小故事
每个人小时候最讨厌的事情就是吃药了,但不幸的是有一天你得了感冒,妈妈给你买了药,你拿到药后打开了包装纸。在药包里有两种药片,一种是白色的另一种是黑色的,白色的看起来比较甜,而黑色的一看就很苦;因此你决定先吃白色的药片,那么如何一把抓住所有的药片呢?你可以找一个勺子这么把药划分出来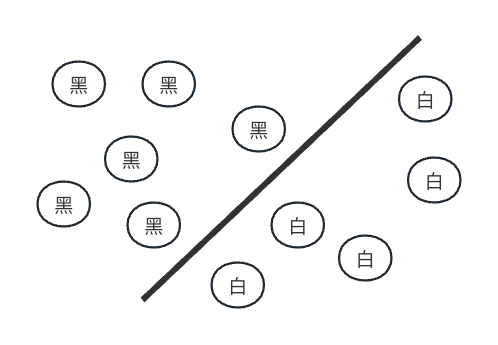
那么如果药包里的药片是这样排布的呢?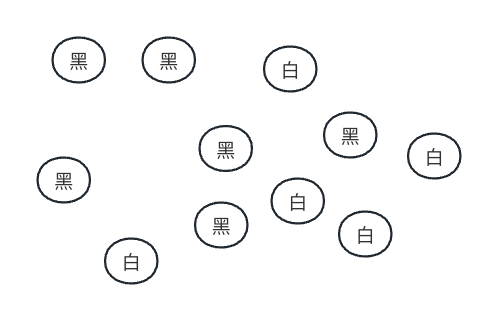
此时你心里想着终于可以祭出我的绝世神功了!哼哈…充满内力的手一拍桌子,药片就飞到了半空中,此时无影手技能发动,你就用一张纸接住了黑色的药片,哈哈哈哈哈哈…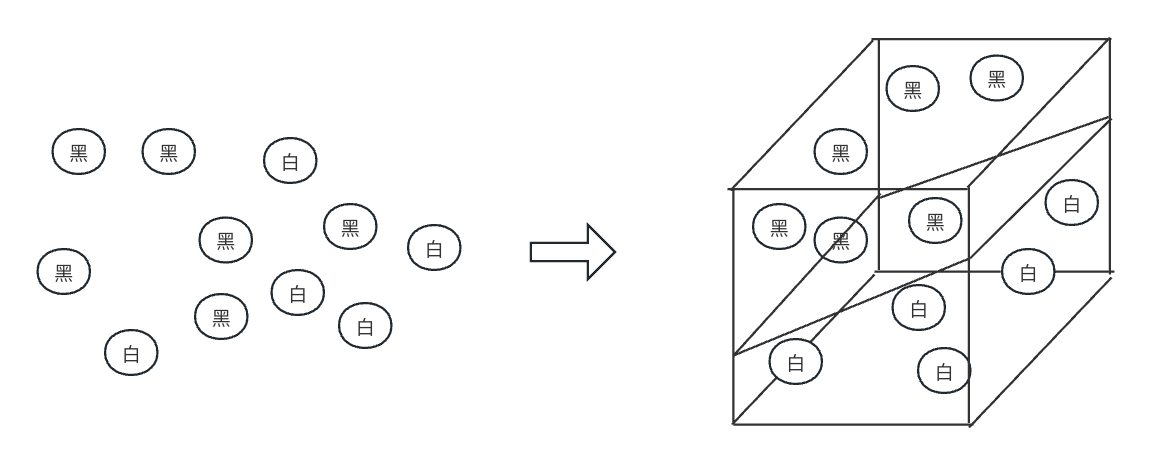
而今天你在学会了 SVM 之后,会将药片成为数据,勺子被称为分类面,找到间隔药片距离最远位置的过程称为优化,而让药片飞到空中的神功称为核映射,在空中分隔药片的纸张称为分类超平面。
概要
支持向量机(support vertor machines, SVM)是一种二类分类模型,其基本模型是定义在特征空间上的间隔最大的线性分类器,其中间隔最大使其有别于感知机;另外支持向量机还包含核技巧,这使其成为本质上的非线形分类器。
支持向量机的学习策略是使得间隔最大化,那么可形成一个求解凸二次规划(convex quadrtic programming)的问题,也就是等价于正则化的合页损失函数的最小化问题,即支持向量机的学习算法就是求解凸二次规划的最优算法。
支持向量机学习方法包含以下模型:
- 线性可分支持向量机(
linear support vector machine in linearly separable case)
当训练数据线性可分时,通过硬间隔最大化(hard margin maximization),学习一个线性的分类器,即线性可分支持向量机,又称为硬间隔支持向量机。 - 线性支持向量机(
linear support vector machine)
当训练数据接近线性可分时,通过软间隔最大化(soft margin maximization),也学习一个线性分类器,即线性支持向量机,又称软间隔支持向量机。 - 非线性支持向量机(
non-linear support vector machine)
当训练数据不可分时,通过使用核技巧(kernal trick)及软间隔最大化,学习非线性支持向量机。
当输入空间为欧式空间或离散集合、特征空间为希尔伯特空间时,核函数(kernal function)表示将输入从输入空间映射到特征空间得到的特征向量之间的内积。通过使用核函数可以学习非线性支持向量机,等价于隐式地在高维的特征空间中学习向量支持机,这样的方法被称为核技巧。
核方法(kernal method)是比支持向量机更为一般的机器学习方法。
