简介
NoSQL
NoSQL 是一项全新的数据库革命性运动,早期就有人提出,发展至2009 年趋势越发高涨。
NoSQL 的拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
NoSQL 指的是非关系型的数据库。NoSQL有时也称作Not Only SQL 的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL 用于超大规模数据的存储。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
CAP 定理(CAP theorem)
在计算机科学中,CAP 定理又被称为布鲁尔定律,他指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性: 所有节点在同一时间具有相同的数据。
- 可用性: 保证每个请求不管成功或者失败都有响应。
- 分隔容忍: 系统中任意信息的丢失或失败不会影响系统的继续运行。
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据CAP 原理将NoSQL 数据库分成了满足CA 原则、满足CP 原则和满足AP 原则三大类。
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展上不太强大。
- CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求比较低一点。
NoSQL 的优点/缺点
优点:
- 高可扩展性
- 分布式计算
- 低成本
- 架构的灵活,半结构化数据
- 没有复杂的关系
缺点:
- 没有标准化
- 有限的查询功能
- 最终一致性是不直观的程序
NoSQL 分类
列存储: HBase、Cassandra
文档存储: MongoDB、CouchDB
key-value: MemcacheDB、redis
图存储: Neo4J、FlockDB
对象存储: db4o、Versant
MongoDB
MongoDB 是由C++ 语言编写的,是一个基于分布式文件存储的开源数据库系统。在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。
MongoDB 文档类似于JSON 对象。字段值可以包含其他文档,数组及文档数组。
特点
- MongoDB是一个面向文档存储的数据库,操作起来比较简单和容易。
- 可以设置任意属性的索引,来支持更快的排序。
- MongoDB 支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- MongoDB 使用update() 命令可以实现替换完成的文档(数据)或者一些指定的数据字段。
- MongoDB 中的Map/reduce 主要是用来对数据进行批量处理和聚合操作。
- GridFS 是MongoDB 中的一个内置功能,可以用于存放大量小文件。
- MongoDB 允许在服务端执行脚本,可以用Javascript 编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
工具
- MongoHub – 适用于OSX的应用程序。
- ROBO 3T
基础
安装MongoDB
MongoDB 提供了可用于32 位和64 位系统的预编译二进制包,MongoDB 预编译二进制包下载地址:https://www.mongodb.com/download-center#community
下载完成后,点击对应的 .msi 文件,按照操作提示安装即可。
运行MongoDB 服务器
在运行之前需要先创建数据目录,在你的安装目录下创建一个data 的文件,之后就可以启动MongoDB 服务器了。
1 | D:\mongodb\bin\mongod.exe --dbpath D:\mongodb\data |
当你看见MongoDB starting 等字样的时候就说明已经启动成功了。
连接MongoDB
在命令行窗口中运行mongo.exe 就可以连接MongoDB 了。
1 | D:\mongodb\bin\mongo.exe |
概念解析
学习MongoDB 之前,需要想学习一下在MongoDB 中最基本的概念。
| SQL 术语/概念 | MongoDB 术语/概念 | 解释 |
|---|---|---|
| database | databse | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| userinfoumn | field | 数据字段域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB 不支持 | |
| primary key | primary key | 主键,MongoDB 自动将_id 设置为主键 |
通过下图实例,我们也可以更直观的了解Mongo 中的一些概念: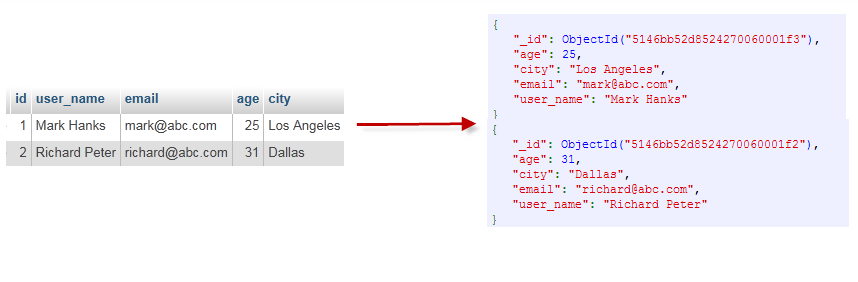
MongoDB 数据类型
| 数据类型 | 描述 |
|---|---|
| String | 字符串 |
| Integer | 整型数值 |
| Boolean | 布尔值 |
| Double | 双精度浮点值 |
| Min/Max keys | 将一个值与BSON 元素的最低值和最高值相对比 |
| Array | 用于数组或列表或多个值存储为一个键 |
| Timestamp | 时间戳 |
| Object | 内嵌文档 |
| Null | 创建空值 |
| Symbol | 符号 |
| Date | 日期时间 |
| Object ID | 对象ID |
| Binary Date | 二进制数据 |
| Code | 代码类型 |
| Regular expression | 正则表达式类型 |
Object ID
