分布式锁简介
分布式锁的实现有哪些?
- Memcached 分布式锁
利用Memcached 的add 命令。此命令是原子性操作,只有在key 不存在的情况下,才能add 成功,也就意味着线程得到了锁。 - Redis 分布式锁
和Memcached 的方式类似,利用Redis 的setnx 命令。此命令同样是原子性操作,只有在key 不存在的情况下,才能set 成功。(setnx命令并不完善,后续会介绍替代方案) - Zookeeper 分布式锁
利用Zookeeper 的顺序临时节点,来实现分布式锁和等待队列。Zookeeper 设计的初衷,就是为了实现分布式锁服务的。 - Chubby
Google 公司实现的粗粒度分布式锁服务,底层利用了Paxos 一致性算法。
Redis 分布式锁
Redis 分布式锁的基本流程并不难理解,但要想写得尽善尽美,也并不是那么容易。在这里,我们需要先了解分布式锁实现的三个核心要素:
加锁
最简单的方法是使用setnx 命令。
key 是锁的唯一标识,按业务来决定命名。比如想要给一种商品的秒杀活动加锁,可以给key 命名为 “lock_sale_商品ID” 。而value设置成什么呢?我们可以姑且设置成1。
加锁的伪代码如下:
1 | setnx(key, 1) |
当一个线程执行setnx 返回1,说明key 原本不存在,该线程成功得到了锁。当一个线程执行setnx 返回0,说明key 已经存在,该线程抢锁失败。
解锁
有加锁就得有解锁。
当得到锁的线程执行完任务,需要释放锁,以便其他线程可以进入。
释放锁的最简单方式是执行del指令,伪代码如下:
1 | del(key) |
释放锁之后,其他线程就可以继续执行setnx命令来获得锁
锁超时
锁超时是什么意思呢?
如果一个得到锁的线程在执行任务的过程中挂掉,来不及显式地释放锁,这块资源将会永远被锁住,别的线程再也别想进来。
所以,setnx 的key 必须设置一个超时时间,以保证即使没有被显式释放,这把锁也要在一定时间后自动释放。
setnx 不支持超时参数,所以需要额外的指令,伪代码如下:
1 | expire(key, 30) |
综合起来,我们分布式锁实现的第一版伪代码如下:
1 | if(setnx(key, 1) == 1){ |
三大问题
setnx 和expire 的非原子性
设想一个极端场景,当某线程执行setnx,成功得到了锁: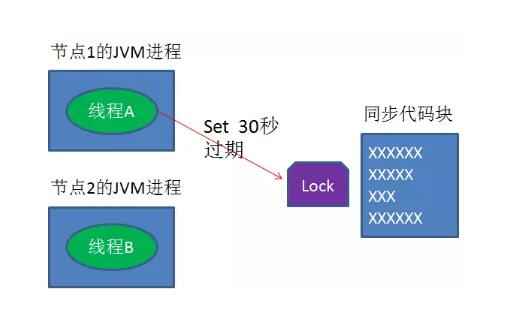
setnx刚执行成功,还未来得及执行expire指令,节点1 Duang的一声挂掉。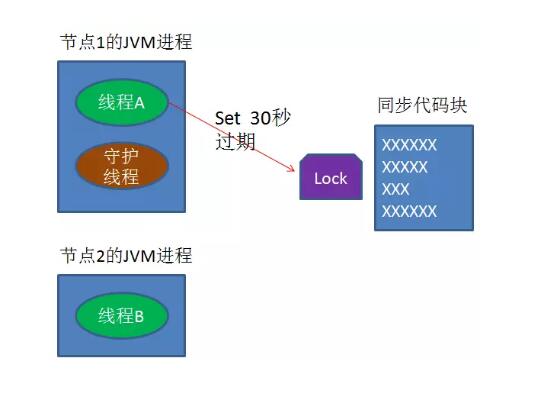
这样一来,这把锁就没有设置过期时间,变得“长生不老”,别的线程再也无法获得锁了。
怎么解决呢?
