简介
随着机器学习与深度学习的发展,DNN 在图像、语音和文本类型的数据上都有了广泛的应用,其优势如下:
- 类似图像、文本,通过对其数据进行编码,从而得到一个表征表格数据。
- 减少对特征工程的依赖(参加过
kaggle竞赛的同学都知道特征在模型中的重要性)。 - 可通过
online learning的方式更新模型。
而在表格类数据的任务中,大部分都是由决策树模型成为标配,其优势如下:
- 可以根据决策树回溯其推理过程,可解释性较强。
- 决策树的流形可以看作是超平面的边界,对于表格类数据的效果很好。
- 训练速度很快。
因此如果有一种模型即吸收决策树模型的可解释性和稀疏特征选择优点,也具有 DNN 的 end-to-end 长处,那毫无疑问就是针对表格数据的利器 - TabNet 。
整体架构
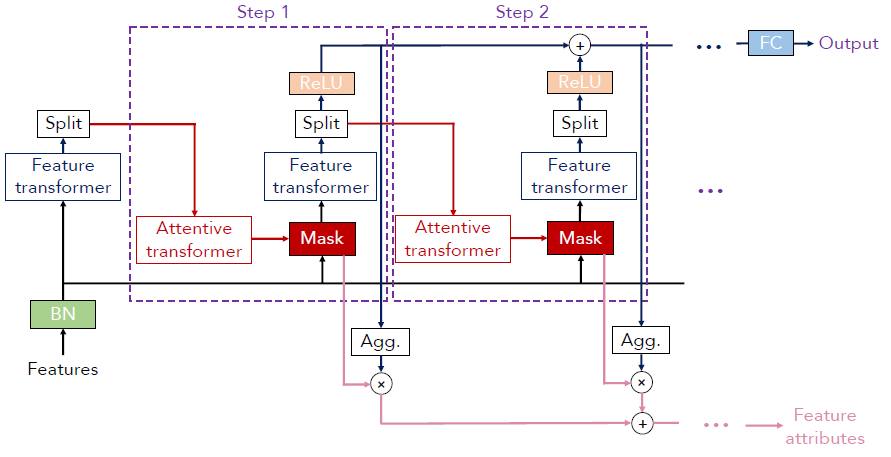
TabNet 整体架构如下图所示:
- 特征首先通过
BatchNorm层,才能作为其他阶段的输入。 - 网络中存在重复的结构
Step,各个Step的输入均是BN层的输出。 Step中包含两个最重要的组件Feature transformer与Attentive trandformer,该两个组件均有BN层、FC层组成,其内部的堆叠个数可作为超参数进行配置。Feature transformer特征处理,其输出经过一个分裂Split部分,一部分经由ReLU之后得到输出;另一部分作为Attentive transformer的输入。Attentive transformer权重系数特征选择,其输出得到Mask稀疏掩码矩阵。- 各个
Step输出求和后,同时经过FC层变换映射得到模型的最终输出。 Mask稀疏掩码矩阵输出累加之后构成Feature attributes,其用于模型的可解释性。
具体模块
特征处理
特征处理组件 Feature transformer 其被设计成串行的方式,网络结构如下图所示:
Shared across decision steps各个Step共享层,即在各个Step中都是被共享的。Decision step dependent各个Step独立层,即在每层需要单独训练。
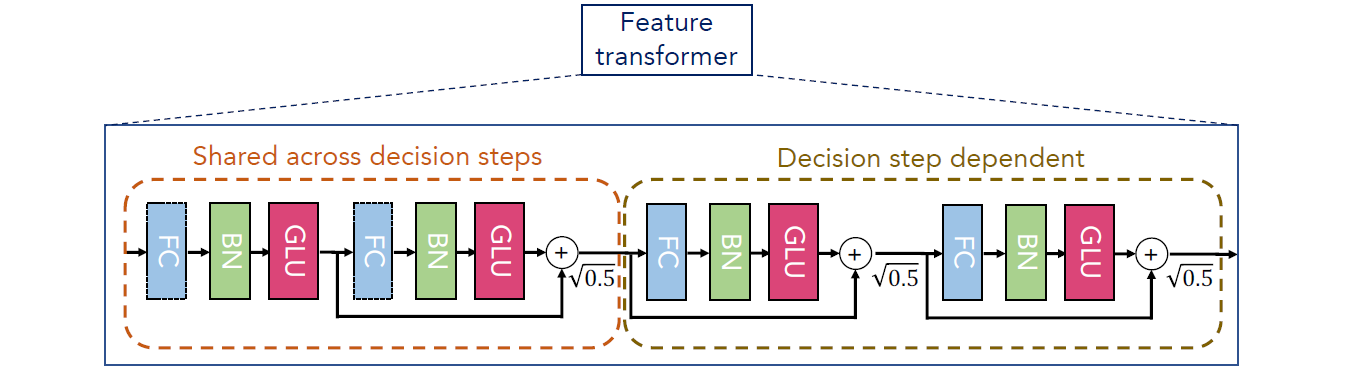
通过图中的网络结构可以将 FC、BN、GLU 看作一个 block。
其中 GLU(Gated Linear Unit) 是广义线性单元,其完成的变换如下:$GLU(a,b)=a \otimes \sigma (b)$,即输入两个相同 shape 的矩阵,b 矩阵经 $\sigma$ 变换后,与 a 矩阵中对应的元素相乘。GLU 层的源码如下:
