Neo4j 正式支持 .Net 、 Java 、 JavaScript 、 Ruby 、 PHP 和 Python 的二进制 Bolt 协议驱动程序。这些开发平台通过引入相应的驱动程序包便可与 Neo4j 相互集成,然后就可以对 Neo4j 进行数据操作。
入门
目前 Neo4j 支持三种开发模式,分别为:
Java嵌入式开发模式。Neo4j是基于Java语言开发的,所以他能与Java开发天然结合,完全可以在代码中调用Neo4j的API,并将对Neo4j数据库的操作嵌入在Java代码中。- 驱动包开发模式。通过
HTTP的HTTP API的驱动包让非基于JVM的开发平台、编程语言也能够操作Neo4j数据库。
嵌入式开发模式
Java API 嵌入式开发模式中,应用程序、Java API、Neo4j 数据的关系如下图所示: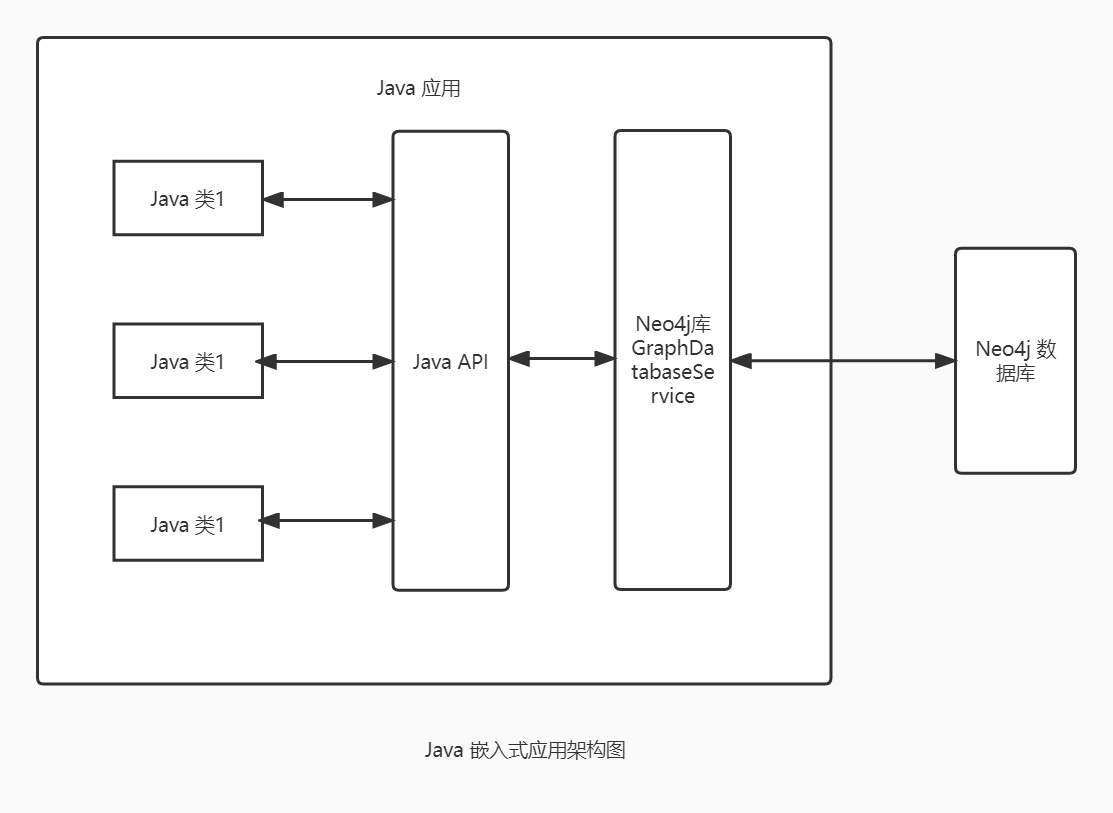
当在同一个 JVM 中运行自己的代码和 Neo4j 时,需要注意以下几点:
- 不要创建或保留过多不需要的对象。大型缓存会将不需要的对象推向垃圾回收区,会增加垃圾回收的负担。
- 尽量不要使用内部
Neo4j API。他们是供Neo4j内部使用,使用不当可能会破坏或更改Neo4j的固有特性。 - 在嵌入式模式下运行时,不要启用
-XX:+TrustFinalNonStaticFields的JVM标志。
准备工作
这一小节是为开发前的准备工作,包括 JAR 包的引入、不同 IDE 下的引入方式和程序主体代码的编写。
引入 JAR 包
首先根据应用程序使用的 Java 版本选择合适的 Neo4j JAR 包版本,然后在应用程序项目中引入此 JAR 包,这样 Neo4j API 就嵌入到了 Java 应用程序中。以下部分将介绍通过两个途径来引入 Neo4j JAR 包:
- 将
JAR文件直接添加到Java的执行路径ClassPath中。 - 使用依赖关系管理来添加
Neo4j JAR包的依赖。
Intellij IDEA
使用 Libraries\Global Libraries 和 Configure Library 对话框,可以引入 JAR 文件。
Maven
添加到项目根目录下的 pom.xml 文件中。
1 | <dependecy> |
启动和关闭 Neo4j
在完成上述步骤后,我们尝试使用 Java API 启动和关闭 Neo4j。要创建一个新的数据库或者打开一个已经存在的数据库,首先需要创建 GraphDatabaseService 实例。
1 | graphDb = new GraphDatabaseFactory().newEmbeddedDatabase(DB_PATH); |
GraphDatabaseService 实例可以在多个线程之间共享,但不能创建指向同一个数据库的多个实例。
关闭一个已经打开的实例,需要调用 shutdown() 方法。
1 | graphDb.shutdown(); |
按配置文件启动 Neo4j
Neo4j 数据库包含一个配置文件,如果想要让 Neo4j 按照配置启动,代码如下:
1 | GraphDatabaseService graphDb = new GraphDatabaseService() |
当然配置项也可以在代码中设置:
1 | GraphDatabaseService graphDb = new GraphDatabaseService() |
启动一个只读实例
如果希望以只读的方式打开 Neo4j 数据库而不想进行任何写操作,代码如下:
1 | GraphDatabaseService graphDb = new GraphDatabaseService() |
创建图实例
Neo4j 数据库中数据的基本结构:
- 节点:表示一个实体,可以用关系连接起来。
- 关系:用来连接节点。
- 属性:依附在节点或关系上的属性及其属性值。
任何关系都有一个指定的类型名。如果两个节点被 KNOWS 类型的关系相互连接起来,那么说明这两个人互相认识对方。因此图的很多含义就是被用这样的方式编码后存储在 Neo4j 数据库中,尽管关系是直接将两个节点连接起来,但不管关系指向哪个节点,他们在数据库中都可以快速地遍历、查询。
创建数据库
关系的类型标签可以使用枚举类型 enum 创建。
1 | public static enum RelType implements RelationshipType { |
接下来就是启动数据库实例,需要注意的是,如果创建的数据库当前并不存在,那么就会系统会自动创建一个新的数据库。
1 | graphDb = new GraphDatabaseFactory().newEmbeddedDatabase(DB_PATH); |
这个实例是可以被被多个线程共享,但是在进行事务操作时多个进程之间是相互冲突的,因此在同一个时间只能有一个进程操作某实例。