setnx 指令本身是不支持传入超时时间,幸好Redis 2.6.12以上版本为set 指令增加了可选参数,伪代码如下:
1 | set(key, 1, 30, NX) |
这样就可以取代setnx 指令。
del 导致误删
又是一个极端场景,假如某线程成功得到了锁,并且设置的超时时间是30秒。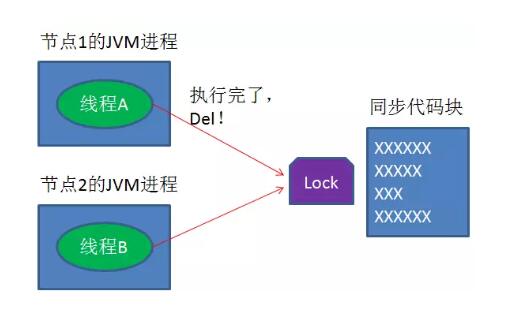
如果某些原因导致线程A执行的很慢很慢,过了30秒都没执行完,这时候锁过期自动释放,线程B得到了锁。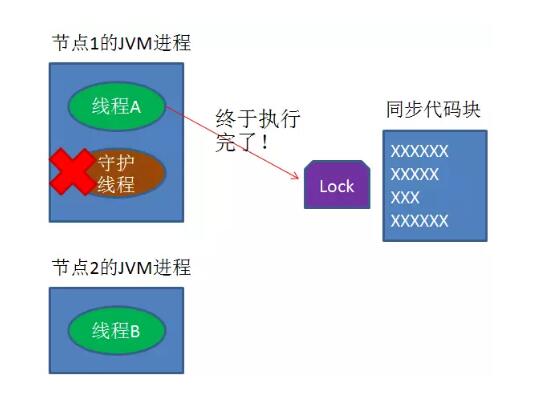
随后,线程A执行完了任务,线程A接着执行del指令来释放锁。但这时候线程B还没执行完,线程A实际上删除的是线程B加的锁。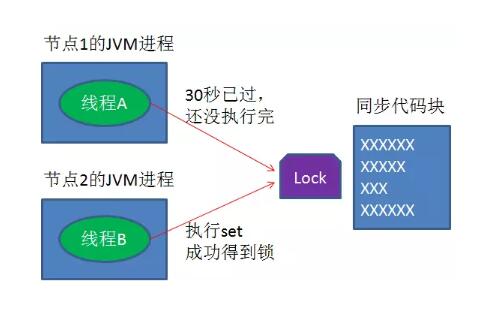
怎么避免这种情况呢?可以在del释放锁之前做一个判断,验证当前的锁是不是自己加的锁。
至于具体的实现,可以在加锁的时候把当前的线程ID 当做value ,并在删除之前验证key 对应的value 是不是自己线程的ID 。
加锁:
1 | String threadId = Thread.currentThread().getId() |
解锁:
1 | if(threadId .equals(redisClient.get(key))){ |
但是,这样做又隐含了一个新的问题,判断和释放锁是两个独立操作,不是原子性。
我们都是追求极致的程序员,所以这一块要用Lua脚本来实现:
1 | String luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end"; |