线性可分支持向量机
假设给定一个特征空间上的训练数据集
$$ T = {(x_1, y_1), (x_2, y_2), …, (x_N, y_N)} $$
其中 $x_i \in X = R^n, y_i \in Y = \{+1, -1\}, i = 1, 2, …, N, x_i $ 第 $ i $ 个特征向量,也称为实例; $ y_i $ 为 $ x_i $ 的类标记,当 $ y_i = +1 $ 时,称 $ x_i $ 为正例;当 $ y_i = -1 $ 时,称 $ x_i $ 为负例。$ (x_i, y_i) $ 称为样本点。
目前的学习目标是在特征空间中找到一个分离超平面,能将实例分到不同的类。分离超平面对应方程 w·x + b = 0,其由法向量 w 和截距 b 决定,可用 (w, b) 来表示;分离超平面将特征空间划分为两部分,一部分为正类,一部分为负类;法向量指向的一侧为正类,另一侧为负类。
一般当训练数据线性可分时,存在无数个分离超平面可将两类数据正确分开,而感知机使用误分类最小的策略求得分离超平面,不过此时存在无数个解;而线性可分支持向量机利用间隔最大化求得最优分离超平面,即此时存在唯一解。
给定线性可分训练数据集,通过间隔最大化或等价求解相应的凸二次规划问题学习得到的分类超平面为
$$ w^* · x + b^* = 0 $$
以及相应的分类决策函数
$$ f(x) = sign(w^* · x + b^*) $$
称为线性可分支持向量机。
函数间隔和几何间隔
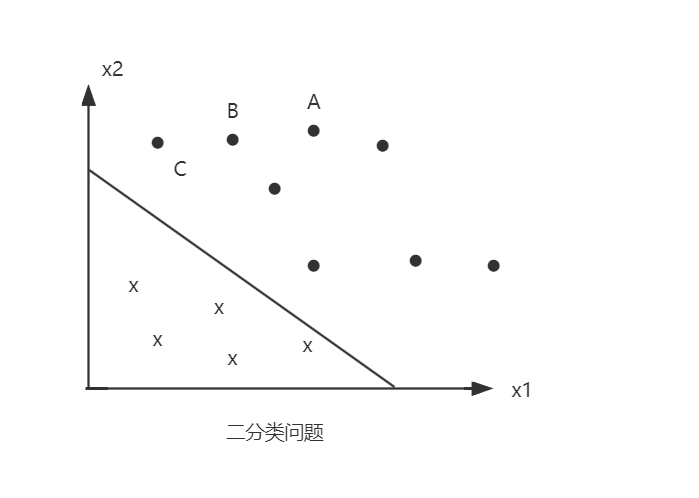
上述图中有 A、 B、 C 三点表示三个实例,其均在分离超平面的正类一侧。点 A 距分离超平面较远,若预测该点为正类则预测正确的概率最大;点 C 距分离超平面较近,则预测该点为正类的概率没有那么大;而点 B 位于 A 和 C 之间,预测其为正类的概率在 A 与 C 之间。
一般地点距离分离超平面的远近可以表示分类预测的正确概率。在超平面 $ w·x + b = 0 $ 确定的情况下,$ |w·x + b| $ 能够相对地表示点 x 距离超平面的远近,而 $ w·x + b = 0 $ 的符号与标记 y 的符号是否一致就能够表示分类是否正确,所以可用量 $ y(w·x + b) $ 来表示分类的正确性及确信度,这就是函数间隔(functional margin)的概念。
函数间隔
对于给定的训练数据集 $T$ 和超平面 $(w, b)$,其定义超平面 $(w, b)$ 关于样本点 $(x_i, y_i)$ 的函数间隔为
$$ \tilde{Y_i} = y_i (w · x_i + b) $$
函数间隔的最小值为
$$ \tilde{Y} = min_{i=1, 2, …, N} \tilde{y_i} $$
