Cypher 概述
Cypher 是一种声明式图数据库查询语言,它具有丰富的表现力,能高效地查询和更新图数据。 Cypher 查询语言设计很人性化,既适合开发人员,也很适合专业的运营人员。
Cypher 借鉴了 SQL 语言的结构,查询可由各种各样的语句组合。语句被链接在一起,相互之间传递中间结果集。
模式
Neo4j 图由节点和关系构成。节点可能还有标签和属性,关系可能还有类型和属性。节点表达的是实体,关系连接一对节点。节点可以按照类似关系数据库中的表,但又不完全一样。节点的标签可以理解为不同的表名,属性类似关系数据库中表的列。一个节点的数据类似关系数据库中表的一行数据。拥有相同标签的节点通常具有类似的属性,但不完全一样,这点与关系数据库中一张表中的行数据拥有相同的列是不一样的。
单个节点或者关系只能编码很少的信息,但模式可以将很多节点和关系编码为任意复杂的想法。
Cypher 采用一对圆括号来表示节点,如: ()、(foo)。Cypher 使用一对短横线 -- 表示一个无方向关系。有方向的关系在其中一段加上一个箭头 <-- 或 --> 。方括号表达式 [...] 可用于添加详情。里面可以包含变量、属性和类型信息。
将节点和关系的语法结合在一起可以表达模式。
为了增强模块性和减少重复,Cypher 允许将模式赋给一个变量。这使得匹配得到的路径可以被用于其他表达式。
1 | (Keanu:Person:Actor {name: "Keanu Reeves"})-[role:ACTED_IN {roles: ["Neo"]}]->(matrix:Movie {title: "The Matrix"}) |
查询和更新图
一个 Cypher 查询部分不能同时匹配和更新图数据。每个部分要么读取和匹配图,要么更新图。
如果需要从图中读取,然后更新图,那么该查询隐含地包含两个部分,即第一份部分是读取,第二部分是写入。如果查询只是读取,Cypher 将采用惰性加载(Lazy Load),事实上并没匹配模式,直到需要返回结果时才实际去匹配。而在更新查询语句时,所有的读取操作必须在任何的写操作发生之前完成。
当希望使用聚合数据进行过滤时,必须使用 WITH 将两个读语句部分连接在一起。第一部分做聚合,第二部分过滤来自第一部分的结果。
1 | MATCH (n {name: "John"})-[:FRIEND]-(friend) |
任何查询都可以返回结果。RETURN 语句有三个子语句,分别是: SKIP、 LIMIT 和 ORDER BY。
如果返回的图元素是刚刚被删除的,那么要注意此时返回指针的任何操作都是未定义的。
事务
任何更新图的查询都运行在一个事务中。一个更新查询要么全部成功,要么全部失败。Cypher 或者创建一个新的事务,或者运行在一个已有的事务中:
- 如果运行的上下文中没有事务,
Cypher将会创建一个,一旦查询完成就提交该事务。 - 如果运行的上下文中已有事务,查询就会运行在该事务中。直到事务成功地提交之后,数据才会持久化到磁盘中去。
可以将多个查询作为单个事务来提交:
- 开始一个事务。
- 运行多个
Cypher更新查询。 - 一次提交这些查询。
查询将这些变化放在内存中,直到整个查询执行完成。一个巨大的查询会导致 JVM 使用大量的堆空间。
唯一性
当进行模式匹配时,Neo4j 将确保单个模式中不会包含匹配到多次的同一个图关系。在大多数情况下,这是非常敏感的事。
然而有时也未必一直希望如此。如果查询应当返回该用户,可以通过多个 MATCH 语句延伸匹配关系来实现。
1 | // 创建节点和关系 |
兼容性
Cypher 不是一成不变的语言。新版本可能会引入很多的新功能,,一些旧的功能将会被移除。如果需要,旧版本依旧可以访问到。这里有两种方式可以在查询中选择你想使用的版本:
- 为所有查询设置版本。通过设置
neo4j.conf文件中的cypher.default_language_version参数来配置Neo4j数据库使用哪个版本的Cypher语言。 - 在查询中使用指定版本。在查询开始前写上版本。
1
2
3CYPHER 2.3
START n=node:nodes(name = "A")
RETURN n
基本语法
类型
Cypher 处理的所有值都有一个特定的类型,它支持如下类型:
- 数值型。
- 字符串。
- 布尔型。
- 节点。
- 关系。
- 路径。
- 映射(
Map)。 - 列表(
List)。
在 Cypher 语句中,大多数类型的值都可以使用字面值表达式。
在使用 null 的时候要特别注意,因为 null 是任何类型的值。
节点、关系和路径可以作为模式匹配的返回结果。其中标签不是值,他只是模式匹配的一种语法形式。
表达式
Cypher 中的表达式如下:
- 十进制。
- 十六进制整形字面值。
- 八进制整形字面值。
- 字符串字面值。
- 布尔字面值。
- 变量。
- 属性。
- 动态属性。
- 参数。
- 表达式列表。
- 函数调用。
- 聚合函数。
- 路径-模式。
- 计算式。
- 返回
true或者false的断言表达式。 - 正则表达式。
- 大小写敏感的字符串匹配表达式。
CASE表达式。
CASE 表达式
计算表达式的值,然后依次与
WHEN语句中的表达式进行比较,直到匹配为止。如果匹配不上则将ELSE中的表达式作为结果。若是ELSE语句不存在,则直接返回null。1
2
3
4
5
6
7
8
9
10
11
12
13
14CASE test
WHEN value THEN result
[WHEN ...]
[ELSE default]
END
// 示例
MATCH (n)
RETURN n.eye
WHEN 'blue'
THEN 1
WHEN 'grown'
THEN 2
ELSE 3 END AS result按顺序判断断言,直到找到一个为
true,然后对应的结果被返回。如果没有找到,就返回ELSE的值。若没有ELSE语句,就返回null。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15CASE
WHEN predicate THEN result
[WHEN ...]