操作写入到事务中
在 Neo4j Java API 中所有的操作都必须放入到一个事务中,正如这样以保证某些重要操作的可靠性。
1 | try (Transaction tx = graphDb.beginTx()) { |
创建一个节点
除了上面的枚举类型定义,还需要定义变量,变量定义完成后还需要对变量进行赋值并创建节点。节点创建完成后并没有赋任何属性值,所以节点只包含默认的 id 值。
1 | GraphDatabaseService graphDb; |
为节点创建属性值
在 Neo4j 中节点、关系都有属性,也就是说节点、关系所附带的值包含 ID 、Label(关系为 Type)、属性三种。任何节点或关系都可以包含多个属性。
属性包括属性名和属性值两部分。属性名可以按照 Java 命名规范取名,属性值可以是单个值也可以是数组。NULL 在 Neo4j 中不可以赋值,但可以通过 NULL 来判断属性是否存在。
1 | try (Transaction tx = graphDb.beginTx()) { |
为节点添加标签
在 Neo4j 中有一种将节点归类的方法,那就是标签(Label)。通过给节点添加相同或不同的标签可以将节点进行归类。每个节点可以添加一个或多个标签,标签是一种文字描述,可以通过标签加载、查询所有节点。
创建一个标签,可以通过使用枚举类型继承 Neo4j 的 Label 接口来创建
1 | public enum MyLabels implements Label { |
为节点添加标签
1 | try (Transaction tx = graphDb.beginTx()) { |
添加标签之后就可以通过标签来查询此类节点的集合。
1 | try (Transaction tx = graphDb.beginTx()) { |
在查找节点时,想通过节点属性和标签同时锁定节点集合,那么可以通过 findNodesByLabelAndProperty() 方法来实现。
1 | ResourceIterable<Node> movies = GlobalGraphOperations.at(graphDb) |
创建关系
创建两个节点之间的关系并为这个新创建的关系添加属性值。在创建时可以指定关系的类型,关系的类型类似节点的标签,唯一不同的是关系的类型只能指定一个。
1 | relationship = Keanu.createRelationshipTo(TheMatrix, RelType.ACTED_IN); |
输出图结果
将创建的图数据打印在控制台上。
1 | System.out.println(Keanu.getProperty("name")); |
删除数据
1 | Keanu.getSingleRelationship(RelType.ACTED_IN, Direction.OUTGOING).delete(); |
如果尝试删除一个带有关系边的节点时必定会失败,因此必须首先删除关系并确保没有任何关系指向这个节点时,才能够删除它。这是为了任何关系都有起始节点和结束节点的指向,没有空指向的关系。
关闭数据库
1 | graphDb.shutdown(); |
图数据遍历
至此我们已经创建了一个由节点、关系和索引组成的图数据库,接下来就是查询图数据的强大功能:图遍历功能。图遍历是以一种特殊的方式在图中按照节点之间的关系依次访问各个节点的过程。Neo4j 遍历 API 采用的是一种基于回调的、惰性执行的机制,使用 Neo4j 的图遍历功能可以使用指定的方式对数据库进行遍历。另外还可以使用 Cypher 查询语句的声明式方法对图进行查询。
入门概念
使用以下几个概念来解释图遍历功能
- 路径拓展(
PathExpander):定义将要对图数据库中的什么进行遍历,一般是指针对关系的指向和关系的类型进行遍历。 - 顺序(
Order):深度优先或广度优先。 - 唯一性(
Uniqueness):在遍历过程中,确保每个节点(关系、路径)只被遍历一次。 - 评估器(
Evaluator):用来决定返回什么结果,以及是否停止或继续遍历当前位置。 - 开始节点:启动遍历最先开始的节点。
Neo4j 遍历框架的结构图如下: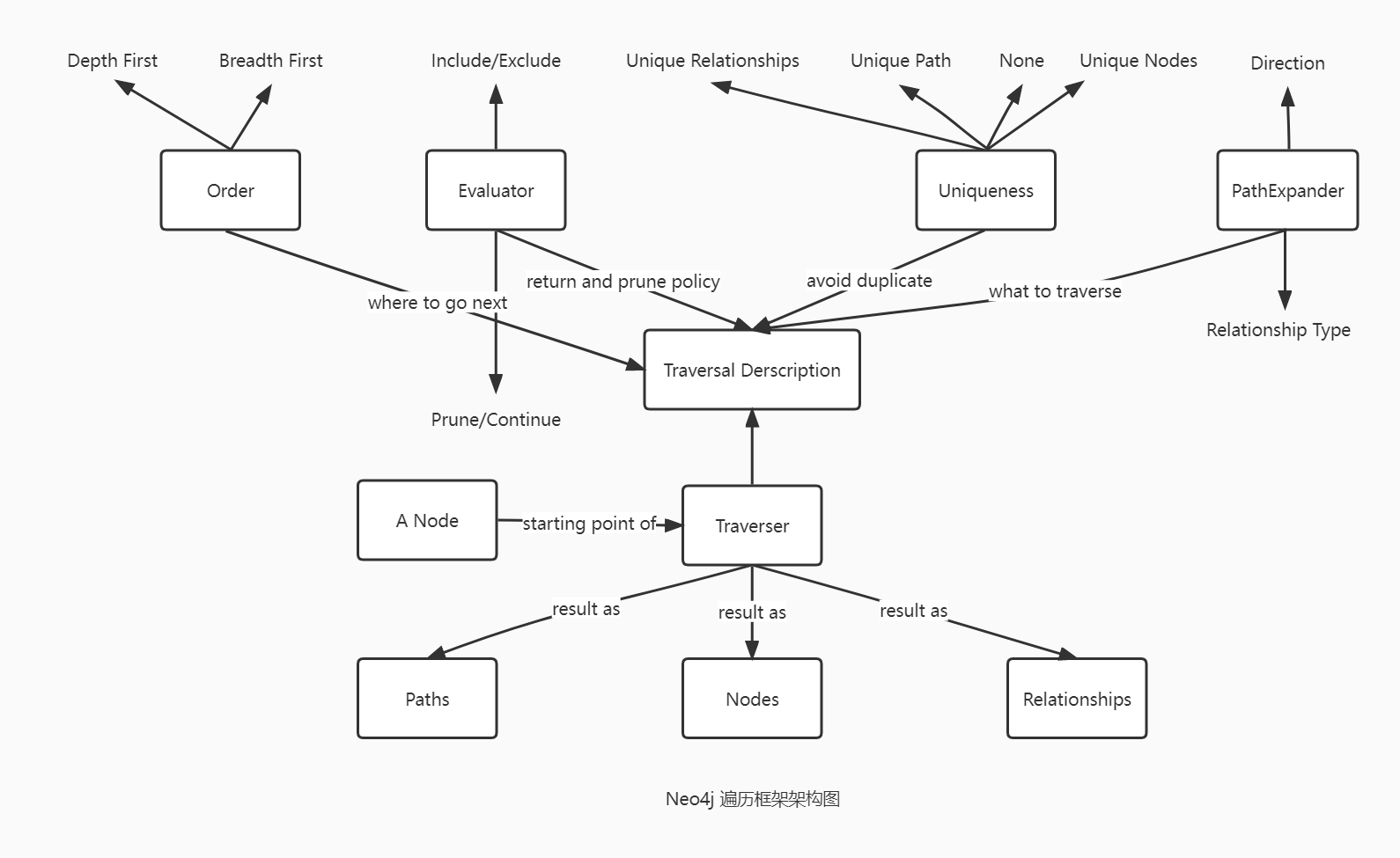
遍历框架的 Java API
遍历框架除了包括节点和关系之外还有几个主要接口:
- 遍历描述接口(
Traversal Description Interface) - 评估器接口(
Evaluator Interface) - 遍历器接口(
Traverser Interface) - 唯一性接口(
Uniqueness Interface)