函数间隔可以表示分类预测的正确性和准确度。但是在选择分离超平面时,只有函数间隔是不够的,因为只要成比例地改变 w 和 b,虽然分离超平面不会改变,但函数间隔却会成比例改变,因此需要对分离超平面的法向量 w 加以约束,例如规范化 $||w|| = 1$ ,从而使得间隔是确定的,此时函数间隔成为几何间隔(geometric margin)。
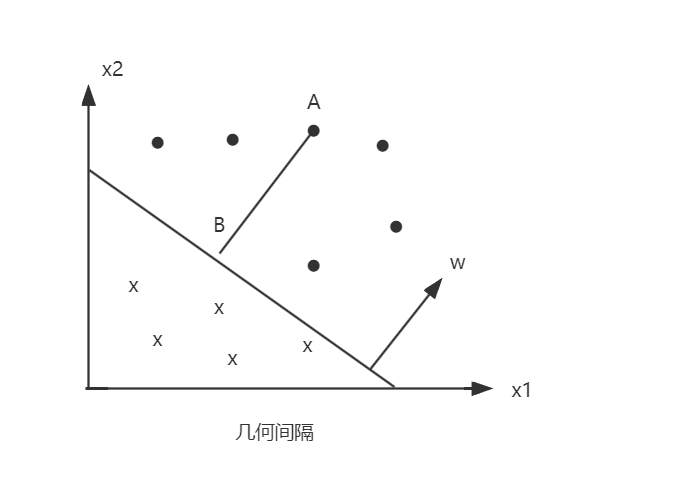
点 A 表示某一个实例 $x_i$,其类标记为 $y_i = +1$。点 A 与超平面 $(w, b)$ 的距离由线段 AB 给出,记作
$$ Y_i = y_i ({\frac {w} {||w||}} · x_i + {\frac {b} {||w||}}) $$
其中 $||w||$ 为 w 的 $L_2$ 范数。
几何间隔
对于给定的训练数据集 $T$ 和超平面 $(w, b)$,其定义超平面 $(w, b)$ 关于样本点 $(x_i, y_i)$ 的几何间隔为
$$ Y_i = y_i ({\frac {w} {||w||}} · x_i + {\frac {b} {||w||}}) $$
几何间隔的最小值
$$ Y = min_{i=1, 2, …, N} y_i $$
超平面 (w, b) 关于样本点 $(x_i, y_i)$ 的几何间隔一般是实例点到超平面的带符号的距离(signed distance),当样本点被正确分类时就是实例点到超平面的距离。
从函数间隔和几何间隔的定义可知 $Y_i = {\frac {\tilde{y_i}} {||w||}}$ 和 $Y = {\frac {\tilde{y}} {||w|}}$,如果 $||w|| = 1$ 那么函数间隔和几何间隔相等。
如果超平面参数 w 和 b 成比例地改变,那函数间隔也会按此比例改变,而几何间隔不变。
间隔最大化
支持向量机学习的基本想法是求解能够正确划分训练数据集并且集合间隔最大的分离超平面。而对于线性可分的训练数据集而言,线性可分的分离超平面有无数个(等价于感知机),但几何间隔最大的分离超平面却是唯一的(硬间隔最大化)。
间隔最大化的直接解释就是:对于训练数据集找到几何间隔最大的超平面意味着以概率最大的确信度队训练数据进行分类。
最大间隔分离超平面
最大间隔分离超平面即几何间隔最大的分离超平面,可以表示为下面的约束最有问题:
$$ max_{w, b} \quad {\frac {\tilde{Y}} {||w||}} $$
$$ s.t. \quad y_i(w·x_i + b) >= \tilde{Y} \quad i=1, 2, …, N$$
几何间隔 $\tilde{Y}$ 的取值并不影响最优化问题的解,即成比例改变 $w, b$,那对应的 $\tilde{Y}$ 也会成比例改变。也就是说会产生一个等价问题,最大化 ${\frac {1} {||w||}}$ 和最小化 ${\frac {1} {2}} {||w||}^2$ 是等价的,由此可得到线性可分支持向量机学习的最优化问题,也是一个凸二次规划问题(convex quadratic progranmming)。