1 | class GLU_Layer(torch.nn.Module): |
各个 block 通过跳层连接 skip-connection 后,再乘以 $\sqrt{0.5}$,用于防止网络中输出的方差变换波动太大,影响学习的稳定性。
最后 Feature transformer 在完成计算后需要经过 Split 分裂成两部分,其分别是:
d[i]:表示第i个Step上用于最终的模型输出。输出维度为 $R^{B*N_d}$,B为BatchSize,$N_d$ 为输出维度,经过ReLU后,用于最终的模型输出。a[i]:表示第i个Step上用于Attentive transformer的输入。输出维度为 $R^{B*N_a}$,用于Attentive transformer的输入。
特征选择
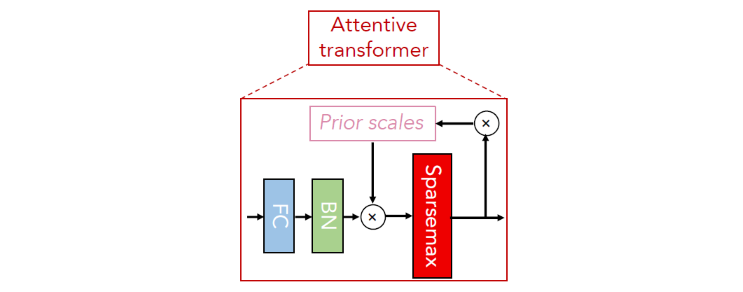
TabNet 的特征选择过程主要为每个 Step 学习一个 Mask 掩码矩阵,记为 $M[i] \in R^{B*D}$,其保持跟输入特征一样的 shape。其网络结构如下:
Mask的计算公式:
网络中存在一个加权缩放因子Prior scales,记为P,其shape与输入特征一致。
当在i时刻,缩放因子与上一时刻Feature transformer的输出a[i-1]的关系为:
$$ M[i] = sparemax(P[i-1] * h_i(a[i-1])) $$
上式中的sparemax是归一化操作,类似于softmax,不过其可以得到更稀疏的输出结果,即只选择最显著的特征,以此达到特征选择的目的。
$h_i(a[i-1]))$ 指图中的FC、BN层。缩放因子的计算公式:
$$ P[i] = _{j=1}^i (\gamma - M[j]) $$
由上述公式可知,对于第i步中的缩放因子与j=0,1...,i步内的Mask[j]有关。
公式中的 $\gamma$ 在不同的取值情况下会有不同的效果:- 当 $\gamma > 1$ 时,由于
M[j]内的取值在[0,1]内且取值集中在0或1附近,特征在后续的Step中可以再次被以更高的权重使用。 - 在
Step = 0时刻 $P[0] = 1^{B * D}$,图中省略了该Mask。
- 当 $\gamma > 1$ 时,由于
Mask的稀疏性:
为了保证Mask的稀疏性,需要对M[i]中要学习的参数进行正则化约束。其约束的方式为:对于网络中所有Step内涉及的Mask的参数 $M_{b,j}$,以如下公式求和作为损失函数的一部分:
$$ L_{sparse} = sum_{i=i}^N sum_{b=1}^B sum_{j=1}^D {\frac {-M_{b,j}[i]} {N * B}} log(M_{b,j}[i] + \epsilon) $$
