Neo4j 安装
Neo4j 数据库支持安装部署的操作系统非常广泛,如 Windows、Mac、CentOS、Ubuntu 等操作系统均可安装。
其中可以访问 Neo4j 官方网站 ,找到下载链接,然后下载对应的版本。
Mac
在 Mac 系统自带的 brew 包管理器中可以直接安装 Neo4j。
1 | brew install neo4j |
运行 neo4j
1 | $ neo4j start/stop/restart |
之后即可以在本地访问 http://localhost:7474 来进行下一步的操作。
Windows
在 Neo4j 官方网站下载对应的安装包后双击即可安装。
在安装完成后,首先需要使用管理员身份启动命令行工具,然后导航到 Neo4j 的安装目录下,运行相关的指令即可(指令都是一样的)。
Ubuntu
下载操作系统对应的安装包后,在命令行下将 tar 文件进行解压。
然后修改 conf/neo4j-server.properties 配置文件,将 org.neo4j.server.webserver.address=0.0.0.0 注释字符去掉。
最后,进入到 bin 目录下,运行 Neo4j 指令启动数据库即可。
基本元素及概念
节点(Node)
节点是图数据库中的一个基本元素,用以表示一个实体记录,就像关系数据库中的一条记录一样,在 Neo4j 中节点可以包含多个属性(Property)和多个标签(Label)。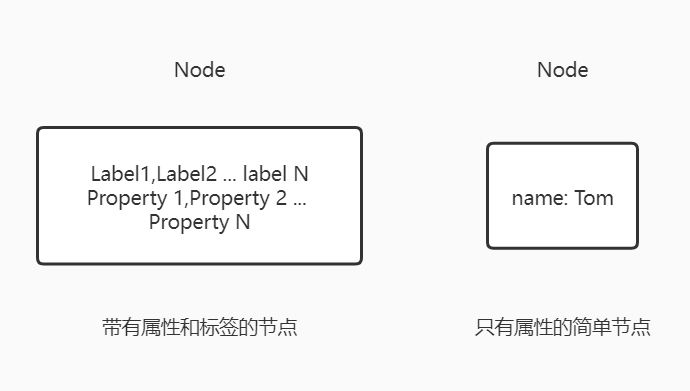
关系(Relationship)
关系同样是图数据中的基本元素。当数据中已经存在节点后,需要将节点连接起来构成图。关系就是用来连接两个节点,关系也称为图的边(Edge),其始端和末端都必须是节点,关系不能指向空也不能由空发起。关系和节点一样可以包含多个属性,但关系只能有一个类型(Type)。

一个节点可以被多个关系指向或作为关系的起始节点。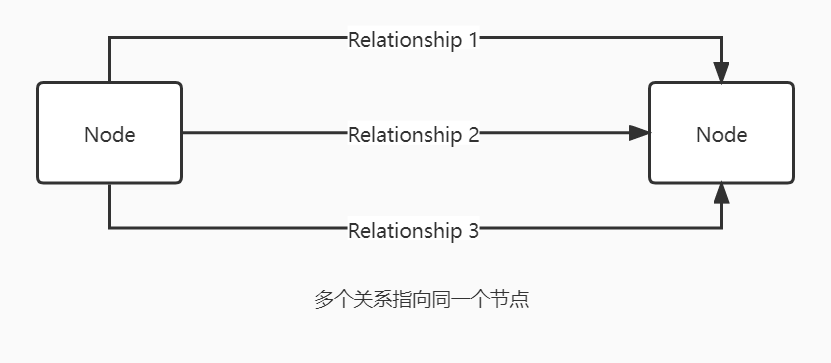
关系必须要开始节点(Start node)和结束节点(End node),两头不能为空。
节点可以被串联或并联起来。由于关系是可以有方向的,所以可以在由节点、关系组成的图中进行遍历操作。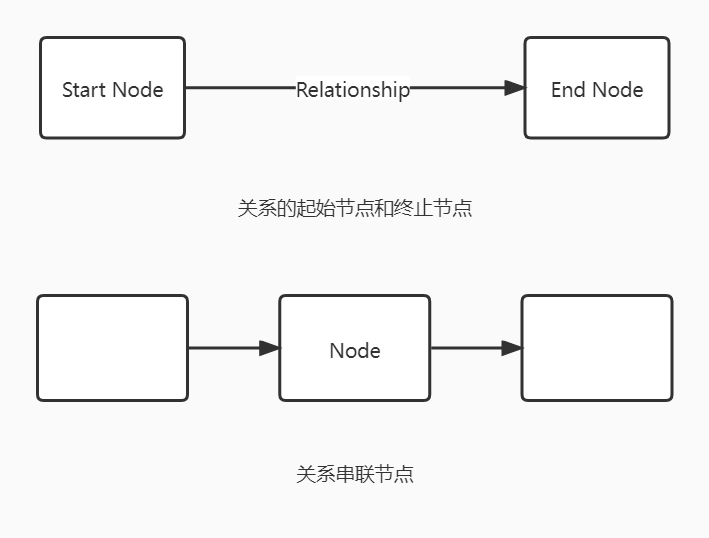