$$ min_{w, b} \quad {\frac {1} {2}} {||w||}^2 $$
$$ s.t. \quad y_i(w·x_i + b) - 1 >= 0 \quad i=1, 2, …, N $$
凸优化问题是指约束最优化问题:
$$ min_{w, b} \quad f(w) $$
$$ \begin{equation}\begin{split}
s.t. \quad g_f(w) <= 0, \quad i=1, 2, …, k \\
h_i(w) = 0, \quad i=1, 2, …, l
\end{split}\nonumber\end{equation}$$
目标函数 $f(w)$ 和约束函数 $g_i(w)$ 都是 $R^n$ 上的连续可微的凸函数,约束函数 $h_i(w)$ 是 $R^n$ 上的仿射函数。当目标函数 $f(w)$ 是二次函数且约束函数 $g_i(w)$ 是仿射函数时,上述凸优化问题就会成为凸二次规划问题。
获得约束最优化问题的解 $w^*, b^*$,可得到最大间隔分离超平面 $w^*·x + b^* = 0$ 及分类决策函数 $f(x)=sign(w^*·x + b^*)$ ,即线性可分支持向量机模型。线性可分支持向量机学习算法-最大间隔法:
输入:线性可分训练数据集 $T = {(x_1, y_1), …, (x_N, y_N)}$,其中 $x_i \in X = R^n,y_i \in Y = \{+1, -1\},i = 1, …, N$
输出:最大间隔分离超平面和分类决策函数
过程:- 构建并求解约束最优化问题
$$ min_{w, b} \quad {\frac {1} {2}} {||w||}^2 $$
$$ s.t. \quad y_i(w·x_i + b) - 1 >= 0, i=1, 2, …, N $$
获取最优解 $ w^*, b^*$ - 由此而得分离超平面和分类决策函数
$$ w^*·x + b^* = 0 $$
$$ f(x) = sign(w^*·x + b^*) $$
- 构建并求解约束最优化问题
支持向量和间隔边界
在线性可分情况下训练数据集的样本点中与分离超平面距离最近的样本点的实例称为支持向量(support vector),即支持向量是使约束条件式($y_i(w·x_i + b) - 1 >= 0$)等号成立的点。
对于 $y_i=1$ 的点,支持向量在超平面 $H_1:w·x+b=1$ 上,而对于 $y_i=-1$ 的点,支持向量在超平面 $H_2:w·x+b=-1$ 上。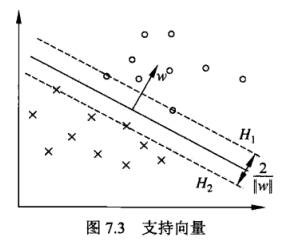