[ELSE default]
END
// 示例
MATCH (n)
RETURN
CASE
WHEN n.eyes = 'blue'
THEN 1
WHEN n.age < 40
THEN 2
ELSE 3 END AS result
变量
当需要引用模式(Pattern)或者查询某一部分的时候,可以对其进行命名。针对不同部分的这些命名被称为变量。
其中变量名是区分大小写的。它可以包含下划线、字母和数字,但必须以字母开头,如果变量名中需要用到其他字符,可以使用方向单引号 ( ` ) 将变量名括起来。
变量仅在同一个查询中可见,不能被用于后续的查询。
参数
Cypher 支持带参数的查询,这意味着开发人员不是必须用字符串来构建查询,此外这也可以让执行计划的缓存更加容易。
参数能够用于 WHERE 语句中的字面值和表达式,START 语句中的索引值、索引查询以及节点和关系的 id。参数不能用于属性名、关系类型和标签,因为这些模式(Pattern)将作为查询结构的一部分被编译进查询计划。
合法的参数名是字母、数字以及两者的结合。
1 | // 字符串 |
模式
模式和模式匹配是 Cypher 非常核心的部分,要想高效使用 Cypher 必须深入理解模式。
模式描述数据的形式很类似于在白板上画出图的形状。通常用圆圈来表达节点,使用箭头来表达关系。
节点模式
模式能够表达的最简单的形状就是节点。节点使用一对圆括号表示,然后中间含一个名字。
1 | (n) |
关联节点的模式
模式可以表达多个节点及其之间的关系。Cypher 使用箭头来表达两个节点之间的关系。
1 | (a)-->(b) |
这个模式描述了一个非常简单的数据形状,即两个节点和从其中一个节点到另一个节点的关系。两个节点分别命名为 a 和 b,同时关系是有方向的,从 a 指向 b。
这一系列相互关联的节点和关系被称为路径(Path)。
标签
除了可以描述节点之外,也可以用来描述标签,也可同时描述多个标签。
1 | (a:User:Admin)-->(b) |
指定属性
节点和关系是图的基础结构。Neo4j 的节点和关系都可以有属性,这样可以建立更丰富的模型。属性在模式中使用键值对的映射结构来表达,然后用大括号包起来。
1 | (n {name: "John", sport: "Hello World"}) |
但模式中有属性时,它实际上为数据增加了额外的约束。在 CREATE 语句中,属性会被增加到新创建的节点和关系中。而在 MERGE 语句中,属性将作为一个约束去匹配数据库中的数据是否存在该属性。如果没有匹配到,此时 MERGE 的行为将会与 CREATE 一样,即属性将被设置到新创建的节点和关系中。
描述关系
如前面所示,可以使用箭头简单地描述两个节点之间的关系。它描述了关系的存在性和方向性。当如果不关心关系的方向,则箭头是可以省略的。
与节点类似,如果后续还需要引用到该关系,则可以给关系赋值一个变量名。而变量名需要用方括号括起来,放在箭头的短横线之间。
1 | (a)-[r]-(b) |
同时关系也是有类型的。给关系指定一个或多个类型。多个类型之间使用 | 相隔。
1 | (a)-[r:TYPE1|TYPE2]-(b) |
与使用一串节点和关系来描述一个长路径的模式不同,很多关系(依次中间的节点)可以采用指定关系的长度的模式来描述。