这样一来,验证和删除过程就是原子操作了。
出现并发的可能性
还是刚才第二点所描述的场景,虽然我们避免了线程A 误删掉key 的情况,但是同一时间有A,B两个线程在访问代码块,仍然是不完美的。
怎么办呢?我们可以让获得锁的线程开启一个守护线程,用来给快要过期的锁“续航”。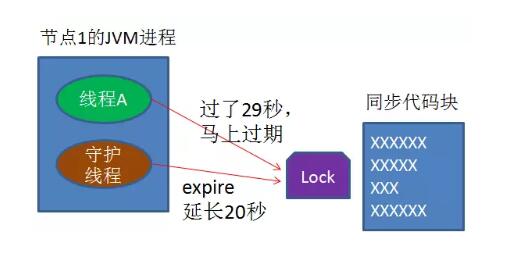
当过去了29秒,线程A还没执行完,这时候守护线程会执行expire指令,为这把锁“续命”20秒。
守护线程从第29秒开始执行,每20秒执行一次。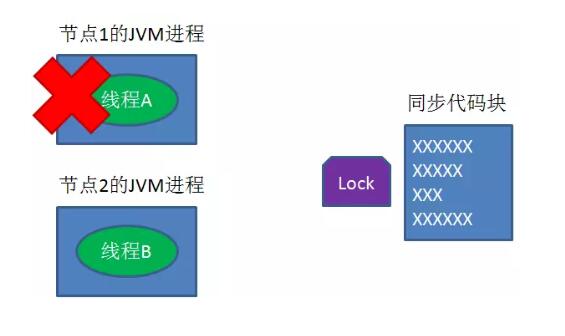
当线程A执行完任务,会显式关掉守护线程。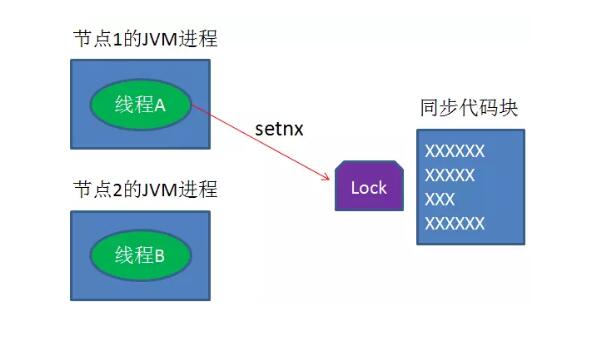
另一种情况,如果节点1 忽然断电,由于线程A和守护线程在同一个进程,守护线程也会停下。这把锁到了超时的时候,没人给它续命,也就自动释放了。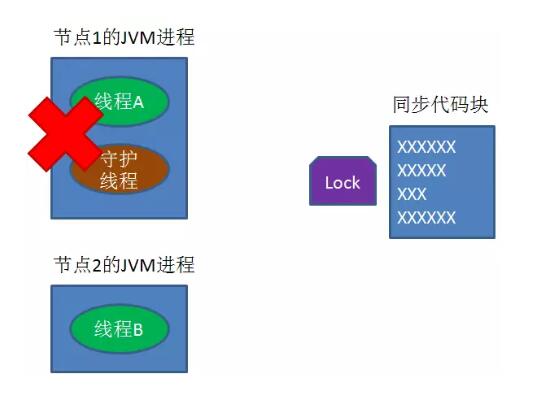
守护线程的代码并不难实现,有了大体思路,大家可以自己尝试实现一下。
Zookeeper 的临时顺序节点
持久节点
默认的节点类型。创建节点的客户端与Zookeeper 断开连接后,该节点依旧存在 。
顺序持久节点
所谓顺序节点,就是在创建节点时,Zookeeper 根据创建的时间顺序给该节点名称进行编号。
临时节点
和持久节点相反,当创建节点的客户端与Zookeeper 断开连接后,临时节点会被删除。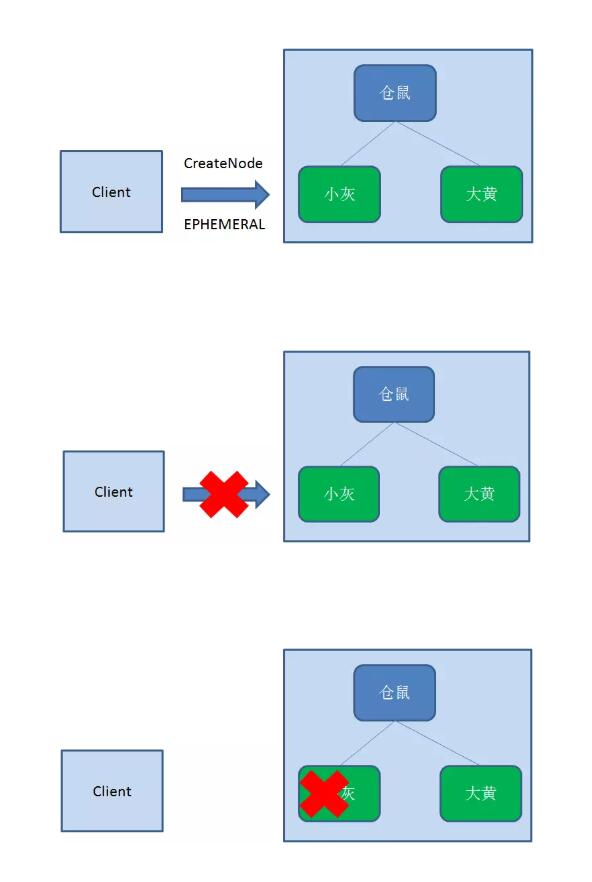
临时顺序节点
