性新建全文索引。1
2
3
4
5
6
7
8
9
10
11
12try (Transaction tx = database.beginTx()) {
Map<String, String> config = new stringMap(IndexManager.PROVIDER, "luence", "type", "fulltext", "analyzer", IKAnalyzer.class.getName());
IndexManager index= database.index();
Index<Node> newFullTextIndex = index.forNodes("FullTextIndex", config);
ResourceIterator<Node> nodes = database.findNodes(DynamicLabel.label(LabelName));
while (nodes.hasNext()) {
Node node = nodes.next();
Object text = node.getProperty("text", null);
newFullTextIndex.add(node, "text", text);
}
tx.success();
}
Docker 部署 Neo4j
概览
默认情况下 Neo4j 的镜像开放了三个用于远程访问的端口:
7474用于HTTP协议。7473用于HTTPS协议。7687用于BOLT协议。
此外还指定了两个位置用于存放数据文件和日志文件:
/data用于数据库在容器的外部持久化。/logs用于允许访问Neo4j的日志文件。
在 Docker 中运行 Neo4j:
1 | docker run --publish=7474:7474 --publish=7687:7687 --volume=$HOME/neo4j/data:/data --volume=$HOME/neo4j/logs:/logs neo4j:3.1 |
可通过 -env NEO$J_AUTH=neo4j/<password> 指令设置容器的登录密码。
配置
有三种方式可以修改 Neo4j 容器的配置:
- 设置环境变量。
- 指定
/conf存储位置。 - 构建新的镜像。
环境变量
NEO4J_AUTH:控制身份验证。NEO4J_dbms_memory_pagecache_size:本地内存缓存的大小。NEO4J_dbms_memory_heap_maxSize:堆大小。NEO4J_dbms_txLog_rotation_retentionPolicy:保留逻辑日志的大小。NEO4J_dbms_allowFormatMigration:是否启用升级。NEO4J_dbms_mode:数据库模式。NEO4J_causalClustering_expectedCoreClusterSize:启动时的集群初始大小。NEO4J_causalClustering_initialDiscoveryMembers:集群核心成员的初始网络地址/端口号。NEO4J_causalClustering_discoveryAdvertisedAddress:成员发现地址/端口号。NEO4J_causalClustering_transactionAdvertisedAddress:广播事务处理地址/端口号。NEO4J_causalClustering_raftAdvertisedAddress:广播集群通信地址/端口号。NEO4J_ha_serverId:服务器的唯一标识。NEO4J_ha_host_corrdination:HA模式下集群协调通信的地址。NEO4J_ha_host_data:HA模式下用于数据传输的地址。NEO4J_ha_initialHosts:集群的其他成员的地址/端口列表。
/conf配置文件配置/conf中的配置都会覆盖镜像中的配置文件,包括已经生效的、为容器提供环境变量。如果要修改文件中的一个值则必须保证其他部分都是正确的。1
docker run --detach --publish=7474:7474 --publish=7687:7687 --volume=$HOME/neo4j/data:/data --volume=$HOME/neo4j/logs:/logs --volume=$HOME/neo4j/conf:/conf neo4j:3.1
因果集群
每个容器必须有一个与其他容器通信的网路路由,核心服务器必须要设置NEO4J_causalClustering_initialDiscoveryMembers和NEO4J_causalClustering_scpectedCoreClusterSize,而只读副本则只需要设置NEO4J_causalClustering_initialDiscoveryMembers。1
2
3
4
5
6
7docker network create --driver=bridge cluster
docker run --name=core1 --detach --network=cluster --publish=7474:7474 --publish=7687:7687 --env=NEO4J_dbms_mode=CORE --env=NEO4J_causalClustering_scpectedCoreClusterSize=3 \
--env=NEO4J_causalClustering_initialDiscoveryMembers=core1:5000,core2:5000.core3:5000 neo4j:3.1-enterprise
docker run --name=core2 --detach --network=cluster --env=NEO4J_dbms_mode=CORE --env=NEO4J_causalClustering_scpectedCoreClusterSize=3 \
--env=NEO4J_causalClustering_initialDiscoveryMembers=core1:5000,core2:5000.core3:5000 neo4j:3.1-enterprise
docker run --name=core3 --detach --network=cluster --env=NEO4J_dbms_mode=CORE --env=NEO4J_causalClustering_scpectedCoreClusterSize=3 \