1 | (a)-[*1...N]-(b) |
变长关系不能用于 CREATE 和 MERGE 语句。
赋值给路径变量
连接在一起的一系列节点和关系被称为路径。Cypher 允许使用标识符给路径命名。
在 MATCH 中,CREATE 和 MERGE 语句可以这么做,但当模式作为表达式的时候不能这样。
1 | p = (a)-[*3...5]->(b) |
列表
使用方括号和一组以逗号分隔的元素来创建一个列表。也可以使用 range() 函数,它可以生成列表,其中包含元素的开始元素和结束元素。
使用 [] 访问列表中的元素。
索引也可以为负数,这时访问的方向将从列表的末尾作为起始点。
也可以在 [] 中指定列表返回范围的元素。他将提取开始索引到结束索引的值,但不包含结束索引所包含的值。
1 | RETURN [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] AS list |
如果返回一个范围的索引值越界,那么返回直接从越界的地方进行截断。如果是单个元素的索引值越界,则返回 null。
List 推导式
List 推导式是 Cypher 中基于已经存在的列表创建一个列表的语法构造。它遵循数学上的集合,代替使用映射和过滤函数。
1 | RETURN [x IN range(0, 10) WHERE x % 2 = 0 | x^3] AS result |
模式推导式
模式推导式是 Cypher 基于模式匹配的结果创建列表的一种语法构造。模式推导式将像一般的 MATCH 语句那样去匹配模式,断言部分与一般的 WHERE 语句一样,但他将产生一个指定的定制映射。
1 | MATCH (a:Person {name: "John"}) |
字面值映射
Cypher 也可以构造映射,通过 REST 接口可以获得 JSON 对象。在 Java 中对应的就是 java.util.Map<String, Object>。
1 | RETURN { key: 'Value', listKey: [{inner: "Map1"}, {inner: "Map2"}]} |
Map 投射
Cypher 支持一个名为 map projections 的概念。踏实的基于已有的节点、关系和其他 map 值来构建变得容易。Map 投射以指向图实体的且用逗号风格的变量簇开头,并包含以 {} 包括起来的映射元素,语法如下:
1 | map_variable {map_element, [, ...n]} |
一个 map 元素投射一个或多个键值对到 map 投射。这里有四种类型的 map 投射元素:
- 属性选择器。投射属性名作为键,
map_variable中对应键的值作为键值。 - 字面值项。来自任意表达式的键值对,如
key: <expression>。 - 变量选择器。投射一个变量,变量名作为键,变量的值作为投射的值。它的语法只有变量。
- 全属性选择器。投射来自
map_variable中的所有键值对。
1 | MATCH (actor:Person {name: 'Charline sheen'})-[:ACTED_IN]->(movie:Movie) |
如果 map_variable 的值指向一个 null,那么整个 map 投射将返回 null。