遍历框架中的路径接口(Path Interface)在遍历中有特殊用途,因为他在评估该位置时用于表示图中的位置。此外路径拓展接口是遍历的核心,但是在使用 API 时很少需要实现它,因为但需要实现它时,还有一组更加高级的接口:branchSelector 、BranchOrderingPolicy 和 TraversalBranch。
遍历描述接口
遍历描述接口(Traversal Description)是用于定义和初始化遍历的主接口。他不必由遍历框架的用户实现,而是由遍历框架的实现来作为用户描述遍历的方式。Traversal Description 实例是不可变的,并且其返回一个新的 Traversal Description 与使用该方法的参数来调用该方法的对象相比,该 Traversal Description 可以被修改。
关系接口
关系(Relationships)接口用于将关系类型添加到要遍历的关系类型列表中。默认情况下,该列表为空意味者他将遍历所有类型的关系。如果一个或者多个关系添加到此列表中,则只会遍历所添加的类型的瓜西。
共有两种遍历方法:
- 包括方向参数,仅遍历指定方向的关系。
- 不包括方向参数,那么将遍历双向关系。
评估器接口
评估器用于在每个位置(路径中的位置)处来确定:如果遍历继续,当前节点是否应包括在结果中。
给定一个路径,遍某个分支的动作可以为以下动作之一:
Evalution.INCLUDE_AND_CONTINUE:在结果中包括此节点并继续遍历。Evalution.INCLUDE_AND_PRUNE:在结果中包括此节点,但不继续遍历。Evalution.EXCLUDE_AND_CONTINUE:在结果中排除此节点,但继续遍历。Evalution.EXCLUDE_AND_PRUNE:在结果中排除此节点,不继续遍历。
可以为遍历器添加多个评估器。但是要注意对于遍历器遇到的所有位置(包括起始节点)都将调用评估器。
遍历器接口
遍历器(Traverser)对象是调用 Traversal Description 对象的 traverse() 方法返回的结果,他表示在图中定位的遍历以及结果格式的规范。每次调用 Traverser 的 next() 方法时遍历操作都将被 惰性 地执行一次。
唯一性接口
唯一性是用来设置在遍历期间如何重新访问遍历过地位置的规则,如果未设置,则默认为 NODE_GLOBAL。
可以向遍历描述提供唯一性参数以指示在什么情况下遍历可以重新访问图中的相同位置,目前 Neo4j 可使用地唯一性级别为:
NONE:可以重新访问图中的任何位置。NODE_GLOBAL:整个图中的任何一个节点都不可能被访问多次。RELATIONSHIP_GLOBAL:整个图中的任何一个关系都不可能被访问多次。NODE_PATH:节点不会先前出现在达到他的路径中。RELATIONSHIP_PATH:先前在达到他的路径中不会存在关系边。NODE_RECENT:类似于NODE_GLOBAL唯一性,存在受访节点地全局集合,每个位置被检查。RELATIONSHIP_RECENT:类似于NODE_RECENT唯一性,但它指的是关系而不是节点。
深度优先/广度优先就是用于设置深度优先/广度优先 BranchSelector 排序策略地遍历方法。同样的结果可以通过从 BranchOrderingPolicies 中调用带有排序策略地 order 方法来实现,也可以编写自己的 BranchSelector / BranchOrderingPolicy 来实现排序。
遍历顺序
遍历顺序是指在遍历过程中按照什么顺序来遍历图的各个分支。
分支选择器
BranchSelector / BranchOrderingPolicy 用于选择下一次的遍历分支,这用于实现遍历排序。遍历框架提供了一些基本的排序实现:
BranchOrderingPolicies.PREORDER_DEPTH_FIRST:深度优先遍历,在访问其子节点之前访问每个节点。BranchOrderingPolicies.POSTORDER_DEPTH_FIRST:深度优先遍历,在访问其子节点后访问每个节点。BranchOrderingPolicies.PREORDER_BREADTH_FIRST:广度优先遍历,在访问其子节点之前访问每个节点。BranchOrderingPolicies.POSTORDER_BREADTH_FIRST:深度优先遍历,在访问其子节点后访问每个节点。
广度优先遍历比深度优先遍历需要更高的内存开销。
BranchSelectors 具有状态属性,因此需要每次遍历唯一地实例化这个类。它通过 BranchOrderingPolicy 接口提供给 Traversal Description,BranchOrderingPolicy 接口是 BranchSelectors 实例的工厂。
分支遍历策略