在图的遍历操作中我们可以指定关系遍历的方向或者指定为无方向的,因此在创建关系时不必为两个节点创建相互指向的关系,而是在遍历时不指定遍历方向即可。
特别需要注意的是一个节点存在指向自己的关系。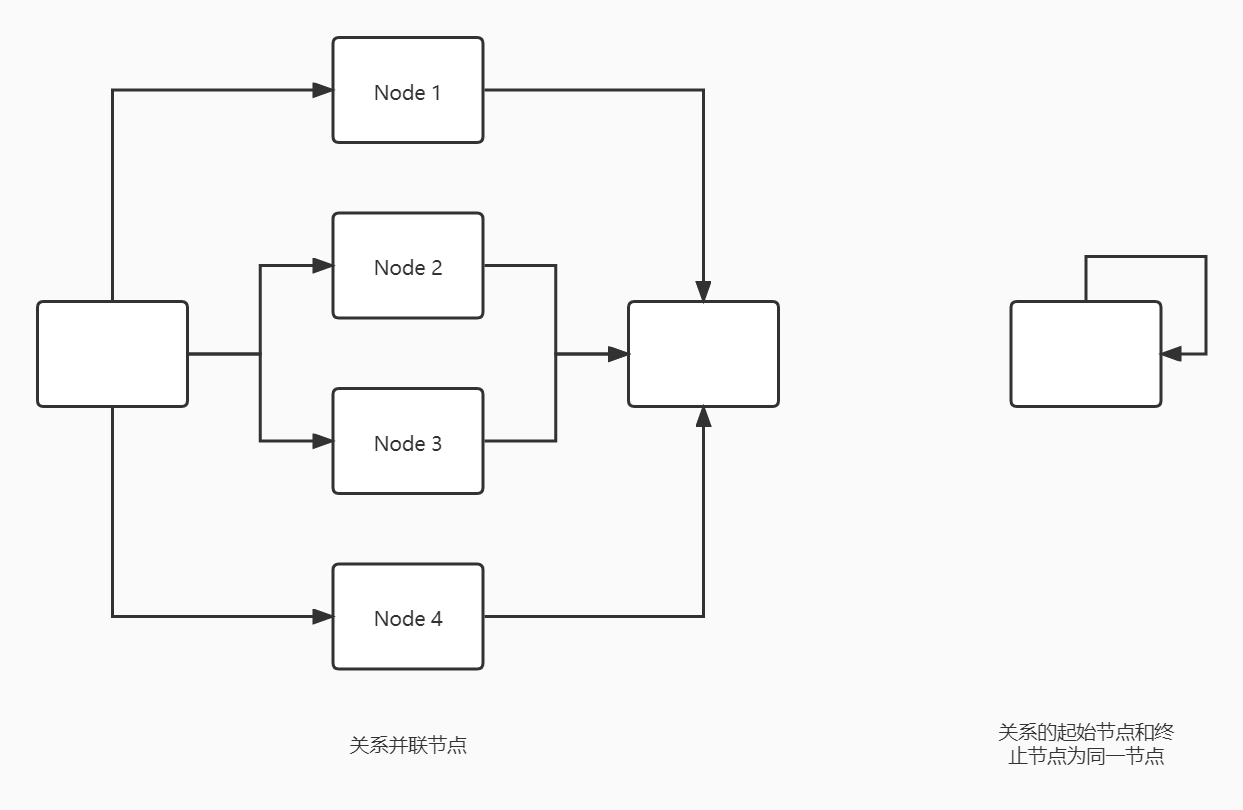
属性(Property)
节点和关系都可以有多个属性。属性由键值对组成,属性名类似于变量名,属性值类似于变量值。属性值可以是基本的数据类型,或者由基本数据组成的数组。
属性值没有 null 的概念,如果一个属性值不需要了,可以将整个键值对都移除,在使用 Cypher 或者 Java API 时可以用 IS NULL 关键字来判断属性是否存在。
路径
当使用节点和关系创建了一个图之后,在此图中任意选择两个节点都是可能存在路径的。
图中任意节点都存在由节点和关系组成的路径,路径也有长度的概念,也就是路径中的关系数。当然也可以说单独一个节点就可以组成长度为 0 的路径。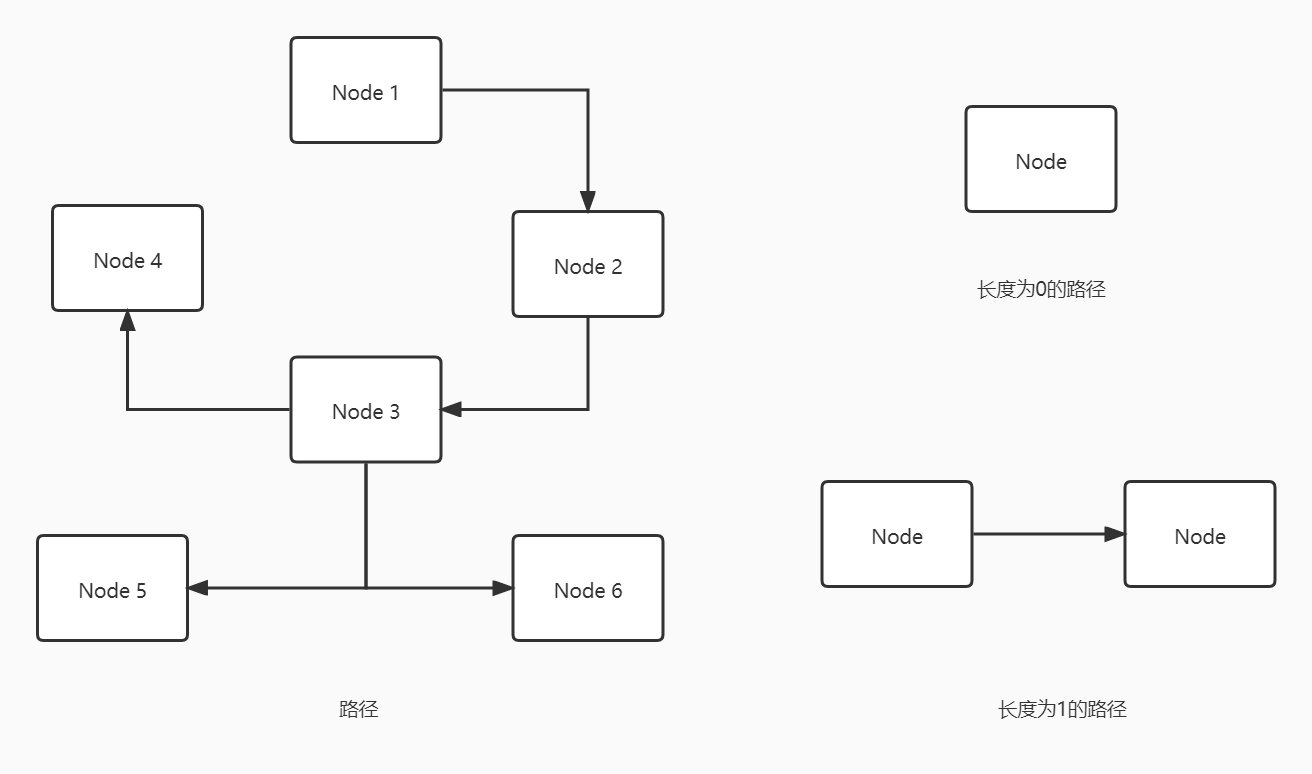
如果是两个简单的节点,中间只存在一个关系,那这条路径的长度就是 1。
遍历(Traversal)
遍历一张图就是按照一定的规则,根据他们之间的关系,依次访问所有的相关联的节点的操作。
遍历规则可以是广度优先也可以是深度优先。
批量工具使用
目前,导入到 Neo4j 的工具有两种:
load csv指令neo4j-import工具
这两种都是基于 CSV 文件的,既然需要 CSV 文件,那么我们就需要考虑一下如何从其他数据库中获取 CSV 文件。
获取 CSV 文件
SQL Server
- 打开一个查询窗口,输入
SQL语句查询出需要导出的数据列表。 - 在查询出来的结果中,复制所有查询出来的数据。然后右键选择“将结果另存为”。
- 之后就可以选择保存为
CSV文件,之后用Excel打开文件就是对应的内容了。
MySQL
MySQL 支持将查询结果直接导出为 CSV 文本格式,在使用 select 语句查询数据时,在语句后面加上导出指令即可,格式如下:
into outfile: 指定导出的目录和文件名。fields terminated by: 定义字段间的分隔符。optionally enclosed by: 定义包围字段的字符(数值型字段无效)。lines terminated by: 定义每行的分隔符。