空值
空值 null 在 Cypher 中表示未找到或者未定义。从概念上讲,null 意味者一个未找到的未知值。
对待 null 会与其他值有些不同,null 不等于 null,两个未知的值并不意味着他们是同一个值。因此 null = null 返回 null 而不是 true。
返回空值的表达式:
- 从列表中获取不存在的元素。
[][0], head([]) - 试图访问节点或者关系的不存在的属性。
n.missingProperty - 与
null作比较。1 < null - 包含
null的算术运算。1 + null - 包含任何
null参数的函数调用。sin(null)
语句
语句可分为三类,包括读语句、写语句和通用语句。
读语句:
MATCHOPTINAL MATCHWHERESTARTAggregationLOAD CSV
写语句:
CREATEMERGESETDELETEREMOVEFOREACHCREATE UNIQUE
通用语句:
RETURNORDER BYLIMITSKIPWITHUNWINDUNIONCALL
MATCH
MATCH 语句用指定的模式检索数据库。他常与带有约束或者断言的 WHERE 语句一起使用,这意味着匹配更加具体。其中断言是模式描述的一部分,它不能看作是匹配结果的过滤器,这也就意味着 WHERE 应当总是与 MATCH 语句放在一起。MATCH 可以出现在查询的开始或者末尾,也可能位于 WITH 之后。如果他在语句开头,此时不会绑定任何数据。因此 Neo4j 将设计一个搜索去找到匹配这个语句以及 WHERE 中指定断言的结果。这其中将会牵涉数据库的扫描、搜索特定标签的节点或者搜索一个索引以找到匹配模式的开始点。这个搜索找到的节点和关系可作为一个“绑定模式元素”。这个可以用于匹配一些子图的模式,也可以用于任何进一步的 MATCH 语句,至此 Neo4j 将使用这些已知的元素来找到更进一步的未知元素。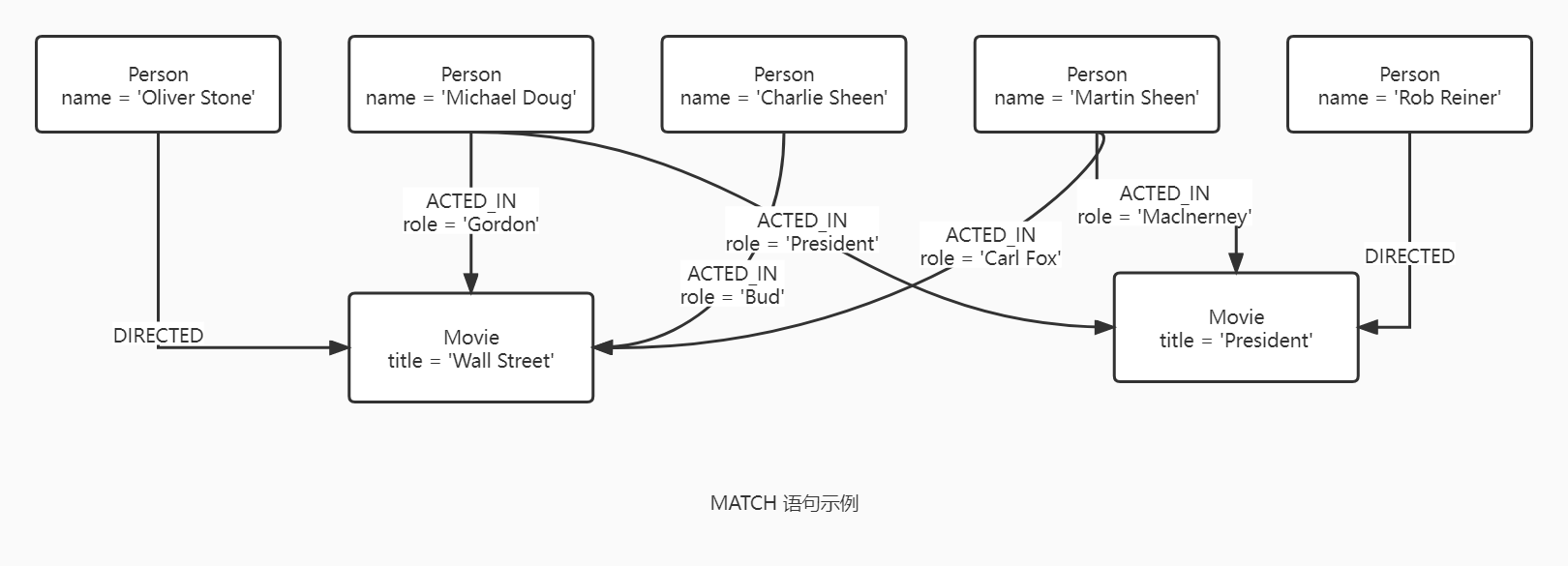
查找结点
1 | // 指定不带标签的节点的模式 |
关系
1 | // 关系的方向 |
关系的深度
1 | // 多个关系 |
最短节点
1 | // 单条最短路径,通过 shortestPath 函数找到两个节点之间的最短路径 |
通过 id 查询关系和节点
Neo4j 会重用已删除节点和关系的 id。这意味着内部的 id 可能与预期的节点不一致。
1 | // 通过 id 查询节点,可以在断言中使用 id() 函数来根据 id 查询节点 |
OPTINAL MATCH
OPTINAL MATCH 语句用于搜索模式中描述的匹配项,对于找不到的项用 null 代替。其实 OPTINAL MATCH 与 MATCH 类似,不同之处在于,如果没有匹配到,OPTINAL MATCH 将用 null 作为未匹配部分的值。OPTINAL MATCH 在 Cypher 中类似于 SQL 语句中的 outer join。
要么匹配整个模式,要么都未匹配。其中 WHERE 是模式描述的一部分,匹配的时候就会考虑到 WHERE 中的断言,而不是匹配之后。这对于有多个 (OPTINAL) MATCH 语句的查询尤其重要,一定要将属于 MATCH 的 WHERE 语句与 MATCH 放在一起。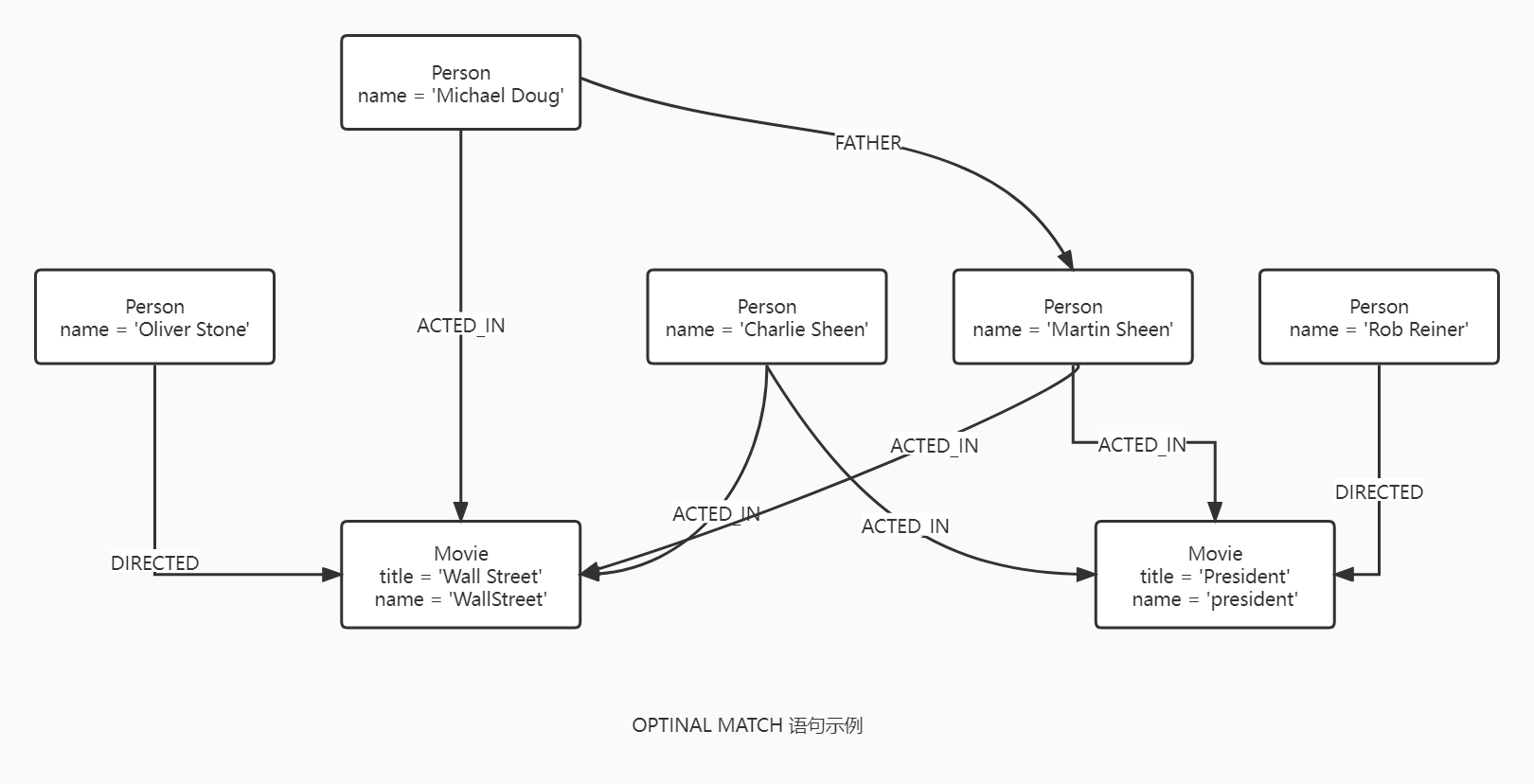