一个用于创建 BranchSelectors 的工厂,用于决定返回分支的顺序(其中分支的位置表示为从起始节点到当前节点的路径)。常见的策略是深度优先和广度优先,这也就是为什么有更方便的方法。
1 | description.order(BranchOrderingPolicies.PREORDER_DEPTH_FIRST); |
分支选择器(
BranchSelector)BranchSelector用来从某个分支获取更多分支。本质上就是路径(Path)和关系拓展器(RelationshipExpander)的复合,可以用来从当前的一个分支获得新的TraversalBranches。遍历路径
Path是一个通用接口,在Neo4j API中使用Paths可以进行双向的的遍历。遍历器可以将图中被标记为返回的、被访问位置的、路径的形式返回其结果。Path对象也用来评估图中的位置,用于确定遍历是否应当从某个点继续,以及是否应当将某个位置包括在结果集中。路径扩展器
遍历框架使用路径拓展器(PathExpander,路径拓展器用来替换关系拓展器)来发现在遍历中从特定路径到进一步分支应遵循的关系。拓展器
这个是比RelationshipExpander关系更加通用的存在,可以定义要为任何给定节点遍历的所有关系。
Java 中使用遍历框架
使用遍历描述可以生成遍历器。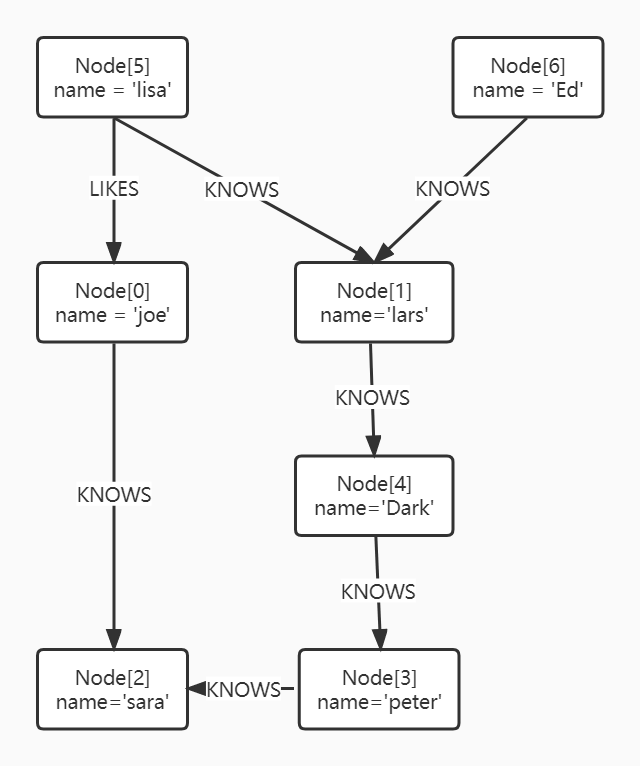
首先定义一个关系类型
1 | public enum Rels implements RelationshipType { |
遍历实例代码
1 | for (Path position : db.traversalDescription() |
由于遍历的描述是不可变的,因此可以创建一个模板米哦啊书来保存由不同遍历共享的公共设置
1 | firendsTraversal = db.traversalDescription() |
现在创建一个新的遍历器,将遍历深度设置在 2 到 4
1 | for (Path path : firendsTraversal |
将遍历器转换为可迭代的节点
1 | for (Node currentNode : firendsTraversal |
使用关系来遍历
1 | for (Relationship relationship : firendsTraversal |
数据索引
在关系型数据库中,索引提供了有序排列数据的方式,使用索引可以像字典一样快速地定位所要查找的记录。在 Neo4j 中索引也可以对指定的属性值进行快速定位查找,与关系数据库有所不同的是 Neo4j 中除了 Cypher,也可以通过 Java 应用程序通过代码来创建索引。
自动索引
参考之前 Cypher 中模式下的索引内容。
手动索引
手动索引操作是 Neo4j 索引 API 的一部分,每个索引都绑定到某个唯一的属性名称上,并且对节点或关系都可以创建索引。
创建索引
如果每个索引在请求时发现并不存在,则系统会自动创建此索引,如果没有给他定义配置参数,则索引将使用默认配置参数创建。
1 | IndexManager index = graphDb.index(); |
如果想要知道某个索引是否已经存在
1 | IndexManager index = graphDb.index(); |
删除索引
索引是可以删除的。删除时,将删除索引的全部内容及其关联配置。删除这个索引之后,可以使用相同的名称创建其索引,这样能保证索引的唯一性。
1 | IndexManager index = graphDb.index(); |
索引的删除实际上实在事务内提交的。如果这个事务被回滚了,那么多索引的删除就是无效的,索引还依然存在。
添加索引
索引支持将任意数量的键值对与任意数量的实体(节点或关系)相关联,也就是说一个创建好的索引可以被赋予在任何数量的节点或关系上。
1 | Node reeves = graphDb.createNode(); |
创建索引后,数据库中的图结构如下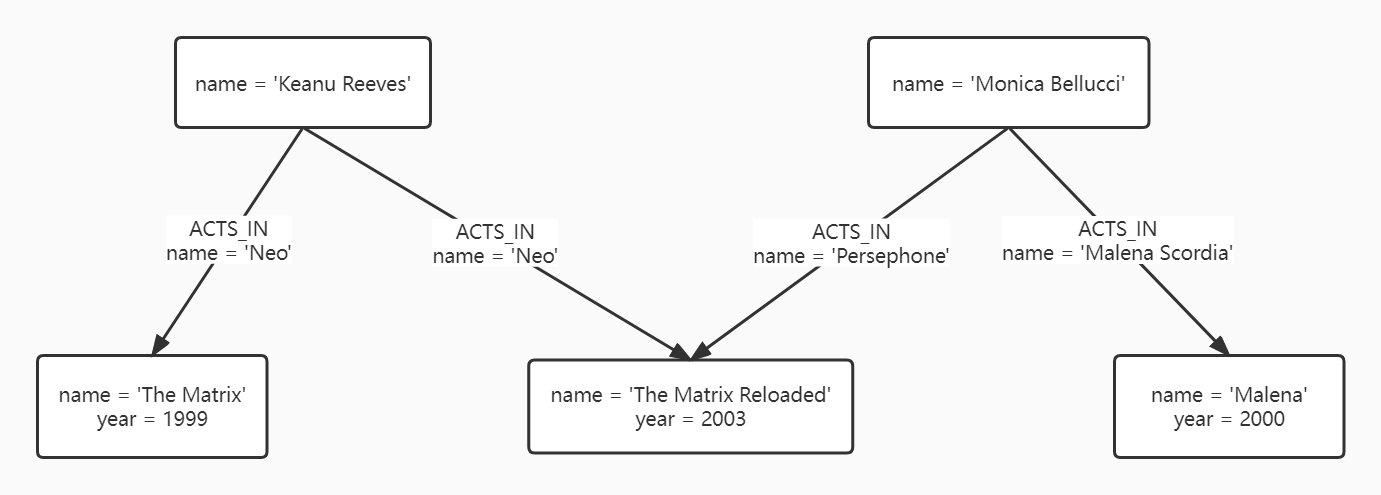
将索引移除
将索引从节点或关系上移除与上面的添加操作类似,移除索引需要制定索引的参数,可以通过提供以下参数组合来完成:
- 实体(节点、索引)
- 实体、索引键名
- 实体、索引键名、索引键值
1
2
3actors.remove(bellucci);
actors.remove(bellucci, "name");
actors.remove(bellucci, "name", "La Bellucci");
更新索引
要更新索引必须删除旧的索引条目,然后再添加新的索引条目。
节点或关系可以与索引中任意数量的键值对关联,这意味着可以使用具有相同键的许多键值对对节点或关系建立索引。当属性值改变想更新索引时,仅仅对新值创建索引是不够的,还必须删除旧值。
1 | // 创建节点 |
