前言
今天在回顾之前做的支付的部分代码的时候,突然间发现了一个问题,那就是循环依赖。
代码本身没有报错,系统也可以正常运行,但是对于理解这一块的业务来说不是很容易,所以准备仔细来看看这一块的东西。
简介
循环依赖
循环依赖其实就是循环引用,也就是两个或者两个以上的Bean 互相持有对方,最终形成闭环。 这里有点类似于死锁的意思。
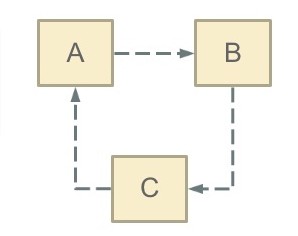
注意,这里不是函数的循环调用,是对象的相互依赖关系。 循环调用其实就是一个死循环,除非有终结条件。
Spring中循环依赖场景有:
- 构造器的循环依赖。
- field属性的循环依赖。
其中,构造器的循环依赖问题无法解决,只能拋出BeanCurrentlyInCreationException 异常; 但是在解决属性循环依赖时,Spring 采用的是提前暴露对象的方法。
而我这次遇到的循环依赖问题就是field 属性的循环依赖。
循环依赖的产生和解决
循环依赖的产生可能有很多种情况:
- A的构造方法中依赖了B的实例对象,同时B的构造方法中依赖了A的实例对象。
- A的构造方法中依赖了B的实例对象,同时B的某个field或者setter需要A的实例对象,以及反之。
- A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象,以及反之。
对于如何解决循环依赖这种问题,首先前提条件就是针对scope 单例并且没有显式指明不需要解决循环依赖的对象,而且要求该对象没有被代理过。但是这种解决办法也不是万能的,对于第一种产生循环依赖的情况就无法解决,究其本质就是Spring 本身就是属于单例的模式,其官方也说明了无法修改,只能修改自己的代码了。
解决原理
Spring 循环依赖的理论依据其实是Java 基于引用传递,当我们获取到对象的引用时,对象的field 或者属性是可以延后设置的。
Spring单例对象的初始化其实可以分为三步:
- createBeanInstance: 实例化,实际上就是调用对应的构造方法构造对象,此时只是调用了构造方法,spring xml 中指定的property 并没有进行populate 。
- populateBean: 填充属性,这步对spring xml 中指定的property 进行populate 。
- initializeBean: 调用spring xml 中指定的init方法,或者AfterPropertiesSet方法会发生循环依赖的步骤集中在第一步和第二步。
三级缓存
对于单例对象来说,在Spring 的整个容器的生命周期内,有且只存在一个对象,很容易想到这个对象应该存在Cache 中,Spring 大量运用了Cache 的手段,在循环依赖问题的解决过程中使用了三级缓存。
1 | /** Cache of singleton objects: bean name --> bean instance */ |
以上的三个cache 构成了三级缓存,而Spring 就是用这三级缓存巧妙的解决了循环依赖问题。
三级缓存流程
在创建Bean 的时候,首先想到的是从cache 中获取这个单例的Bean ,这个缓存就是singletonObjects 。如果获取不到,并且对象正在创建中,就再从二级缓存earlySingletonObjects 中获取,如果还是获取不到且允许singletonFactories 通过getObject() 获取,就从三级缓存singletonFactory.getObject() (三级缓存)获取。如果获取到了,则从singletonFactories 中移除,并放入earlySingletonObjects 中,其实也就是从三级缓存移动到了二级缓存。
从上面三级缓存的分析,我们可以知道,Spring 解决循环依赖的诀窍就在于singletonFactories 这个三级cache 。这个cache 的类型是ObjectFactory 。这里就是解决循环依赖的关键,发生在createBeanInstance 之后,也就是说单例对象此时已经被创建出来(调用了构造器)。这个对象已经被生产出来了,虽然还不完美(还没有进行初始化的第二步和第三步),但是已经能被人认出来了(根据对象引用能定位到堆中的对象),所以Spring 此时将这个对象提前曝光出来让大家认识,让大家使用。
这样做有什么好处呢?让我们来分析一下A的某个field 或者setter依赖了B 的实例对象,同时B 的某个field 或者setter 依赖了A 的实例对象这种循环依赖的情况。
A 首先完成了初始化的第一步,并且将自己提前曝光到singletonFactories 中,此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B) ,发现B 还没有被create ,所以走create 流程,B 在初始化第一步的时候发现自己依赖了对象A ,于是尝试get(A) ,尝试一级缓存singletonObjects (肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories ,由于A 通过ObjectFactory 将自己提前曝光了,所以B 能够通过ObjectFactory.getObject 拿到A 对象(虽然A 还没有初始化完全,但是总比没有好呀),B 拿到A 对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects 中。
此时返回A 中,A 此时能拿到B 的对象顺利完成自己的初始化阶段2、3,最终A 也完成了初始化,进去了一级缓存singletonObjects 中,而且更加幸运的是,由于B 拿到了A 的对象引用,所以B 现在hold 住的A 对象完成了初始化。
知道了这个原理时候,肯定就知道为啥Spring不能解决A的构造方法中依赖了B的实例对象,同时B的构造方法中依赖了A的实例对象这类问题了!因为加入singletonFactories 三级缓存的前提是执行了构造器,所以构造器的循环依赖没法解决。
总结
Spring 通过三级缓存加上提前曝光机制,配合Java 的对象引用原理,比较完美地解决了某些情况下的循环依赖问题!
引用
https://blog.csdn.net/u010853261/article/details/77940767
后记
闲暇时间还是要多看看官方文档和源码,重点要理解其中的设计精髓和实现的方法,这对以后的进阶很有帮助。
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!