关系
1 | // 如果某个关系是可选的,可以使用 OPTINAL MATCH(类似于 SQL 中的 outer join,存在就返回,不存在就返回 null) |
可选元素的属性
1 | // 如果可选的元素为 null,那么该元素的属性也返回 null |
可选关系类型
1 | // 可在查询中指定可选的关系类型 |
WHERE
WHERE 在 MATCH 或者 OPTINAL MATCH 语句中添加约束或者与 WITH 一起使用来过滤结果。WHERE 不能单独使用,他只能作为 MATCH 、 OPTINAL MATCH 、 START 、 WITH 的一部分。
- 如果是在
WITH和START中,将被只用于过滤结果。 - 对于
MATCH和OPTINAL MATCH,WHERE为模式增加约束,不能被看作是匹配完成后的结果过滤。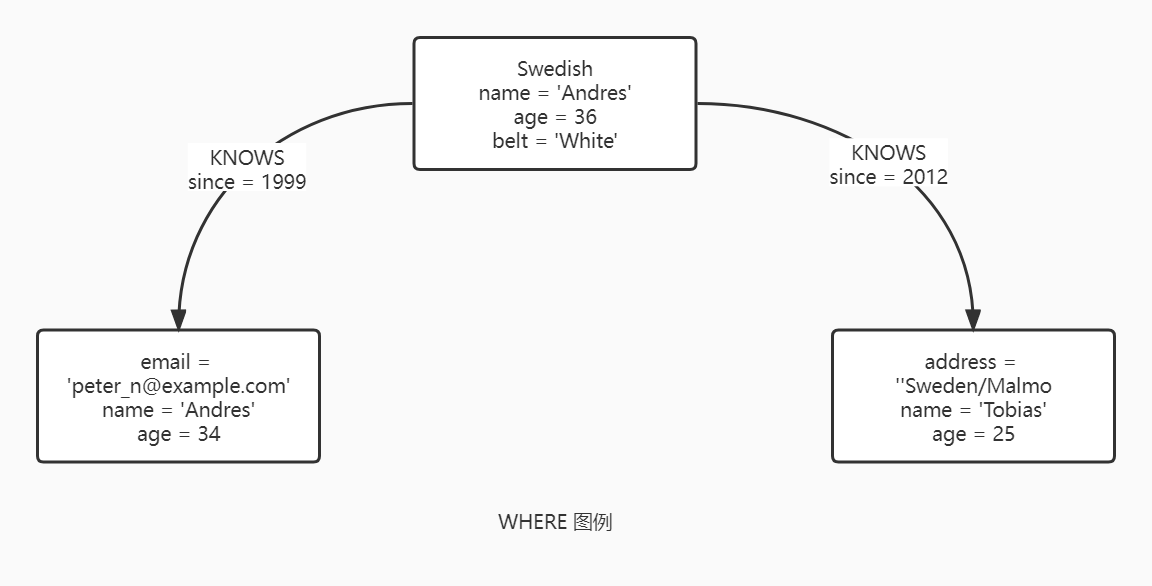
基本使用
1 | // 在 WHERE 中使用布尔运算符 |
字符串匹配
可以使用 STARTS WITH 和 ENDS WITH 来匹配字符串的开始和结尾。如果不关心匹配字符串的未知,则可以用 CONTAINS,其中匹配时是区分大小写的。
1 | // STARTS WITH 匹配字符串的开始 |
正则表达式
Cypher 支持正则表达式过滤。正则表达式的语法继承自 Java 正则表达式。它支持字符串如何匹配标记,包括不区分大小写 (?i)、多行 (?m)、 单行 (?s)。
1 | // 使用 =~'regexp' 来进行正则表达式 |
使用路径模式
模式是返回一个路径列表的表达式。列表表达式也是断言,空列表代表 false,非空列表代表 true。因此模式不仅仅是表达式,同时也是断言。
模式的局限性在于只能在单条路径中表达,不能像在 MATCH 语句中那样使用逗号分隔多条路径,但是可以通过 AND 组合多个模式。
1 | // 使用模式查询节点 |
使用范围
1 | // 检查列表中是否存在某个元素,可以使用 IN 运算符 |
START
通过遗留索引(Legacy Index)查找开始点。Cypher 中的每个查询描述了一个模式,一个模式可以有多个开始点。一个开始点是模式中的一个关系或者一个节点。
使用 START 时只能通过遗留索引寻找来引出开始点。其中使用不存在的遗留索引将会报错。START 语句应当仅用于访问遗留索引,所以其他的情况,都应该使用 MATCH 代替。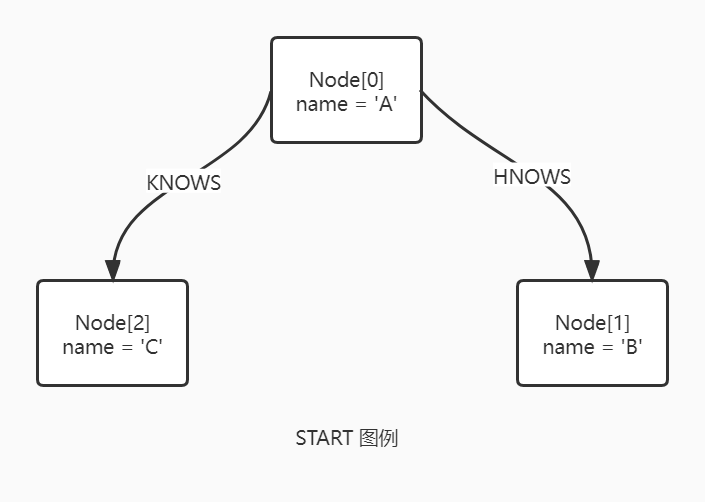
通过索引获取节点
1 | // 通过索引搜索(Index Seek)获取节点 |
通过索引获取关系
1 | // 通过索引搜索(Index Seek)获取关系 |
Aggregation
Cypher 支持使用聚合(Aggregation)来计算聚合在一起的数据,类似于 SQL 中的 group by。其中聚合函数有多个输入值,然后基于他们计算出一个聚合值。
聚合函数可以在匹配到的子图上进行计算,非聚合的表达式将值聚集起来,然后放入到聚合函数中。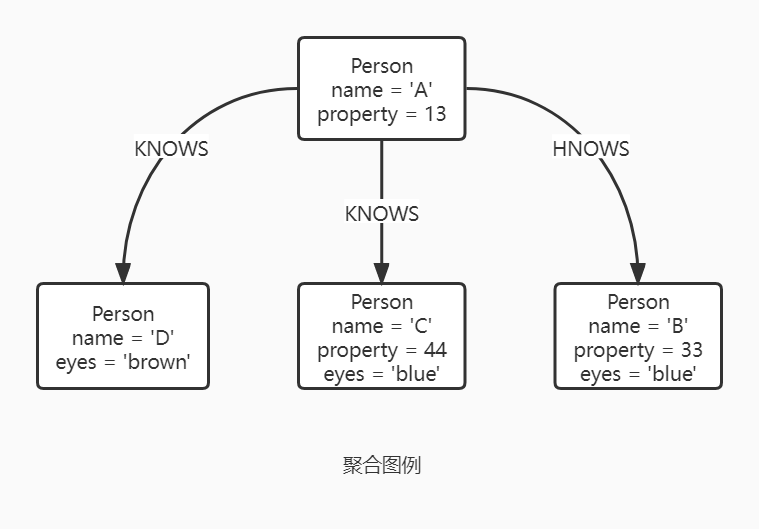