顾名思义,临时顺序节点结合和临时节点和顺序节点的特点:在创建节点时,Zookeeper 根据创建的时间顺序给该节点名称进行编号;当创建节点的客户端与Zookeeper 断开连接后,临时节点会被删除。
Zookeeper 分布式锁
Zookeeper分布式锁恰恰应用了临时顺序节点。具体如何实现呢?让我们来看一看详细步骤。
Zookeeper 获取锁原理
首先,在Zookeeper 当中创建一个持久节点ParentLock 。当第一个客户端想要获得锁时,需要在ParentLock 这个节点下面创建一个临时顺序节点Lock1。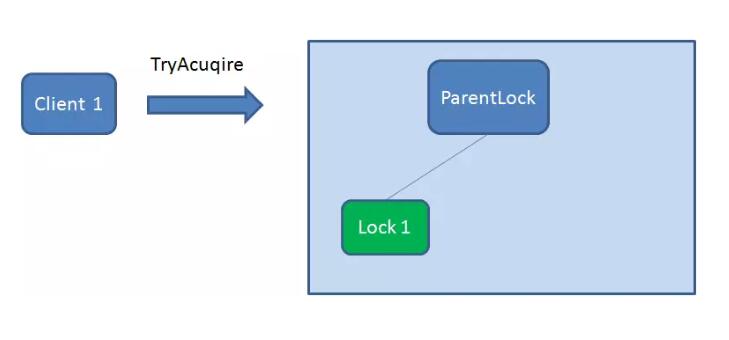
之后,Client1 查找ParentLock 下面所有的临时顺序节点并排序,判断自己所创建的节点Lock1 是不是顺序最靠前的一个。如果是第一个节点,则成功获得锁。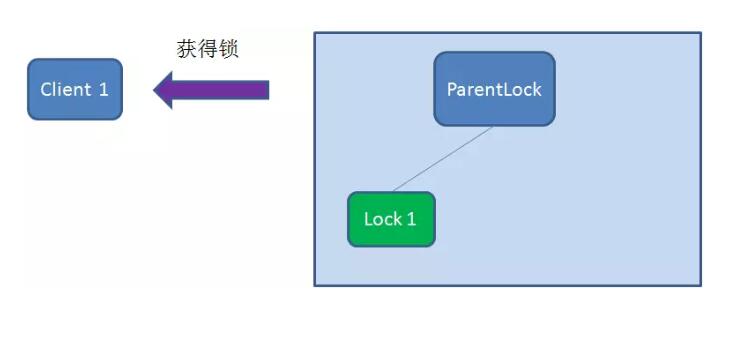
这时候,如果再有一个客户端Client2 前来获取锁,则在ParentLock 下载再创建一个临时顺序节点Lock2 。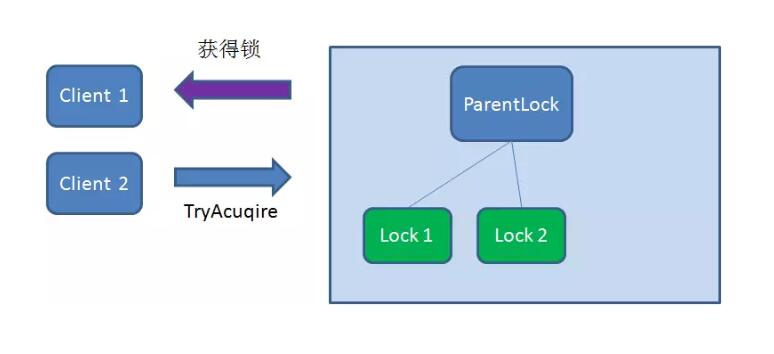
Client2 查找ParentLock 下面所有的临时顺序节点并排序,判断自己所创建的节点Lock2 是不是顺序最靠前的一个,结果发现节点Lock2 并不是最小的。
于是,Client2 向排序仅比它靠前一位的节点Lock1 注册Watcher ,用于监听Lock1 节点是否存在。这意味着Client2 抢锁失败,进入了等待状态。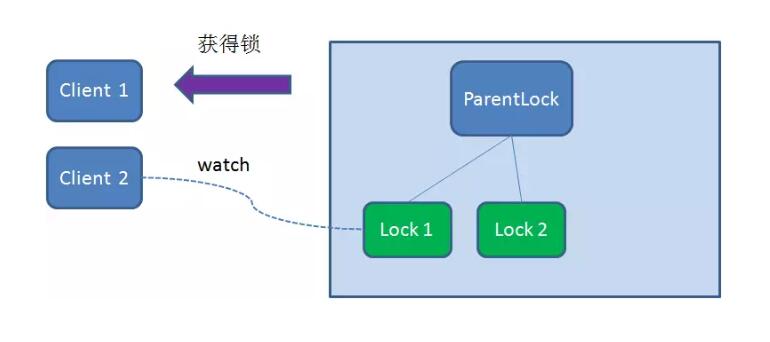