节点索引下的查询
节点在创建好索引的情况下,可以通过两种方式查询:get 和 query。get 方法将返回与给定键值对完全匹配的结果。query 方法可以直接使用索引查询更底层功能。
get方法1
2
3// 返回与查询的键值对完全匹配的结果
IndexHits<Node> hits = actors.get("name", "Keanu Reeves");
Node reeves = hits.getSingle();IndexHits是一个Iterator类的继承,它提供了一些特别有用的方法。query方法query方法有两种使用方式,一种使用方式就是提供单一的键值对来匹配查询索引所关联的属性;另一种方式就是提供多个键值对来匹配(可以使用模糊匹配运算符*)。1
2
3
4
5
6
7
8// 单一键值对
for (Node actor : actors.query("name", "*e*")) {
// *e* 为模糊匹配,返回结果为 Reeves 和 Bellucci
}
// 多个键值对
for (Node movie : movies.query("title:*Matrix* AND year:1999")) {
// 返回结果为 1999 年的 The Matrix
}
关系索引下的索引
关系索引下的查询与节点索引类似,但在查询中需要指定所要查询的关系的开始节点或结束节点。这些额外的方法在 RelationshipIndex 接口中,该接口扩展了 Index<Relationship> 接口。
1 | // 以 reeves 作为开始节点的关系,使用单一键值对查询 |
查询特定关系
1 | roles.add(reevesAsNeo, "type", reevesAsNeo.getType().name()); |
结果评分
在查询中特别是模糊匹配查询中,我们需要得到结果集中每个结果的匹配相似度,这就需要评分实现。
1 | IndexHits<Node> hits = movies.query("title", "The*"); |
索引配置和全文索引
在创建索引时,可以配置索引的一些属性来控制索引的行为。
1 | // 创建 Lucene 全文索引 |
Lucene 索引的其他特性
数值范围
当对数值型数据创建索引时,Lucene支持针对数值的智能索引。首先需要使用ValueContext方法标记一个值,使其被当作一个数值来创建索引,然后可以按照范围进行查询。1
2
3
4movies.add(theMatrix, "year-numeric", new ValueContext(1999).indexNumeric());
movies.add(theMatrixReloaded, "year-numeric", new ValueContext(2003).indexNumeric());
movies.add(malena, "year-numeric", new ValueContext(2000).indexNumeric());
hits = movies.query(QueryContext.numericRange("year-numeric", 1997, 1999));Lucene排序Lucene索引具有优秀的排序功能,通过QueryContext类就可以实现。1
2
3
4
5
6
7
8
9
10
11
12
13hits = movies.query("title", new QueryContext("*").sort("title"));
for (Node hit : hits) {
// 按照 title 排序
}
hits = movies.query("title", new QueryContext("title:*").sort("year", "title"));
for (Node hit : hits) {
// 按照 year 排序然后再按照 title 排序
}
// 也可以按照匹配的相似度(分数)对结果进行排序
hits = movies.query("title", new QueryContext("The*").sortByScore());
for (Node hit : hits) {
// 按照相似度排序
}使用
Lucene查询对象进行查询
可以通过编程方式实例化这些查询并作为参数传入,而不是传递Lucene查询语法查询。(TermQuery基本上与在索引上使用get方法是一样的)1
2
3
4
5
6Node actor = actors.query(new TermQuery(new Term("name", "Keanu Revves"))).getSingle();
// 使用 Lucene 查询对象执行通配符搜索