Objectid 类似于唯一主键,可以很快的去生成和排序,包含12bytes ,含义是:
- 前4 个字节表示创建unix 时间戳。(格林尼治时间)
- 接下来的3 个字节表示机器标识码。
- 紧接的2 个字节由进程id 组成PID 。
- 最后3 个字节是随机数。
由于Object ID 中包含时间戳,因此不需要在存储对应的文档保存时间,可以通过getTimestamp() 函数来获得文档的创建时间。
1 | > var newObject = ObjectId() |
Object ID 转为字符串:
1 | > newObject.str |
日期
1 | > var date1 = new Date() // 格林尼治时间 |
数据库操作
创建数据库
1 | > use testDatabase |
在MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
删除
1 | > show dbs |
集合操作
创建
1 | > use testDatabase |
插入
1 | > db.userinfo.insert({name: "test", age: 142, male: 1}) |
插入文档你也可以使用db.userinfo.save(document) 命令。如果不指定_id 字段save() 方法类似于insert() 方法。如果指定 _id 字段,则会更新该 _id 的数据。
更新
语法格式:
1 | db.userinfolection.update( |
实例:
1 | > db.userinfo.find() |
删除
语法格式:
1 | db.userinfolection.remove( |
删除文档:
1 | > db.userinfo.find() |
官方推荐方法:
1 | db.userinfolectionName.deleteOne() |
删除集合:
1 | > use testDatabase |
查询
1 | > db.userinfo.find() |
MongoDB 与RDBMS Where 语句比较:
| 操作 | 格式 | 范例 | RDBMS 中的类似语句 |
|---|---|---|---|
| 等于 | {< key>:< value>} | db.userinfo.find({“age”:”15”}).pretty() | where age = 15 |
| 小于 | {< key>:{$lt:< value>}} | db.userinfo.find({“age”:{$lt: 50}}).pretty() | where age < 15 |
| 小于或等于 | {< key>:{$lte:< value>}} | db.userinfo.find({“age”:{$lte: 50}}).pretty() | where age >= 15 |
| 大于 | {< key>:{$gt:< value>}} | db.userinfo.find({“age”:{$gt: 50}}).pretty() | where age > 15 |
| 大于或等于 | {< key>:{$gte:< value>}} | db.userinfo.find({“age”:{$gte: 50}}).pretty() | where age >= 15 |
| 不等于 | {< key>:{$ne:< value>}} | db.userinfo.find({“age”:{$ne: 50}}).pretty() | where age != 15 |
MongoDB AND OR 条件:
1 | > db.userinfo.find({key1:value1, key2:value2}).pretty() |
操作符
条件操作符用于比较两个表达式并从MongoDB 集合中获取数据。
$type 操作符
$type 操作符是基于BSON 类型来检索集合中匹配的数据类型,并返回结果。
MongoDB 中可以使用的类型如下:
| 类型 | 数字 | 备注 |
|---|---|---|
| Double | 1 | |
| String | 2 | |
| Object | 3 | |
| Array | 4 | |
| Binary data | 5 | |
| Undefined | 6 | 已废弃 |
| Object id | 7 | |
| Boolean | 8 | |
| Date | 9 | |
| Null | 10 | |
| Regular Expression | 11 | |
| JavaScript | 13 | |
| Symbol | 14 | |
| JavaScript (with scope) | 15 | |
| 32-bit integer | 16 | |
| Timestamp | 17 | |
| 64-bit integer | 18 | |
| Min key | 255 | Query with -1 |
| Max key | 127 |
1 | > db.userinfo.find({name : {$type: "string"}}) |
条件操作符
MongoDB 中条件操作符有:
- (>) 大于 - $gt
- (<) 小于 - $lt
- (>=) 大于等于 - $gte
- (<=) 小于等于 - $lte
1 | > db.userinfo.find({age: {$gt: 300}}) |
模糊查询:
1 | db.userinfo.find({name: /教/}) // 查询name 字段包含"教"字的文档 |
加强
分页
Limit() 基本语法:
1 | > db.COLLECTION_NAME.find().limit(NUMBER) |
Skip() 基本语法:
1 | > db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER) |
实例:
1 | > db.userinfo.find() |