这时候,如果又有一个客户端Client3 前来获取锁,则在ParentLock 下载再创建一个临时顺序节点Lock3 。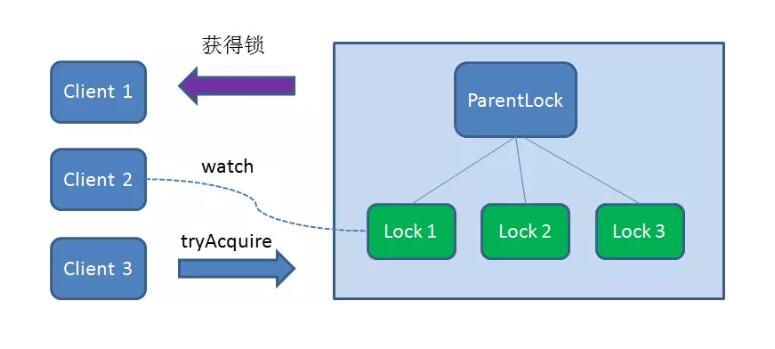
Client3 查找ParentLock 下面所有的临时顺序节点并排序,判断自己所创建的节点Lock3 是不是顺序最靠前的一个,结果同样发现节点Lock3 并不是最小的。
于是,Client3 向排序仅比它靠前的节点Lock2 注册Watcher ,用于监听Lock2 节点是否存在。这意味着Client3 同样抢锁失败,进入了等待状态。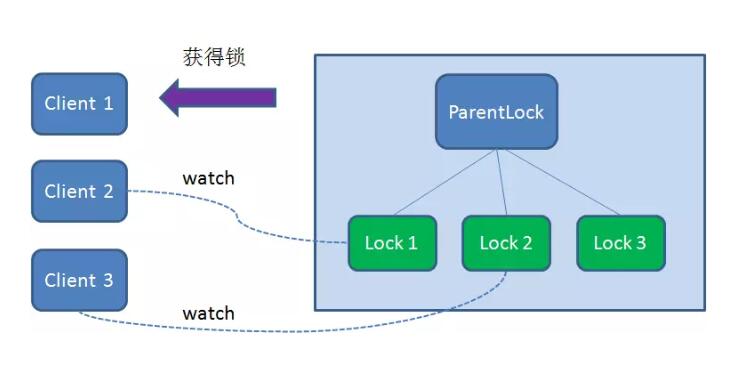
这样一来,Client1 得到了锁,Client2 监听了Lock1 ,Client3 监听了Lock2 。这恰恰形成了一个等待队列,很像是Java 当中ReentrantLock 所依赖的AQS(AbstractQueuedSynchronizer)。
Zookeeper 释放锁原理
释放锁分为两种情况:
任务完成,客户端显示释放
当任务完成时,Client1 会显示调用删除节点Lock1 的指令。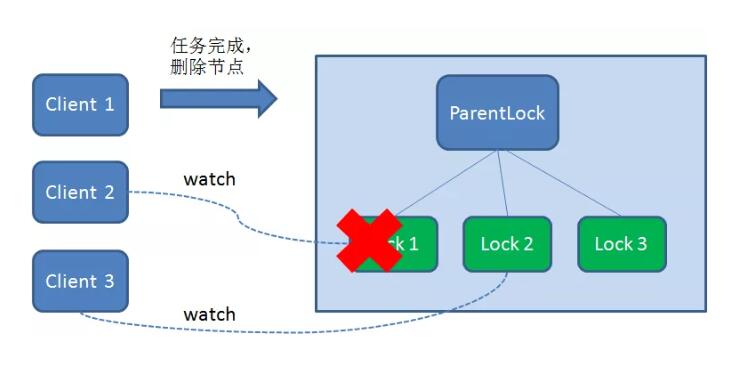
任务执行过程中,客户端崩溃
获得锁的Client1 在任务执行过程中,如果Duang的一声崩溃,则会断开与Zookeeper 服务端的链接。根据临时节点的特性,相关联的节点Lock1 会随之自动删除。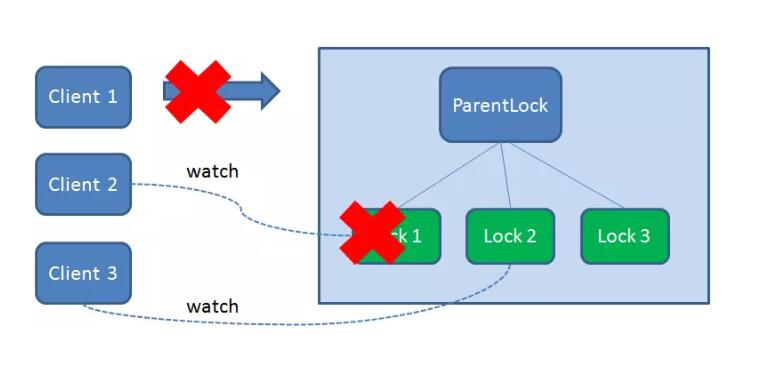
由于Client2 一直监听着Lock1 的存在状态,当Lock1 节点被删除,Client2 会立刻收到通知。