注意到
H1与H2之间平行,但却没有实例点在其中间,即H1与H2中间的长带被称为间隔(margin),间隔依赖于分离超平面的法向量w,等于 ${\frac {2} {||w||}}$,而H1和H2也被称为间隔边界。
对偶算法
为了解决线性可分支持向量机的最优化问题,可将其作为原始问题,应用拉格朗日对偶性,通过求解对偶问题得到原始问题的最优解,这就是线性可分支持向量机的对偶算法。其优点如下:
- 转化为对偶问题更容易求解。
- 自然引入核函数,进而推广到非线性分类问题。
后续的拉格朗日函数内容实在是看不懂,先允许我 TODO 下😁
线性支持向量机
对于线性不可分训练数据集再使用硬间隔最大化来分类是不适用的,需要使用软间隔最大化。
通常情况下,训练数据集中存在一些特异点(outlier),将这些特异点去除后剩下的大部分样本点是可以满足线性可分。而线性不可分的样本点 $(x_i, y_i)$ 也就意味着不能满足间隔大于等于 1 的约束条件,为了解决这个问题,对每个样本点引入一个松弛变量 $ \xi_i >=0$ ,使得函数间隔加上松弛变量大于等于 1,即约束条件和目标函数如下:
$$ y_i(w·x_i + b) >= 1 - \xi_i $$
$$ {\frac {1} {2}} {||w||}^2 + C sum_{i=1}^N \xi_i $$
$C>0$ 被称为惩罚参数,一般由应用问题决定,$C$ 值大时对误分类的惩罚增大,$C$ 值小时对误分类的惩罚减小。
线性不可分的线性支持向量机的学习问题变成了如下的凸二次规划问题:
$$ min_{w, b, \xi} \quad {\frac {1} {2}} {||w||}^2 + C sum_{i=1}^N \xi_i $$
$$ \begin{equation}\begin{split}
s.t. \quad y_i(w·x_i + b) >= 1 - \xi_i, \quad i=1, 2, …, N \\
\xi_i >= 0, \quad i=1, 2, …, N
\end{split}\nonumber\end{equation}$$
上述求解后得到 $w^*, b^*$,就可以达到分离超平面 $w^*·x + b^* = 0$ 及分类决策函数 $f(x)=sign(w^*·x + b^*)$ ,该模型为训练线性不可分时的线性支持向量机,简称为线性支持向量机,其对于现实数据具有更广的适用性。
线性支持向量机学习算法:
输入:训练数据集 $T={(x_1, y_1), …, (x_N, y_N)}$,其中 $x_i \in X = R^n,y_i \in Y = \{+1, -1\},i = 1, …, N$
输出:分离超平面和分类决策函数
过程:
- 选择惩罚参数 $C>0$,构造并求解凸二次规划问题