1 | select * from mytable where mytag like 'E1%' into outfile 'E:/E1.csv' fields terminated by ',' optionally enclosed by '"' lines terminated by '\r\n'; |
此条语句执行后,会讲表中匹配到的数据导出到 E1.csv 文件中。其中每个字段以逗号分隔,字段内容是以双引号包围的字符串,每条记录使用 \r\n 换行。
Oracle
可以使用 sqlplus 导出 CSV 文件,这是一种很方便的方式。
首先需要创建 sqlplus.sql 文件,内容如下:
1 | set colsep , |
然后运行 sqlplus 命令:
1 | sqlplus -s user_naem/passwd@db @spool.sql |
这样就从 Oracle 中将表中的数据导出到 user.csv 文件中。
CSV 内容格式注意事项
CSV 文件内容格式常见错误如下:
- 在
CSV文件开始之处存在BOM字节顺序标记(两个UTF-8字符),如果存在需要删除他们。 - 文件内存在非文本类型的字符,如果存在则删除他们。
- 存在不规则换行符。如混用
Windows和UNIX换行符,如果需要请确保他们一致,最好选择UNIX风格。 CSV文件头与数据不一致,如此情况需要修复头部。- 带引号和不带引号的文本字段中出现换行符,如存在就删除换行符。
- 存在杂散的引号,非文本中存在独立双引号或单引号,如存在就转义或删除杂散引号。
使用 Load CSV 指令导入文件
Neo4j 提供了 Load CSV 命令帮助我们将 CSV 数据文件导入到 Neo4j 中。
简单导入数据
Load CSV 读取但不存入数据:
1 | // 查看前 CSV 文件行数 |
其中 file-url 是文件的地址,可以是本地地址也可以是网址,只要能地址中读出 CSV 文件即可。
对于 RETURN 语句,是用来返回并显示结果到结果显示区的语句。
对于 LIMIT 语句,用来限制返回的行数。
要导入文件到 Neo4j 数据库中需要使用相应的 Create 语句。