hits = movies.query(new WildcardQuery(new Term("title", "The Matrix*")));
for (Node movie : hits) {
System.out.println(movie.getProperty("title"));
}复合查询
Lucene支持在同一查询中查询多个术语。但是复合查询无法对已经创建索引条目和尚未创建索引条目的属性同时进行搜索。1
hits = movies.query("title:*Matirx* AND year:1999");
操作符
查询中的默认关系运算符(AND或OR)也可以通过QueryContext类来更改行为:1
2QueryContext query = new QueryContext("title:*Matrix* AND year:1999").defaultOperator(Operator.AND);
hits = movies.query(query);
事务管理
为了完全保持数据完整性并确保良好的事务行为,Neo4j 支持 ACID 即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)四个要素。
特别需要注意以下几点:
- 访问图、索引或者模式的所有数据库操作都必须在事务中执行。
- 默认访问级别为
READ_COMMITTED。 - 通过遍历检索的数据不受其他事务的修改保护。
- 可以只有写锁被获取并保持,直到事务结束。
- 可以手动获取节点和关系上的写锁,以实现更高级别的隔离(
SERIALIZABLE)。 - 在节点和关系级别都可以获取锁定权限。
- 死锁检测被构建在核心事务管理中。
交互周期
处理事务的交互周期如下:
- 开始一个事务。
- 执行数据库操作。
- 将事务标记为成功或不成功。
- 完成事务。
事务是被限制在线程内的,可以嵌套为 平行嵌套事务。平行嵌套事务指的是所有嵌套事务都被添加到顶层事务的作用域中。嵌套事务可以标记顶层事务以进行回滚,这意味着整个事务都将被回滚,仅回滚在嵌套事务中的操作是不可能的。
完成每个事务然后提交是很重要的,程序中惯用的方法就是使用 try-finally 块处理事务。首先在 try 块中的最后一个操作应该是标记事务成功即执行 success() 方法,而 finally 块写完成事务的相关操作。完成事务将根据成功状态执行提交或回滚。
在事务中执行的所有修改都会被暂时保存在内存中,所以在遇到大型事务时应将其拆分为小的事务,以避免内存溢出。
隔离级别
Neo4j 中的事务使用读提交隔离级别,也就是一旦事务被提交就可以看到修改,而不会出现在其他事务中看到未提交的数据。另外 Neo4j API 还支持显式锁定节点和关系,通过获取和释放锁可以获得更高级别的隔离。
默认自动加锁的情况
- 在添加、更改或删除节点或关系上的属性时,将对操作的节点或关系执行写锁定。
- 在创建或删除节点时,将为操作的节点执行写锁定。
- 在创建或删除关系时,将对操作的关系及其两个节点执行写锁定。
锁将添加到事务中,并在事务完成时释放。
Cypher中的更新丢失Cypher中在某些情况下可以获取写锁来模拟改进的隔离。例如多个并发Cypher查询增加属性值的情况,由于读提交隔离级别的限制,增加操作的结果可能是无法确定,如果存在直接依赖,则Cypher将在读取前自动获取写锁定。直接依赖关系是指SET的右侧在表达式中读取依赖属性或者在map字面值的键值对的值中。
然而在某些情况下判断读写依赖太过于复杂,可以在某些情况下Cypher不会自动加上写锁定。- 在读取请求的值之前,通过写入虚拟属性来获取节点的写锁定。
1
MATCH (n) WITH n.prop as p SET n.prop = k + 1
- 在同一查询中读取和写入的属性之间的循环依赖性。
1
MATCH (n) SET n += {propA: n.propB + 1, propB: n.propA + 1}
为了在复杂情况下确保行为的确定性,有比远哦在所操作的节点上显式获取写锁定。虽然在
Cypher中没有明确的支持,但是可以通过写入一个临时属性来解决这个限制就可以了。- 在读取请求的值之前,通过写入虚拟属性来获取节点的写锁定。
死锁
在任何系统中只要使用了锁,那么就会遇到死锁,然而在 Neo4j 中有在死锁发生异常之前会检查任何死锁的机制,在抛出异常之前,事务被标记为回滚。由事务获取的所有锁仍然被保留着,并在事务完成时释放(finally 块中)。因死锁而导致未能执行的事务之后就由用户在需要时进行重试。
死锁处理程序
在代码中处理死锁首先需要明确以下问题:- 需要进行有限的重试次数,如果达到阈值则失败。
- 在每次尝试之间暂停一下,以允许其他事务完成,然后再次尝试。
- 重试循环不仅可以用于死锁,也可以用于其它类型的瞬态错误。
使用
TransactionTemplate处理死锁,他将帮助我们实现所需要的处理。
