数据简介
该数据集最初来自糖尿病/消化/肾脏疾病研究所,此数据集的目标是基于数据集中包含的某些身体指标来诊断性的预测患者是否患有糖尿病。
数据集由多个医学指标和一个目标变量 Outcome 组成,医学指标包含患者的怀孕次数、BMI 指数、胰岛素水平、年龄、血压等。
代码
导入基础依赖
1 | import pandas as pd |
导入数据查看基础信息
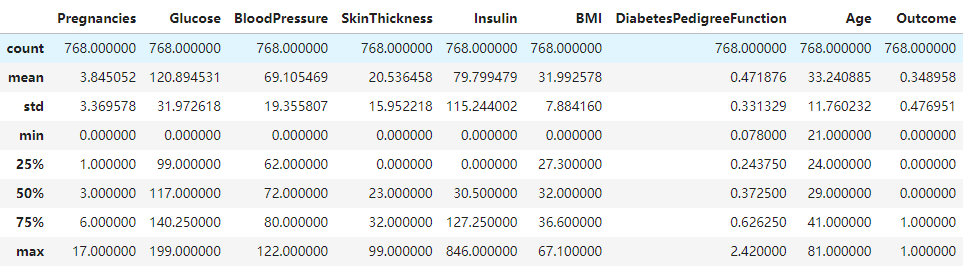
1 | pima = pd.read_csv("diabetes.csv") |
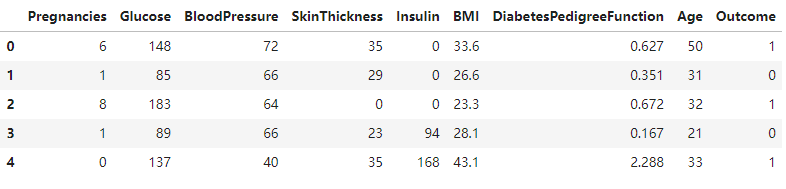
数据可视化
1 | # 柱状图 |
特征预处理
1 | from sklearn.feature_selection import SelectKBest |

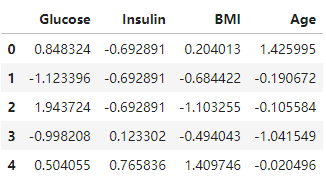
特征标准化
1 | # 将属性值更改为 均值为0,标准差为1 的 高斯分布. 当算法期望输入特征处于高斯分布时,它非常有用 |
数据切分
1 | from sklearn.model_selection import train_test_split |
构建二分类算法模型
1 | from sklearn.model_selection import KFold |