$$ min_{a} \quad {\frac {1} {2}} sum_{i=1}^N sum_{j=1}^N a_i a_j y_i y_j (x_i · x_j) - sum_{i=1}^N a_i $$
$$ \begin{equation}\begin{split}
s.t. \quad sum_{i=1}^N a_i y_i = 0 \\
0 <= a_i <= C
\end{split}\nonumber\end{equation}$$
求得最优解 $a^* = (a_1^*, a_2^*, …, a_N^*)^T $- 计算 $ w^* = sum_{i=1}^N a_i^* y_i x_i $
选择 $a^*$ 的一个分量 $a_j^*$ 适合条件 $0 <= a_j^* <= C$,计算
$$ b^* = y_j - sum_{i=1}^N y_i a_i^*(x_i · x_j) $$
$a_j^*$ 在实际中取所有符合条件的样本点上的平均值。- 获得分离超平面及分类决策函数
$$ w^*·x + b^* = 0 $$
$$ f(x)=sign(w^*·x + b^*) $$
对偶算法
再允许我 TODO 一下😭
支持向量
在线性不可分的情况下,将对偶问题的解 $a^* = (a_1^*, a_2^*, …, a_N^*)^T$ 中对应的 $a_i^*>0$ 的样本点 $(x_i, y_i)$ 的实例 $x_i$ 称为支持向量(软间隔的支持向量)。
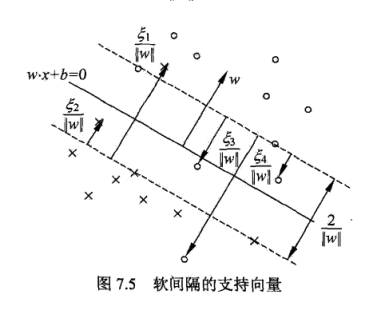
软间隔的支持向量 $x_i$ 在间隔边界上、在间隔边界与分离超平面之间或者在分离超平面误分一侧:
- 若 $a_i^*<C$,则 $\xi_i=0$,支持向量 $x_i$ 恰好落在间隔边界上。
- 若 $a_i^*=C, 0<\xi_i<1$,则分类正确,支持向量 $x_i$ 在间隔边界与分离超平面之间。
- 若 $a_i^*=C, \xi_i=1$,则支持向量 $x_i$ 恰好落在分离超平面上。
- 若 $a_i^*=C, \xi_i>1$,则支持向量 $x_i$ 在分离超平面误分一侧。
非线性支持向量机
对于线性分类问题,有时分类问题是非线性的,此时可以使用非线性支持向量机,其主要适用核技巧(kernal trick)。
核技巧
释义
非线性分类问题是指通过利用非线性模型才能进行分类的问题。一般来说对于给定的训练数据集 $T={(x_1, y_1), …, (x_N, y_N)}$,其中实例 $x_i$ 属于输入空间 $x_i \in X = R^n$,对应的标记有两类 $y_i \in Y = {-1, +1}, i=1,2,…,N$,如果能用 $R^n$ 中的一个超平面将正负例正确分开,则称这个问题为非线性可分问题。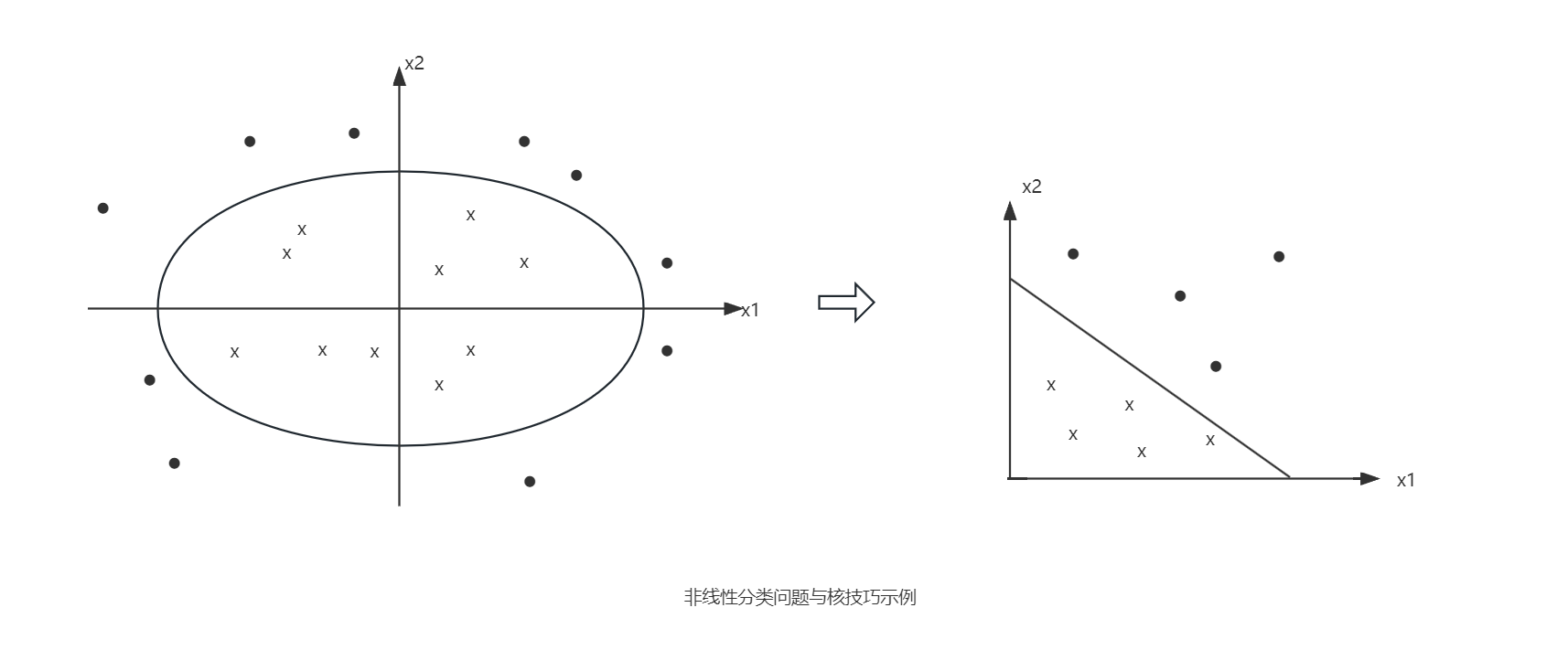