1
2
3
4
5
6
7// 定义基本模板
TransactionTemplate template = new TransactionTemplate().retries(5).backoff(3, TimeUnit.SECONDS);
// 指定要使用的数据库和要执行的函数
Object result = template.with(GraphDatabaseService).execute(Transaction -> {
Object result1 = null;
return result1;
});使用循环处理死锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31Throwable txEx = null;
int RETRIES = 5;
int BACKOFF = 3000;
for (int i = 0; i < RETRIES; i++) {
try (Transaction tx = GraphDatabaseService.beginTx()) {
Object result = doStuff(tx);
tx.success();
return result;
} catch (Throwable ex) {
txEx = ex;
if (!(ex instanceof DeadlockDetectedException)) {
break;
}
}
if (i < RETRIES - 1) {
try {
Thread.sleep(BACKOFF);
} catch (InterruptedException e) {
throw new TransactionFailureException("Interrupted", e);
}
}
}
if (txEx instanceof TransactionFailureException) {
throw ((TransactionFailureException) txEx);
} else if (txEx instanceof Error) {
throw ((Error) txEx);
} else if (txEx instanceof RuntimePermission) {
throw ((RuntimeException) txEx);
} else {
throw new TransactionFailureException("Failed", txEx);
}
策略
Neo4j 提供了三个主要的策略来确保唯一性,即单线程策略、获取或创建策略、消极锁策略。这三种策略可以运行在高可用性集群环境和单实例环境。
单线程策略
单线程策略指的是系统中不会存在多个线程去创建同一个实体(节点、关系)。同样,在高可用性集群环境下,外部的单线程也可以在高可用性集群环境和单实例环境。获取或创建策略
获取或创建唯一节点的首选方法就是使用唯一性约束和Cypher。通过使用put-if-absent功能,可以使用手动索引来保证实体唯一性。此时手动索引将是一个锁,并且这个锁仅仅锁定用来保证线程和事务唯一性的最小资源。消极锁策略
虽然消极锁策略也是一个保证唯一性的策略,但Neo4j更推荐使用以上两个策略,如果都不可性再考虑使用消极锁策略。
过程
过程(Procedure)是以 Java 编写然后部署到数据库中的扩展插件,过程可以在 Cypher 中执行。其中用户自定义过程与数据库的存储过程又有本质的区别,用户自定义过程并不是使用 Cypher 创建的数据操作的集合,而是使用 Java API 创建的数据库功能插件。
过程是一种允许 Neo4j 通过编写自定义代码来扩展出更多功能的机制,然后直接通过 Cypher 调用,过程可以接收参数对数据库执行操作并返回相应结果。
通过将打包后的 JAR 文件放到每个独立或者集群服务器的 neo4j-home/plugins 目录下来部署到数据库中,每一个部署完成后的数据库都必须重新启动以使新的过程生效。
过程是扩展 Neo4j 的首选手段,过程提供的功能如下:
- 提供对
Cypher中不可用的功能的访问,例如手动索引。 - 提供对第三方系统的访问。
- 执行全局操作,例如对连接的组件计数或查找密集节点。
- 实现难以用
Cypher明确表达的操作。
调用过程
调用过程需要使用 Cypher CALL 子句。此外过程名必须是唯一指定的。CALL 语句可以是 Cypher 语句中的唯一子句或者可以与其他子句结合,可以在查询中直接提供参数或从关联的参数集中提取参数。
1 | CALL org.neo4j.example.findMaxNodes(1000); |
用户自定义过程
自定义过程通过包含代码本以及任何依赖包的 JAR 包文件(不包括 Neo4j 依赖)进行部署。这些文件应放置在每个独立数据库或集群成员的 plugin 目录中,并在下次重启后生效。