排序
Sort() 基本语法:
1 | > db.COLLECTION_NAME.find().sort({KEY:1}) |
实例:
1 | > db.userinfo.find() |
索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
CreateIndex() 基本语法:
1 | > db.collection.createIndex(keys, options) |
实例:
1 | > db.userinfo.find() |
查看集合索引:
1 | > db.collection.getIndexes() |
查看集合索引大小:
1 | > db.collection.totalIndexSize() |
删除集合所有索引:
1 | > db.collection.dropIndexes() |
删除集合指定索引:
1 | > db.collection.dropIndex("索引名称") |
聚合
MongoDB 中聚合(aggregate )主要用于处理数据(诸如统计平均值、求和等),并返回计算后的数据结果。有点类似sql语句中的count(* )。
Aggregate() 方法:
1 | > db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION) |
实例:
1 | > db.userinfo.find() |
聚合的表达式:
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.userinfo.aggregate([{$group : {_id : “$name”, num_tutorial : {$sum : “$age”}}}]) |
| $avg | 计算平均值 | db.userinfo.aggregate([{$group : {_id : “$name”, num_tutorial : {$avg : “$age”}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.userinfo.aggregate([{$group : {_id : “$name”, num_tutorial : {$min : “$age”}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.userinfo.aggregate([{$group : {_id : “$name”, num_tutorial : {$max : “$age”}}}]) |
| $push | 在结果文档中插入值到一个数组中。 | db.userinfo.aggregate([{$group : {_id : “$name”, url : {$push: “$url”}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.userinfo.aggregate([{$group : {_id : “$name”, url : {$addToSet : “$url”}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.userinfo.aggregate([{$group : {_id : “$name”, first_url : {$first : “$url”}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据。 | db.userinfo.aggregate([{$group : {_id : “$name”, last_url : {$last : “$url”}}}]) |
管道
管道在Unix 和Linux 中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB 的聚合管道将MongoDB 文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。这里介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
实例:
1 | > db.userinfo.find() |
复制
MongoDB 复制是将数据同步在多个服务器的过程。
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
复制还允许从硬件故障和服务中断中恢复数据。
复制原理
MongoDB 的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
MongoDB 各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog ,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
结构图: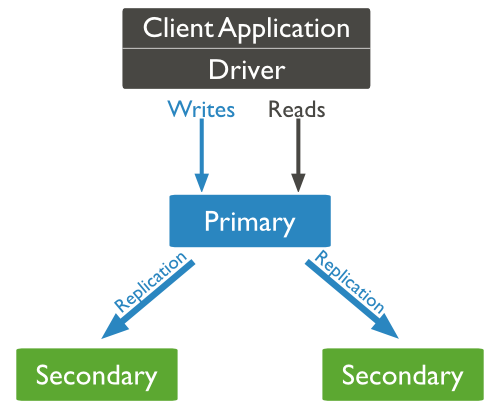
以上结构图中,客户端从主节点读取数据,在客户端写入数据到主节点时, 主节点与从节点进行数据交互保障数据的一致性。
副本集特征:
- N 个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复
具体的关于副本集的操作请查看官方文档。
分片
在MongoDB 里面存在另一种集群,就是分片技术,可以满足MongoDB 数据量大量增长的需求。
当MongoDB 存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
备份/恢复
在MongoDB 中我们使用mongodump 命令来备份MongoDB 数据。该命令可以导出所有数据到指定目录中。
mongodump 命令可以通过参数指定导出的数据量级转存的服务器。
mongorestore 命令来恢复备份的数据。