非线性问题往往不好求解,因此希望可以使用线性分类问题的方法来解决问题。而采取的方法就是将非线性问题转换为线性问题,通过转换后的线性问题的求解方法来解决原来的非线性问题。
定义
核技巧的思路是:在学习与预测中只定义核函数 $K(x,z)$ ,而不显示地定义映射函数 $\phi$ ,通常直接计算核函数是比较简单的,而通过映射函数 $\phi(x)$ 和 $\phi(z)$ 计算 $K(x,z)$ 并不简单。并且特征空间 $H$ 一般是高维的,而对于给定的核函数 $K(x,z)$,特征空间 $H$ 和映射函数 $\phi$ 并不唯一,即可以取不同的特征空间,相应的映射函数也可以不同。
$\phi$ 是输入空间 $R^n$ 到特征空间 $H$ 的映射。
设定 $X$ 是输入空间,又设定 $H$ 为特征空间,如果存在一个从 $X$ 到 $H$ 的映射
$$ \phi(x): X -> H $$
使得对所有的 $x,z \in X$,函数 $K(x, z)$ 满足条件
$$ K(x, z) = \phi(x)·\phi(z) $$
则称 $K(x, z)$ 为核函数,$\phi(x)$ 为映射函数,式中 $\phi(x)·\phi(z)$ 为 $\phi(x)$ 和 $\phi(z)$ 的内积。
应用
在线性支持向量机的对偶问题中,无论是目标函数还是分类决策函数(分离超平面)都仅涉及输入实例与实例之间的内积。
因此对偶问题的目标函数中的内积 $x_i·x_j$ 可以用核函数 $K(x_i, x_j) = \phi(x_i)·\phi(x_j)$ 来代替,此时对偶问题的目标函数称为:
$$ W(a) = {\frac {1} {2}} sum_{i=1}^N sum_{j=1}^N a_i a_j y_i y_j K(x_i, x_j) - sum_{i=1}^N a_i $$
类似的,分类决策函数中的内积也可以使用核函数代替,分类决策函数如下:
$$ f(x) = sign(sum_{i=1}^N a_i^* y_i \phi(x_i) · \phi(x) + b^*) = sign(sum_{i=1}^N a_i^* y_i K(x_i, x) + b^*) $$
上述就等价于通过映射函数 $\phi$ 将原来的输入空间变换成一个新的特征空间,将输入空间的内积 $x_i·x_j$ 变换为特征空间中的内积 $\phi(x_i)·\phi(x_j)$,在新的特征空间中学习线性支持向量机。
映射函数为非线性函数时,即学习到含有核函数的支持向量机就是非线性支持向量机。
常用核函数
多项式核函数(
polynomial kernal function)
$$ K(x, z) = (x·z + 1)^p $$
对应的支持向量机是一个p次多项式分类器,分类决策函数如下:
$$ f(x) = sign(sum_{i=1}^N a_i^* y_i (x_i·x + 1)^p + b^*) $$高斯核函数(