--env=NEO4J_causalClustering_initialDiscoveryMembers=core1:5000,core2:5000.core3:5000 neo4j:3.1-enterprise高可用性集群
运行高可用性集群则每个容器必须具有可以连接到其他容器的网络路由NEO4J_ha_host_corrdination和NEO4J_ha_host_data和NEO4J_ha_initialHosts。1
2
3
4
5
6
7
8
9
10docker network create --driver=bridge cluster
docker run --name=instance1 --detach --network=cluster --hostname=instance1 --publish=7474:7474 --publish=7687:7687 --volume=$HOME/neo4j/logs:/logs --env=NEO4J_dbms_mode=CORE \
--env=NEO4J_ha_host_corrdination=HA --env=NEO4J_ha_serverId=1 --env=NEO4J_ha_host_corrdination=insatnce1:5001 --env=NEO4J_ha_host_data=instance1:6001 \
--env=NEO4J_ha_initialHosts=instance1:5001,instance2:5001,instance3:5001 neo4j:3.1-enterprise
docker run --name=instance2 --detach --network=cluster --hostname=instance2 --publish=7474:7474 --publish=7687:7687 --volume=$HOME/neo4j/logs:/logs --env=NEO4J_dbms_mode=CORE \
--env=NEO4J_ha_host_corrdination=HA --env=NEO4J_ha_serverId=2 --env=NEO4J_ha_host_corrdination=insatnce2:5001 --env=NEO4J_ha_host_data=instance2:6001 \
--env=NEO4J_ha_initialHosts=instance1:5001,instance2:5001,instance3:5001 neo4j:3.1-enterprise
docker run --name=instance3 --detach --network=cluster --hostname=instance3 --publish=7474:7474 --publish=7687:7687 --volume=$HOME/neo4j/logs:/logs --env=NEO4J_dbms_mode=CORE \
--env=NEO4J_ha_host_corrdination=HA --env=NEO4J_ha_serverId=3 --env=NEO4J_ha_host_corrdination=insatnce3:5001 --env=NEO4J_ha_host_data=instance3:6001 \
--env=NEO4J_ha_initialHosts=instance1:5001,instance2:5001,instance3:5001 neo4j:3.1-enterprise使用
Cypher-ShellCypher-Shell可以在容器内使用以下命令在本地运行:1
docker exec --interactive --tty <container> bin/cypher-shell
Neo4j 与图计算
Apache Spark 是一种集群内数据处理的解决方案,可以轻松地在多个机器上进行大规模数据处理,此外还有 GraphX 和 GraphFrames 两个框架,可以专门用于对数据进行图计算操作。Spark 可以与 Neo4j 搭配进行外部数据处理解决方案,处理过程如下:
- 所需要分析的子图从
Neo4j导出到Spark。 - 利用
Spark集群进行图计算。 - 将计算结果返回到
Neo4j中。 - 用
Cypher语言或者其他操作工具进行查询。
Neo4j-Spark-Connector
Neo4j-Spark-Connector 使用二进制 Bolt 协议从 Neo4j 中导入和导出数据,同时提供了 Spark-2.0 的 RDD、DataFrame、GraphX Graph 和 GraphFrames 等,可以自由地选择如何使用 Spark 处理数据。
一般的分析过程如下:
- 创建
org.neo4j.spark.Neo4j(sc)。 - 设置
cypher(query, [params], nodes(query, [params]), rels(query, [params])作为直接查询或者pattern("Label", Seq("REL"), "Label2")或pattern(("Label1", "prop1"), ("REL", "prop"), ("Label2", "prop2"))。 - 为并行计算定义
partitions(n), batch(size), rows(count)。 - 选择返回的数据类型。
loadRowRdd, loadNodeRdds, loadRelRdd, loadRdd[T]loadDataFrame, loadDataFrame(schema)loadGraph[VD, ED]loadGraphFrame[VD, ED]
下面实现一个简单地从 Neo4j 中加载数据并且使用 Spark 分析的流程:
在
Neo4j中添加数据1
2
3
4
5
6UNWIND range(1, 100) as id
CREATE (p:Person {id: id}) WITH collect(p) as people
UNWIND people as p1
UNWIND range(1, 10) as friend
WITH p1, people[(p1.id + friend) % size(people)] as p2
CREATE (p1)->[:KNOWS {years: abs(p2.id - p1.id)}]->(p2)在