基本语法:
1 | > mongodump -h dbhost -d dbname -o dbdirectory |
- -h: MongDB所在服务器地址。
- -d: 需要备份的数据库实例。
- -o: 备份的数据存放位置。
实例:
1 | D:\mongodb\bin\mongodump.exe |
1 | > mongorestore -h <hostname><:port> -d dbname <path> |
- –host <:port>, -h <:port>: MongoDB所在服务器地址
- –db,-d: 需要恢复的数据库实例
- –drop: 恢复的时候,先删除当前数据,然后恢复备份的数据
- < path>: mongorestore 最后的一个参数,设置备份数据所在位置
- –dir:指定备份的目录
实例:
1 | D:\mongodb\bin\mongorestore.exe |
监控
在已经安装部署并允许MongoDB 服务后,必须要了解MongoDB 的运行情况,并查看MongoDB 的性能。这样在大流量得情况下可以很好的应对并保证MongoDB 正常运作。
MongoDB 中提供了mongostat 和 mongotop 两个命令来监控MongoDB 的运行情况。
mongostat 基本语法:
1 | D:\mongodb\bin\mongostat.exe |
mongostat 是MongoDB 自带的状态检测工具,在命令行下使用。它会间隔固定时间获取MongoDB 的当前运行状态,并输出。如果你发现数据库突然变慢或者有其他问题的话,你第一手的操作就考虑采用mongostat 来查看mongo 的状态。
mongotop 基本语法:
1 | D:\mongodb\bin\mongotop.exe |
mongotop 也是MongoDB 下的一个内置工具,mongotop 提供了一个方法,用来跟踪一个MongoDB 的实例,查看哪些大量的时间花费在读取和写入数据。 mongotop 提供每个集合的水平的统计数据。默认情况下,mongotop 返回值的每一秒。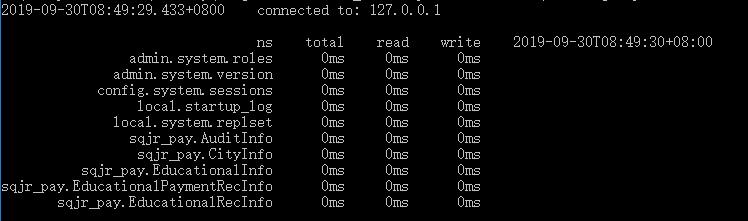
高级
关系
MongoDB 的关系表示多个文档之间在逻辑上的相互联系。
文档间可以通过嵌入和引用来建立联系。
MongoDB 中的关系可以是:
- 1 : 1 (1对1)
- 1 : N (1对多)
- N : 1 (多对1)
- N : N (多对多)
一个用户可以有多个地址,所以是一对多的关系。
user 文档的简单结构:
1 | { |
address 文档的简单结构:
1 | { |
嵌入式关系
使用嵌入式方法,我们可以把用户地址嵌入到用户的文档中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address": [
{
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
},
{
"building": "170 A, Acropolis Apt",
"pincode": 456789,
"city": "Chicago",
"state": "Illinois"
}
]
}查询用户的地址:
1
> db.users.findOne({"name":"Tom Benzamin"},{"address":1})
这种数据结构的缺点是,如果用户和用户地址在不断增加,数据量不断变大,会影响读写性能。
引用式关系
引用式关系是设计数据库时经常用到的方法,这种方法把用户数据文档和用户地址数据文档分开,通过引用文档的 id 字段来建立关系。1
2
3
4
5
6
7
8
9
10{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address_ids": [
ObjectId("52ffc4a5d85242602e000000"),
ObjectId("52ffc4a5d85242602e000001")
]
}这种方法需要两次查询,第一次查询用户地址的对象id(ObjectId),第二次通过查询的id获取用户的详细地址信息。
1
2> var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1})
> var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})
数据库引用
上一节中,提到了通过引用来规范数据结构文档。
MongoDB 中的引用共有两中:
- 手动引用
- DBRefs
DBRefs
DBRefs 的形式:
1 | {$ref: , $id: , $db: } |
三个字段表示的含义:
- $ref: 集合的名称
- $id: 引用的ID
- $db: 数据库名称(可选参数)
实例:
数据:
1 | { |
查询:
1 | > var user = db.users.findOne({"name":"Tom Benzamin"}) |
查询分析
MongoDB 查询分析常用函数由:
- explain()
- hint()
- explain()
explain() 操作提供了查询信息,使用索引及查询统计等。有利于我们对索引的优化。
使用explain() 函数:
1 | > db.users.find({gender:"M"},{user_name:1,_id:0}).explain() |
返回结果:
1 | { |
- hint()
在MongoDB 中可以使用hint() 来强制MongoDB 使用一个指定的索引。
实例:
1 | > db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1}) |
原子操作
在MongoDB 中并不支持事务,所以,在任何时候都不能要求MongoDB 保证数据的完整性。
但是与之对应的MongoDB 提供了许多原子操作。
原子操作常用命令:
$set: 用来指定一个键并更新键值,若不存在则创建。
1
{ $set : {field : value}}
$unset: 删除一个键
1
{ $unset : { field : 1} }
$inc: 对文档中某个值为数值型的键进行加减操作。
1
{ $inc : { field : value } }
$push: 将value 加入到field 中,field 一定要为数组类型,若field 不存在则创建数组并加进去。
1
{ $push : { field : value } }
$pushAll: 同$push ,一次可以添加多个进field 。
1
{ $pushAll : { field : value_array } }
$pull: 从数组field 中删除一个value 值。
1
{ $pull : { field : _value } }
$addToSet: 增加一个值到数组中,只有不存在时才会加入。
$pop: 删除数组的第一个或者最后一个元素。
1
{ $pop : { field : 1 } }
$rename: 修改字段名称。
1
{ $rename : { old_field_name : new_field_name } }
$bit: 位操作。
1
{$bit : { field : {and : 5}}}
偏移操作符:
1
2
3> t.find() { "_id" : ObjectId("4b97e62bf1d8c7152c9ccb74"), "title" : "ABC", "comments" : [ { "by" : "joe", "votes" : 3 }, { "by" : "jane", "votes" : 7 } ] }
> t.update( {'comments.by':'joe'}, {$inc:{'comments.$.votes':1}}, false, true )
> t.find() { "_id" : ObjectId("4b97e62bf1d8c7152c9ccb74"), "title" : "ABC", "comments" : [ { "by" : "joe", "votes" : 4 }, { "by" : "jane", "votes" : 7 } ] }
正则表达式
正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。
MongoDB 使用 $regex 操作符来设置匹配字符串的正则表达式。
MongoDB 使用PCRE (Perl Compatible Regular Expression) 作为正则表达式语言。
使用正则表达式:
1 | > db.posts.find({post_text:{$regex:"runoob"}}) |
MongoDB GridFS
GridFS 用于存储和恢复那些超过16M(BSON文件限制)的文件(如:图片、音频、视频等)。
GridFS 也是文件存储的一种方式,但是它是存储在MonoDB 的集合中。
GridFS 会将大文件对象分割成多个小的chunk (文件片段),一般为256k/个,每个chunk将作为MongoDB 的一个文档(document)被存储在chunks 集合中。
GridFS 用两个集合来存储一个文件:fs.files 与fs.chunks 。
示例:
简单的fs.files 集合文档:
1 | { |
简单的fs.chunks 集合文档:
1 | { |
技巧与案例
SQL Java 实战
查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21Query query = new Query();
Criteria criteria = new Criteria();
// 添加筛选条件
criteria.and("userId").is("1");
// 添加非空筛选条件
if(null != param.get("pageSize") && null != param.get("startRows")) {
int pageSize = Integer.parseInt(param.get("pageSize"));
int startRows = Integer.parseInt(param.get("startRows"));
query.skip(startRows).limit(pageSize);
}
// 排序
query.with(new Sort(new Order(Direction.DESC, "createTime")));
// 范围区间取值
query.addCriteria(criteria).addCriteria(Criteria.where("commNo").in(commNos));
// 执行查询
mongoTemplate.find(query, UserInfo.class);计数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Query query = new Query();
Criteria criteria = new Criteria();
// 加入非空计数条件
if (null != userId && !"".equals(userId)){
criteria.and("userId").is(userId);
}
// 正则表达式计数
Pattern pattern = Pattern.compile("^.*" + name + ".*$");
query.addCriteria(Criteria.where("name").regex(pattern));
// 执行查询
query.addCriteria(criteria);
mongoTemplate.count(query, UserInfo.class);
引用
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!