创建新项目
使用Maven创建一个项目,依赖部分中的neo4j范围设置为provided,因为一旦这个过程部署到Neo4j实例中,此依赖将由Neo4j提供。此外还有测试所需要的依赖库Neo4j Harness,一个允许启动轻量级Neo4j实例的应用程序。Neo4j驱动程序,用于发送调用过程的Cypher语句。JUnit一个通用的Java测试框架。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24<dependency>
<groupId>org.neo4j</groupId>
<artifactId>neo4j</artifactId>
<version>${neo4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.neo4j.test</groupId>
<artifactId>neo4j-harness</artifactId>
<version>${neo4j.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.neo4j.driver</groupId>
<artifactId>neo4j-java-driver</artifactId>
<version>1.0-SNAPSHOT</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>编写集成测试
具体步骤就是首先决定程序要做什么,然后写一个测试用例证明他是正确的,最后写一个能够通过测试的过程。1
2
3
4
5
6
7
8
9
10
11
12
13
14public class ManualFullTextIndexTest {
public Neo4jRule neo4j = new Neo4jRule().withProcedure(FullTextIndex.class);
public void shouldAllowIndexingAndFindingANode() throws Throwable {
try (Driver driver = GraphDatabase.driver(neo4j.boltURI(), Config.build().withEncryptionLevel(Config.EncryptionLevel.NONE).toConfig())) {
Session session = driver.session();
long nodeId = session.run("CREATE (p:User {name: 'Brookreson'}) RETURN id(p)").single().get(0).asLong();
session.run("CALL example.index({id}, ['name'])", parameters("id", nodeId));
StatementResult result = session.run("CALL example.search('User', 'name:Brook*')");
assertThat(result.single().get("nodedId").asLong, equalTo(nodeId));
}
}
}自定义过程
完整的示例可以从Github上找到。下面说一下需要注意的地方:- 所有过程都需要使用
@Procedure注解。有写入数据库操作的过程,需要另外添加@PerformsWrites。 - 过程的上下文对象要与过程使用的每个资源对象相同,都需要添加
@Context注解。 - 需要了解过程有关输入和输出的详细信息。
- 所有过程都需要使用
在线备份
以编程方式备份完整或后续增量的数据。
1 | OnlineBackup backup = OnlineBackup.from("127.0.0.1"); |
JMX 监控
为了连续了解 Neo4j 数据库的运行状况,我们可以使用基于 JMX (Java Management Extensions) 报告运行指标,JMX 作为一个为应用程序、设备、系统等植入管理系统的框架,JMX 可以跨越一系列异构操作平台、系统体系结构和网络传输协议,灵活开发无缝集成系统、网络和服务来管理应用。
那么如何使用 JMX 接入 Neo4j 呢?要启用此功能,必须在配置文件中将 com.sun.management.jmxremote 选项取消注释。然后重启 Neo4j 和 JConsole 接着就可以在 JConsole 的面板中找到 neo4j 的进程了。
引用
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!