1 | LOAD CSV FROM "file-url" AS line |
执行完上述语句,就能在结果显示区看到创建节点的数量。
接着使用以下语句查看数据库是否已经有导入的数据:
1 | MATCH (n:Movie) RETURN n |
此时结果就会在结果展示区展示。
导入 CSV 时附带表头
下面介绍导入 CSV 时附带上表头:
1 | LOAD CSV WITH HEADERS FROM "file-url" AS line |
上述语句使用 WITH HEADERS 子句,它的功能在于导入 CSV 时附带上头部,头部由 line.Id 和 line.Name 制定。
1 | MATCH (n:Track) RETURN n |
在结果展示区就可以看到每个元素都带有 TrackId、Name、Length 头部元素。
导入 CSV 大文件
如果要导入包含大量数据的 CSV 文件,则可以使用 PERODIC COMMIT 子句。
使用 PERODIC COMMIT 指示 Neo4j 在执行完一定行数后提交数据再继续,这样减少了内存开销。
使用 PERODIC COMMIT 默认值为 1000 行,因此数据将每一千行提交一次。
要使用 PERODIC COMMIT,只需在 LOAD CSV 语句之前插入 USING PERODIC COMMIT 语句。
具体使用方法如下:
1 | USING PERODIC COMMIT [line_num] |
使用 neo4j-import 工具导入文件
从 Neo4j 2.2 版本开始,系统自带的一个大数据量的导入工具: eno4j-import,可支持并行、可扩展的大规模 CSV 数据导入。
使用示例:
1 | bin/neo4j-import --into retail.db --id-type string \ |
上述中 --into 子句指明了导入的 Neo4j 数据库名称;--id-type 子句指明了生成节点、关系的主键类型为 string 类型;--nodes: 子句开头的 CSV 文件是节点 csv 文件;--relationships: 开头的是关系 CSV 文件。
引用
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!