自监督学习
DNN 可以进行表征学习,而 TabNet 应用自监督学习,通过 encoder-decoder 框架来获得表格数据的 representation,从而也有助于分类和回归任务。如下图所示:

简单来说即认为同一样本之间不同特征是具有关联的,因此自监督学习则是先人为 Mask 一部分特征,然后通过 encoder-decoder 模型来对 Mask 的特征进行预测。
自监督学习的 encoder 部分如上图所示,而 decoder 部分如下所示:
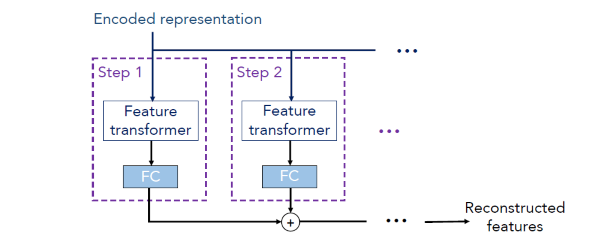
上面的 Encoded representation 就是 encoder 未经 FC 层的加和向量。
将其作为 decoder 的输入,decoder 同样利用 Feature transformer,其将 representation 向量重构为 Feature,之后经过若干个 Step 的加和,得到最后的重构 Feature。
最终输出
TabNet 的最终输出先对各个 Step 中 Feature transformer 的输出进行 ReLU 变换,最终对所有的 Step 中的输出进行求和,经过全连接层,得到最终的输出。即:
$$
\begin{equation}
\begin{split}
d_{out} = sum_{i=1}^N ReLU(d[i]) \\\\
output = FC(d_{out}) = W_{final} d_{out}
\end{split}
\nonumber
\end{equation}
$$
可解释性
结合 TabNet 的网络结构以及中间的组件 Feature transformer 和 Attentive transformer,从这些可以很明显的看出与 MLP 等神经网络的差异。MLP 神经网络中各层对输入特征均是无区别对待,而 TabNet 则是通过 Mask 矩阵来体现各个特征在不同 Step 中的重要性。
示例
1 | from pytorch_tabnet.tab_model import TabNetClassifier |

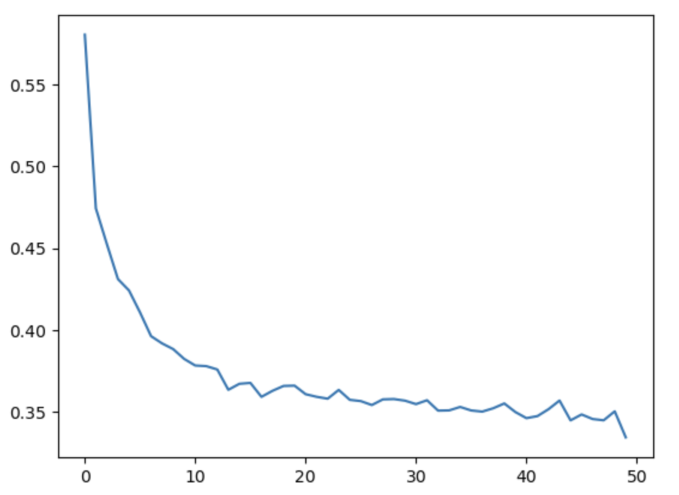
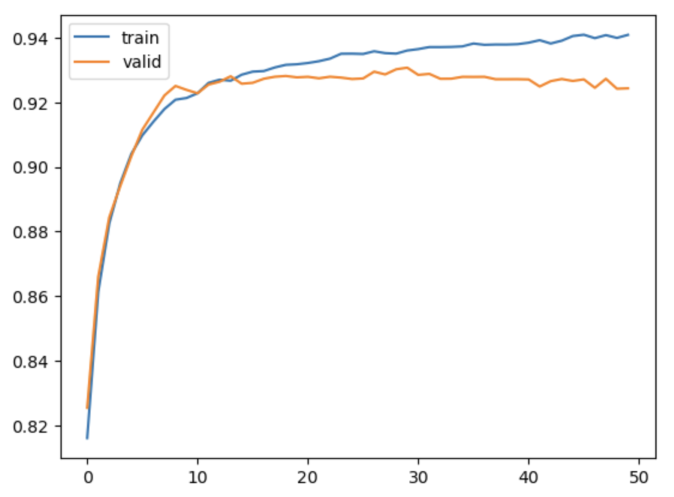

总结
多关注前沿机器学习的内容,会对工作有很大的启发!
引用
TabNet: Attentive Interpretable Tabular Learning
Github 源码
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!