Spark中配置Neo4j的连接方式1
2
3spark.neo4j.bolt.url = bolt://<host>:<port>
spark.neo4j.bolt.user = <username>
spark.neo4j.bolt.password = <password>打开
Spark添加jar包1
spark-shell --packages neo4j-contrib:neo4j-spark-connector:2.0.0-M2
如果还需要添加其他依赖的
jar包,在后面依次添加即可,用逗号分隔。加载数据转换为
Spark的RDD类型1
2
3
4
5
6
7
8
9
10
11
12
13import org.neo4j.spark._
val neo = Neo4j(sc)
val rdd = neo.cypher("MATCH (n:Person) RETURN id(n) as id").loadRowRdd
rdd.count // 1000
rdd.first.schema.fieldNames // ["id"]
rdd.first.schema("id") // StructField(id, LongType, true)
neo.cypher("MATCH (n:Person) WHERE n.id <= {maxId} RETURN n.id").param("maxId", 10).loadRowRdd.count // 10
// 设置分区和批处理大小
neo.nodes("MATCH (n:Person) RETURN id(n) SKIP {_skip} LIMIT {_limit}").partitions(4).batch(25).loadRowRdd.count // 100 == 4 * 25
// 通过 pattern 加载数据
neo.pattern("Person", Seq("KNOWS"), "Person").rows(80).batch(21).loadNodeRdds.count // 80
// 通过 pattern 加载关系
neo.pattern("Person", Seq("KNOWS"), "Person").partitions(12).batch(100).loadRelRdds.count // 1000加载数据转换为
Spark的DataFrame类型1
2
3
4import org.neo4j.spark._
val neo = Neo4j(sc)
neo.nodes("MATCH (n:Person) RETURN id(n) as id SKIP {_skip} LIMIT {_limit}").partitions(4).batch(25).loadDataFrame.count
var df = neo.pattern("Person", Seq("KNOWS"), "Person").rows(12).batch(100).loadDataFrame // [id: gigint]加载数据转换为
Spark的GraphX Graph类型1
2
3
4
5
6
7
8
9
10
11
12import org.neo4j.spark._
import org.apache.spark.graphx._
import org.apache.spark.graphx.lib._
val neo = Neo4j(sc)
val graphQuery = "MATCH (n:Person)-[:KNOWS]-(m:Person) RETURN id(n) as source, id(m) as target, type(r) as value SKIP {_skip} LIMIT {_limit}"
val graph: Graph[Long, String] = neo.rels(graphQuery).partitions(7).batch(200).loadGraph
graph.vertices.count // 100
graph.edges.count // 1000
// 通过 pattern 加载 graph
val graph = neo.patttern(("Person", "id"), ("KNOWS", "since"), ("Person". "id")).partitions(7).batch(200).loadGraph[Long, Long]
val graph2 = PageRank.run(graph, 5)
graph2.vertices.sort(_._2).take(3)加载数据转换为
Spark的GraphFrames类型1
2
3
4
5
6
7
8
9
10import org.neo4j.spark._
import org.graphframes._
val neo = Neo4j(sc)
val graphFrame = neo.pattern(("Person", "id"), ("KNOWS", null), ("Person". "id")).partitions(3).rows(1000).loadGraphFrame
graphFrame.vertices.count // 100
graphFrame.edges.count // 1000
val pageRankFrame = graphFrame.pageRank.maxIter(5).run()
val ranked = pageRankFrame.vertices
ranked.printSchema()
val top3 = ranked.orderBy(ranked.col("pagerank").desc).take(3)
Neo4j 与自然语言处理
自然语言处理技术在挖掘文本数据时使用的关键技术之一是本体的挖掘词关联。词关联在语言处理标记、解析、实体提取等自然语言处理任务中非常有用,Neo4j 由于其关联数据的能力,为自然语言处理中词关联的处理提供了一种新的解决方案。
在自然语言中最常见的词关联就是聚合关系和组合关系。
计算聚合相关性
计算聚合关系的基本步骤分为三步:
- 通过一个单词的上下文表示每个单词。
考虑一个简单的文档,其中包含这样的单词:至此要分析两个词之间是否存在关联,那就需要使用一定的方法来表示给定单词的上下文。1
2My cat eats fish on Saturday.