Count
count 用于计算行的数量。count 有两种计算方式: count(*) 用于计算匹配的行数,而 count(<expression>) 用于计算列中非空值的数量。
1 | // 计算节点的数量 |
统计
1 | // sum 计算所有值之和,空值将会被丢弃 |
Load CSV
Load CSV 用于从 CSV 文件中导入数据。
CSV文件的URL可以由FROM后面紧跟的任意表达式来指定。- 需要使用
AS来为CSV数据指定一个变量。 Load CSV支持以gzip, Deflate和ZIP压缩的资源。CSV文件可以存在数据库服务器上,通过file:///URl访问。支持通过HTTPS, HTTP, FTP来访问CSV文件。Load CSV支持HTTP重定向,但基于安全考虑,重定向时不能改变协议类型。
CSV 文件格式
- 字符编码为
UTF-8。 - 行结束符与操作系统关联,如
unix为\n,windows为\r\n。 - 默认的字段终止符。
- 字段终止符可以使用
Load CSV中的FIELDTERMINATOR选项来修改。 CSV文件允许引号字符串,但读取数据的时候引号字符会被丢弃。- 字符串的引号字符为双引号
"。 - 转义字符为
\。
CREATE
CREATE 语句用于创建图元素:节点和关系。
创建节点
1 | // 创建多个节点 |
创建关系
1 | // 创建两个节点之间的关系并设置属性 |
创建路径
1 | // 创建一个完整的路径 |
使用参数
1 | // 使用参数 |
MERGE
MERGE 可以确保图数据库中存在某个特定的模式(Pattern),如果该模式不存在,那么就创建它。MERGE 匹配已存在的节点并绑定它,或者创建新的节点然后绑定它。它有点像 MATCH 和 CREATE 语句的组合,可以让你指定让某个数据存在,不管它是匹配到还是创建它。
当在整个模式上使用 MERGE 时,要么是整个模式匹配到,要么就整个模式被创建。MERGE 不能部分被用于模式,如果希望部分匹配,则可以将模式拆分为多个 MEREG 语句。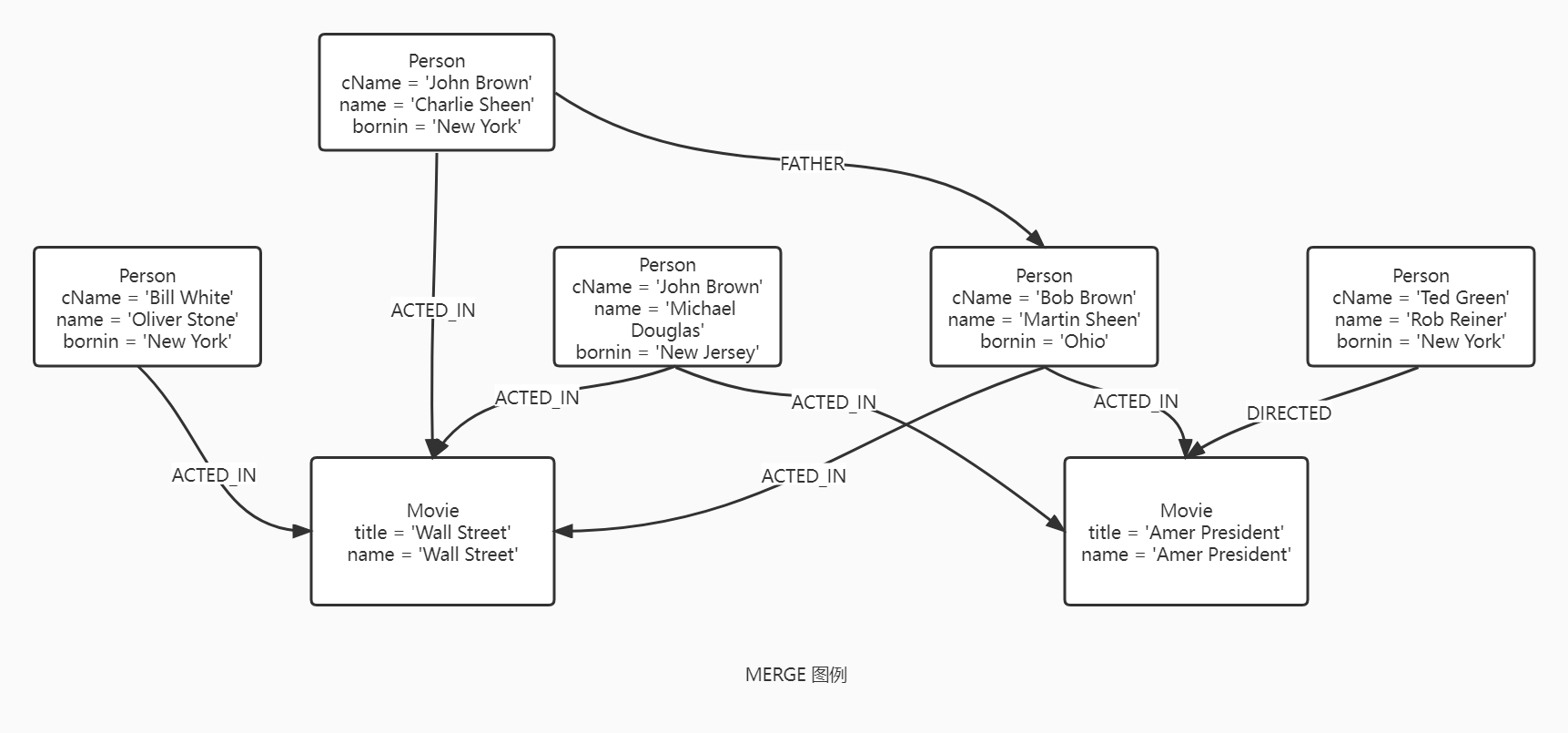
节点
1 | // 合并给定标签的节点 |
在 CREATE 和 MATCH 中使用
1 | // MERGE 与 CREATE 搭配,检查节点是否存在,若不存在则创建它并设置属性 |
关系
1 | // 匹配或者创建无方向关系0 |
map 参数
1 | // MERGE 不支持像 CREATE 节点时那样使用 map 参数。要在 MERGE 中使用 map 参数,需要显式地使用希望用的属性 |
SET
SET 语句用于更新节点的标以及节点和关系的属性。 SET 可以使用 map 中的参数来设置属性。
设置节点的标签时幂等性操作,即如果试图设置一个已经存在的标签到节点上,什么也不会发生。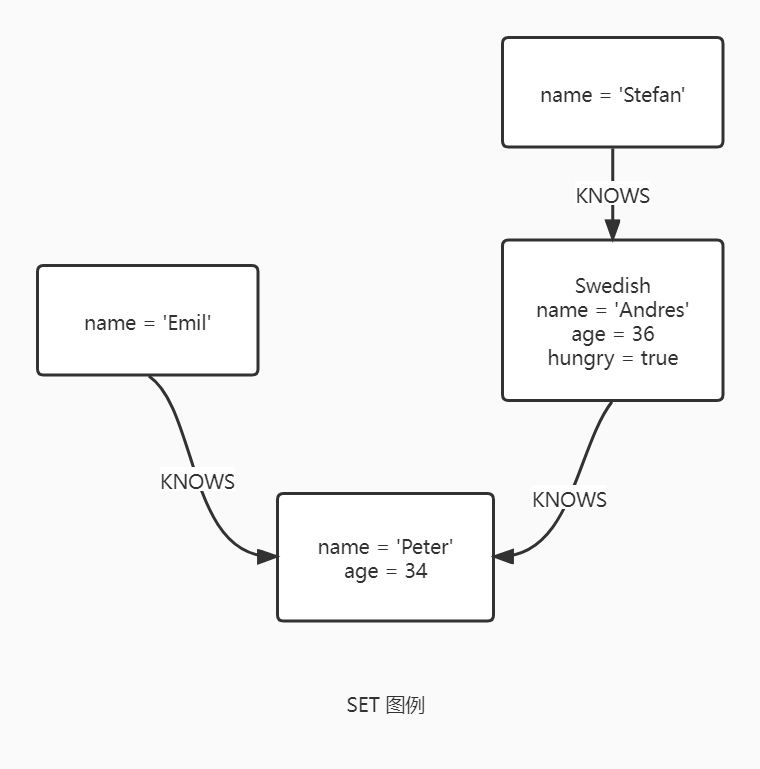
1 | // 设置节点或关系属性 |
DELETE
DELETE 语句用于删除图元素(节点、关系或路径)。同时也可以删除属性和标签。记住不能只删除节点,而不删除与之相连的关系,要么显式地删除对应的关系,要么使用 DETACH DELETE。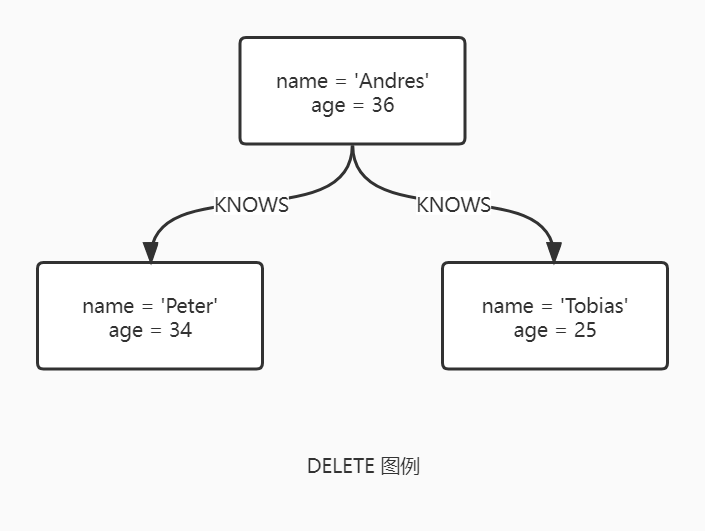