这时候Client2 会再次查询ParentLock 下面的所有节点,确认自己创建的节点Lock2 是不是目前最小的节点。如果是最小,则Client2 顺理成章获得了锁。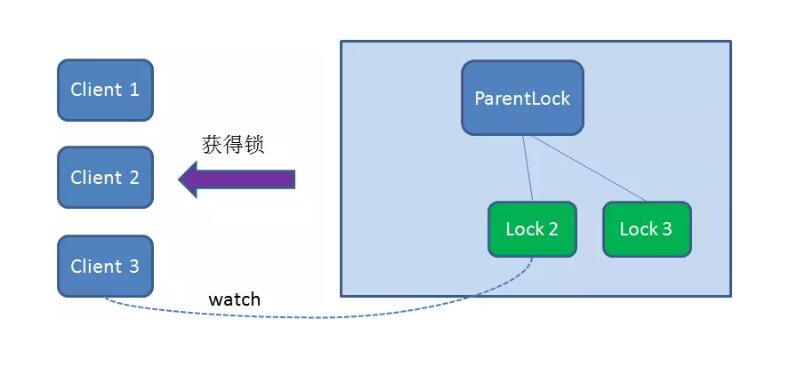
同理,如果Client2 也因为任务完成或者节点崩溃而删除了节点Lock2 ,那么Client3 就会接到通知。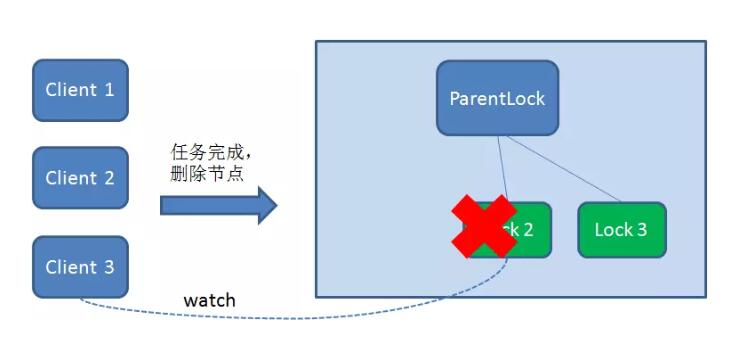
最终,Client3 成功得到了锁。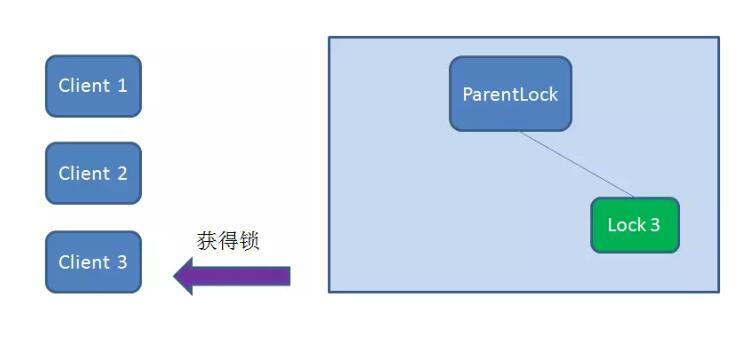
Zookeeper 和Redis 分布式锁之间的比较
下面总结了Zookeeper 和Redis 分布式锁之间的的优缺点: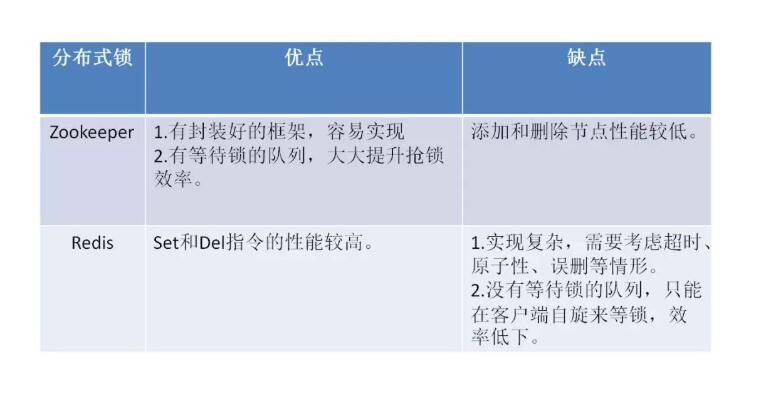
Apache Curator 分布式锁
前提
Apache Curator 被好多人知道都是因为Zookeeper。
https://zookeeper.apache.org/doc/current/zookeeperStarted.html
使用Curator
Apache Curator JAR 可从Maven Central 获得。主页上列出了各种工件Maven、Gradle、Ant 等可以轻松地将Curator 包含在构建脚本中。
获取连接
Apache Curator 使用Fluent Style ,如果你之前没有使用过它,它可能看起来很奇怪,所以建议熟悉这种风格。
Apache Curator 连接实例(CuratorFramework) 是从CuratorFrameworkFactory 分配的。
要连接的每个ZooKeeper 集群只需要一个CuratorFramework 对象:
1 | CuratorFrameworkFactory.newClient(zookeeperConnectionString, retryPolicy) |
这将使用默认值创建与ZooKeeper 集群的连接,需要指定的唯一事情是重试策略。对于大多数情况,应该使用:
1 | RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3) |
必须启动客户端(并在不再需要时关闭)。
调用Zookeeper
一旦有了CuratorFramework 实例,就可以像使用ZooKeeper 发行版中提供的原始ZooKeeper 对象一样直接调用ZooKeeper 。例如:
1 | client.create().forPath("/my/path", myData) |
这里的好处是Curator 管理着ZooKeeper 连接,并在有连接问题时进行重试操作。
Recipes
分布式锁
1 | InterProcessMutex lock = new InterProcessMutex(client, lockPath); |
领导人选举
1 | LeaderSelectorListener listener = new LeaderSelectorListenerAdapter() |
备注
有更多的问题,可以访问官方网站:https://curator.apache.org/
个人备注
此博客内容均为作者学习所做笔记!
若转作其他用途,请注明来源!
文中图片来源于网络!