His dog eats turkey on Tuesday.1
2Right1("cat") = {"eats", "ate", "is", "has", ...}
Left1("cat") = {"my", "his", "big", "a", "the", ...} - 计算上下文相关性
为了计算聚合关系的度量,可以采用相对上下文相似性的和来表示,使用Jaccard指数作为相似性的度量。1
Sim("Cat", "Dog") = Sim(Left1("Cat"), Left1("Dog")) + Sim(Right1("Cat"), Right1("Dog"))
- 具有上下文高度相似性的词可能具有聚合关系
一旦有了这种计算相似度的方式,就可以寻找具有高相似度的词对。其中可以通过扩大上下文窗口的大小,处理停止词来调整相似性得分。
将文本数据建模为邻接图
可以将文本数据建模为邻接图,其中每个单词是一个节点,两个节点之间的边表示这些单词在文本语料库中彼此相邻。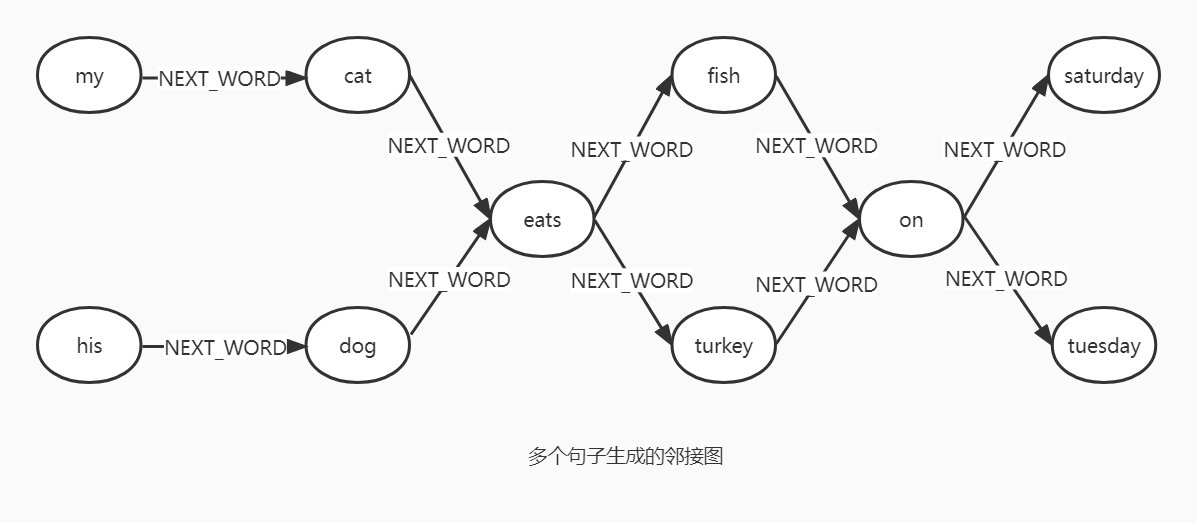
挖掘单词之间的关系
根据插入的数据来发现单词之间的关系。
1 | LEFT1_QUERY = 'MATCH (s:Word {word: {word}}) MATCH (w:Word)-[:NEXT_WORD]->(s) RETURN w.word as word' |
通过上面的代码我们就可以计算单词之间的相似性:
1 | paradingSimilarity("school", "university") // 0.2153846153846154 |
引用
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!