1 | // 删除单个节点 |
REMOVE
REMOVE 语句用于删除图元素的属性和标签。
删除节点的标签是幂等性操作。如果删除一个节点不存在的标签,什么也不会发生。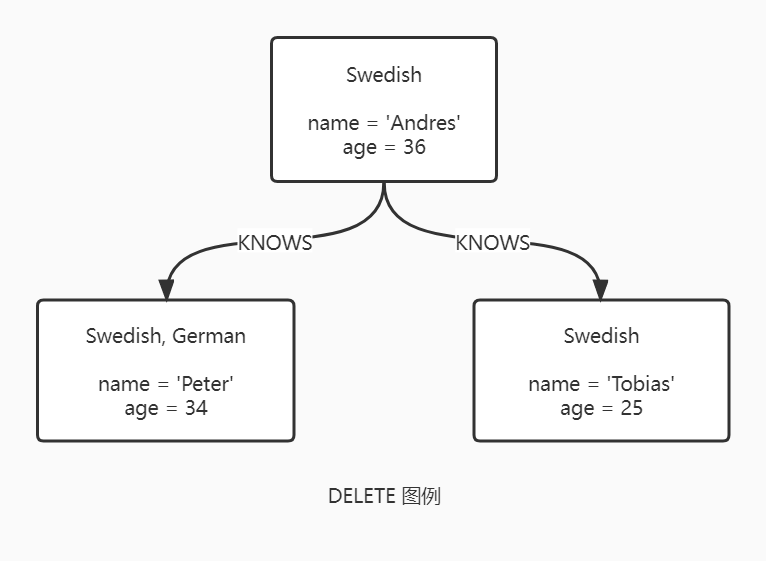
1 | // 删除一个属性 |
FOREACH
FOREACH 语句用于更新列表中的数据,或路径的组件,或者聚合的结果。
列表(Lists)和路径(Paths)是 Cypher 中的关键概念,都可以使用 FOREACH 来更新其中的数据。它可以在聚合的列表或者路径的每个元素上执行更新命令。其中 FOREACH 括号中的变量是与外部分开的,这意味着 FOREACH 中创建的变量不能用于该语句之外。
在 FOREACH 括号内,可以执行任何的更新命令,包括 CREATE、CREATE UNIQUE、DELETE 和 FOREACH,如果希望对列表中的每个元素执行额外的 MATCH 命令,使用 UNWIND 命令更加合适。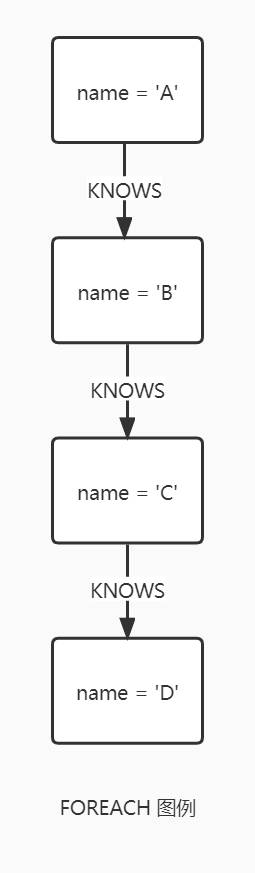
1 | // 标记路径上的所有节点的 marked 属性为 true |
CREATE UNIQUE
CREATE UNIQUE 语句相当于 MATCH 和 CREATE 的组合体,尽可能的匹配,然后创建未匹配到的。CREATE UNIQUE 介于 MATCH 和 CREATE 之间,其作用是匹配所能匹配上的,然后创建不存在的。CREATE UNIQUE 会尽可能的减少对图的改变,充分利用已有的图。
其中与 MATCH 的另一个不同就是,CREATE UNIQUE 假设模式是唯一的,如果有多个匹配的子图可以找到,那么此时就会报错。
你可能会想到使用 MERGE 来代替 CREATE UNIQUE,但是 MERGE 不能很好的保证关系的一致性。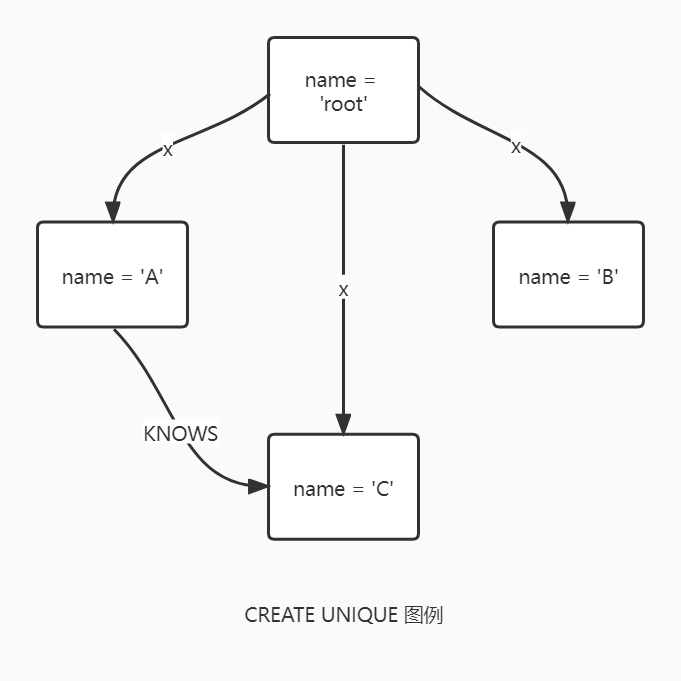
节点
1 | // 创建未匹配到含有属性的节点 |
关系
1 | // 创建未匹配的含有属性的关系 |
复杂模式
1 | // 描述复杂模式 |
RETURN
RETURN 语句定义了查询结果集中返回的内容。在查询的 RETURN 部分定义了模式中待查询的内容,其中可以是节点、关系或者是属性。
如果只需要属性值,要尽量避免返回整个节点或关系,这样有助于提高性能。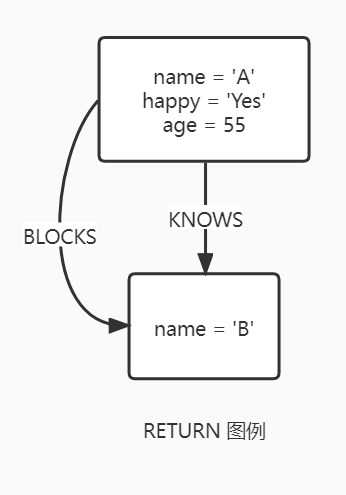
1 | // 返回节点 |
ORDER BY
ORDER BY 是紧跟 RETURN 或者 WITH 的子句,它指定了输出的结果如何排序。(不能对节点和关系进行排序,只能对他们的属性进行排序)
在变量的范围方面,ORDR BY 遵循特定的规则,这取决于 RETURN 的投射或 WITH 语句是否聚合或者 DISTINCT。如果他是一个聚合或者 DISTINCT 投射,那么只有投射中的变量可用。如果投射不修改输出基数(聚合和 DISTINCT 做的),在投射之前可用的变量依旧可用。当投射语句覆盖已经存在的变量时,那么只有新的变量可用。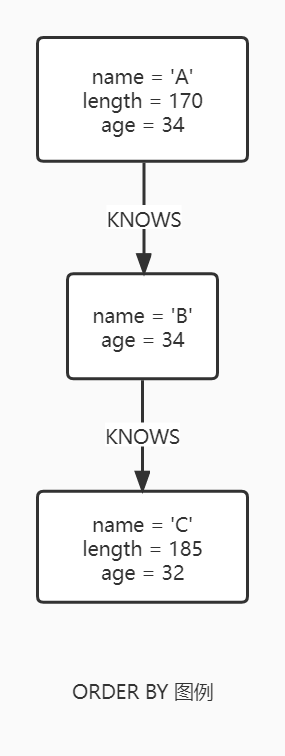