Gaussian kernal function)
$$ K(x, z) = exp(-{\frac {(||x-z||)^2} {2a^2}}) $$
对应的支持向量机是高斯径向基函数(radial basis function)分类器,分类决策函数如下:
$$ f(x) = sign(sum_{i=1}^N a_i^* y_i exp(-{\frac {(||x-z||)^2} {2a^2}}) + b^*) $$字符串核函数(
string kernal function)
核函数不仅可以定义在欧氏空间上,还可以定义在离散数据的集合上。字符串核就是定义在字符串集合上的核函数,其在文本分类、信息检索等方面均有应用。
核技巧的具体思路是,在学习与预测中只定义核函数 $K(x, z)$,而不显式定义映射函数,
非线性支持向量机
利用核技巧可以将线性分类问题的学习方法应用于非线性分类问题中,仅需要将线性支持向量机对偶形式中的内积替换成核函数即可。
从非线性分类训练集,通过核函数和软间隔最大化或凸二次规划,学习得到的分类决策函数称为非线性支持向量,$K(x, x_i)$ 是正定核函数。
$$ f(x) = sign(sum_{i=1}^N a^* y_i K(x, x_i) + b^*) $$
非线性支持向量机学习算法:
输入:训练数据集 $T={(x_1, y_1), …, (x_N, y_N)}$,其中 $x_i \in X = R^n, y_i \in Y = \{-1, +1\}, i=1,2,…,N$
输出:分类决策函数
过程:
- 选取适当的核函数 $K(x, z)$ 和适当的参数
C,构造并求解最优化问题
$$ min_a \quad {\frac {1} {2}} sum_{i=1}^N sum_{j=1}^N a_i a_j y_i y_j K(x_i, y_i) - sum_{i=1}^N a_i $$
$$ s.t. \quad sum_{i=1}^N a_i y_i = 0, \quad 0 <= a_i <= C, \quad i=1,2,…,N $$
求得最优解 $a^*=(a_1^*, a_2^*, …, a_N^*)$- 选择 $a^*$ 的一个正分量 $0 < a_j^* < C$,计算
$$ b^* = y_j - sum_{i=1}^N a_i^* y_i K(x_i, y_j) $$- 构造决策函数
$$ f(x) = sign(sum_{i=1}^N a^* y_i K(x, x_i) + b^*) $$
当 $K(x, z)$ 是正定核函数时,最优化问题为凸二次规划问题,其解是存在的。
总结
学习原理知识从来都是非常枯燥乏味的,特别是又长又复杂的数学公式,不过建议你可以去看看具体问题的解决方案,那肯定能给你不少的成就感。
引用
个人备注
此博客内容均为作者学习《统计学习方法》所做笔记,侵删!
若转作其他用途,请注明来源!