1 | // 根据多个属性对节点进行排序(多个属性会首先检查第一个变量,相等的值再检查下一个变量) |
LIMIT
LIMIT 限制输出的行数。LIMIT 可接受结果为正整数的任意表达式,但表达式不能引用节点或者关系。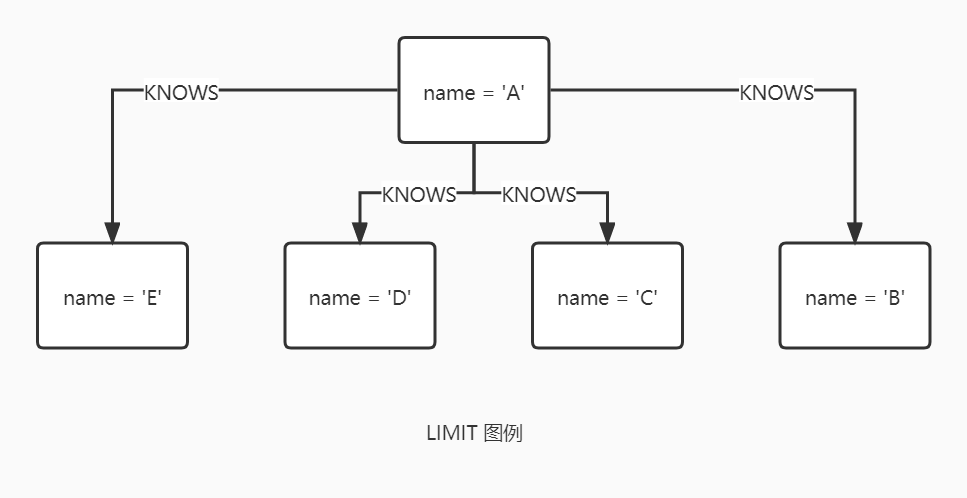
1 | // 返回结果的一个子集 |
SKIP
SKIP 定义从哪行开始返回结果集。即使用 SKIP 可以跳过开始的一部分结果。
1 | // 从第四个开始返回结果的子集 |
WITH
WITH 语句将分段的查询部分连接在一起,查询结果从一部分以管道的形式传递到另一部分作为开始点。
使用 WITH 可以将结果传递到后续查询之前对结果进行操作。其中操作可以改变结果的形式或数量,最常见的用法就是限制传递给其他 MATCH 语句的结果数,通过结合 ORDER BY 和 LIMIT,可获取排在前面多个结果。
另一个比较常见的用法就是在聚合值上过滤。WITH 用于在 WHERE 断言中引入聚合,这些聚合表达式创建了新的结果绑定字段,当然 WITH 也可以像 RETURN 一样对结果使用别名作为绑定名。WITH 还可以用于将图的读语句和更新语句分开,查询中的每一部分要么只是读取,要么都是写入,当写部分的语句是基于读语句的结果时,这两者之间的转换必须使用 WITH。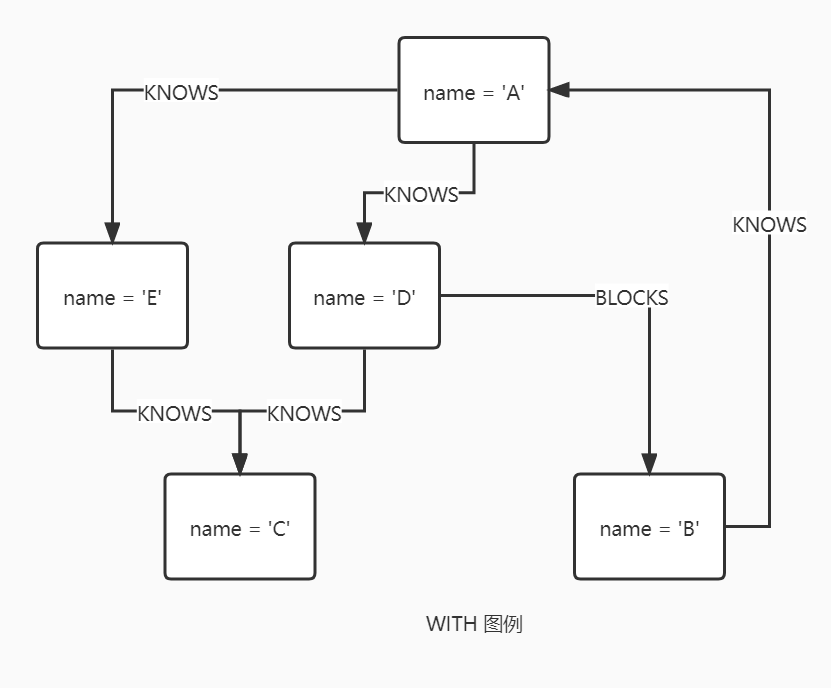
1 | // 过滤聚合函数结果,聚合的结果必须要通过 WITH 语句传递才能进行过滤 |
UNWIND
UNWIND 将一个列表展开为若干个行的序列。
用 UNWIND 可以将任何列表转为单独的行,这些列表可以以参数的形式传入,如前面的 collect 行数返回的结果。UNWIND 一个较为常见的用法就是创建唯一列表。另外一个就是从提供给查询的参数列表中创建数据。UNWIND 需要给内部值指定新的名字。
1 | // 将一个产量列表转化为行并返回 |
UNION
UNION 语句用于将多个查询结果组合起来。其中使用 UNION 组合查询的结果时,所有查询到的列的名称和数量必须完全一致。
在使用 UNION ALL 会包含所有的结果行,而用 UNION 组合时,会移除结果集中的重复行。
1 | // 组合两个查询 |
CALL
CALL 语句用于调用数据库中的过程(Procedure)。
在使用 CALL 语句的调用过程中,需要制定所需要的参数,其中可以通过在过程名的后面使用逗号分隔的列表来显式地指定,同时也可以使用查询参数来作为过程调用的参数。后者仅适用于在单独的过程调用中作为参数,即整个查询语句只包含一个单一的的 CALL 调用。Neo4j 支持 VOID 过程。VOID 过程既没有声明任何结果字段,也不会返回任何结果记录。但是调用 VOID 过程有一个明显的弊端,就是它既不允许也不需要使用 YIELD。在一个大的查询中调用 VOID 过程,就像 WITH * 在记录流中的作用那样,只是简单的传递输入的每一个结果。
1 | // 调用过程,列出数据库中的所有标签 |
本节未完,且看下回分解!
引用
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!