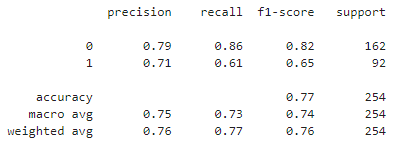
模型评估
1 | from sklearn.svm import SVC |


模型优化
1 | # 使用”网格搜索“来提高模型 - 模型优化 |
要点
评分函数
SelectKBest()
只保留K个最高分的特征,能够返回特征评价的得分。1
SelectKBest(score_func=<function f_classif>, k=10)
SelectPercentile()
只保留用户指定百分比的最高得分的特征,能够返回特征评价的得分。1
SelectPercentile(score_func=<function f_classif>, percentile=10)
使用常见的单变量统计检验:假正率
SelectFpr,错误发现率SelectFdr,或者总体错误率SelectFwe。GenericUnivariateSelect()
通过结构化策略进行特征选择,通过超参数搜索估计器进行特征选择。
cross_val_score() 函数
cross_val_score() 函数,交叉验证评分。
1 | sklearn.cross_validation.cross_val_score(estimator, X, y=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs') |
参数说明:
estimator:数据对象X:数据y:预测数据soring:调用的方法cv:交叉验证生成器或可迭代的次数n_jobs:同时工作的cpu个数(-1代表全部)verbose:详细程度fit_params:传递给估计器的拟合方法的参数pre_dispatch:控制并行执行期间调度的作业数量
KFold 交叉验证
K 折交叉验证,将数据集分成 K 份的官方给定方案,所谓 K 折就是将数据集通过 K 次分割,使得所有数据既在训练集出现过,又在测试集出现过,当然每次分割中不会有重叠,相当于无放回抽样。StratifiedKFold 用法类似 Kfold,但是他是分层采样,确保训练集,测试集中各类别样本的比例与原始数据集中相同。
1 | sklearn.model_selection.KFold(n_splits=3, shuffle=False, random_state=None) |
将训练/测试数据集划分 n_splits 个互斥子集,每次用其中一个子集当作验证集,剩下的 n_splits-1 个作为训练集,进行 n_splits 次训练和测试,得到 n_splits 个结果。
参数说明:
n_splits:表示划分几等份shuffle:在每次划分时,是否进行洗牌- 若为
False时,其效果等同于random_state等于整数,每次划分的结果相同。 - 若为
True时,每次划分的结果都不一样,表示经过洗牌,随机取样的。
- 若为
random_state:随机种子数
注意点:对于不能均等份的数据集,其前 n_samples % n_splits 子集拥有 n_samples // n_splits + 1 个样本,其余子集都只有 n_samples // n_splits 样本。
LeaveOneOut 留一法
LeaveOneOut 留一法,每一回合中,几乎所有的样本都用于训练模型,因此最接近原始样本的分布,这样的评估所得的结果比较可靠。实验过程中,没有随机因素会影响实验数据,确保实验过程是可以被复制的。
但是 LeaveOneOut 也有明显的缺点,就是计算成本高,当原始样本数很多时,需要花费大量的时间去完成算法的运算与评估。
SVC() 函数
1 | sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False,tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None,random_state=None) |
参数说明:
C:C-SVC的惩罚参数C,默认值是1.0。
C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。
C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。kernel:核函数,默认是rbf,可以是linear、poly、rbf、sigmoid、precomputed- 线性:
u'v - 多项式:
(gamma*u'*v + coef0)^degree RBF函数:exp(-gamma|u-v|^2)sigmoid:tanh(gamma*u'*v + coef0)
- 线性:
degree:多项式poly函数的维度,默认是3,选择其他核函数时会被忽略gamma:rbf、poly和sigmoid的核函数参数,默认是auto,则会选择1/n_featurescoef0:核函数的常数项,对于poly和sigmoid有用probability:是否采用概率估计,默认为Falseshrinking:是否采用shrinking heuristic方法,默认为Truetol:停止训练的误差值大小,默认为1e-3cache_size:核函数cache缓存大小,默认为200class_weight:类别的权重,字典形式传递。设置第几类的参数C为weight*Cverbose:是否允许冗余输出max_iter:最大迭代次数,-1为无限制decision_function_shape:ovo、ovr或者None,默认值为Nonerandom_state:数据洗牌时的种子值
主要调节的参数有:C、 kernel、 degree、 gamma、 coef0。
confusion_matrix() 函数
1 | sklearn.metrics.confusion_matrix(y_true, y_pred, labels=None, sample_weight=None) |
参数说明:
y_true:是样本真实分类结果y_pred:是样本预测分类结果labels:是所给出的类别,通过这个可对类别进行选择sample_weight: 样本权重
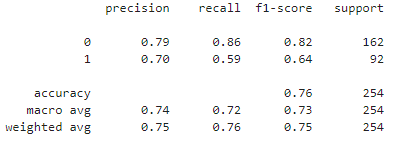
classification_report() 预测准确率
1 | sklearn.metrics.classification_report(y_true, y_pred, *, labels=None, target_names=None, sample_weight=None, digits=2, output_dict=False, zero_division='warn') |
输出说明:
precision: 准确率,TP/ (TP+FP)recall: 召回率,TP(TP + FN)f1-score: 是准确率与召回率的综合,可以认为是平均结果,2*TP/(2*TP + FP + FN)TP: 预测为正,实现为正FP: 预测为正,实现为负FN: 预测为负,实现为正TN: 预测为负,实现为负
GridSearchCV()
GridSearchCV() 可以拆分为两部分 GridSearch 和 CV,即网格搜索和交叉验证。网格搜索,指的是参数,即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数,这其实是一个训练和比较的过程。
1 | sklearn.model_selection.GridSearchCV(estimator, param_grid, *, scoring=None, n_jobs=None, refit=True, cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score=nan, return_train_score=False) |
参数说明:
estimator:选择使用的分类器,并且传入除需要确定最佳的参数之外的其他参数。并且每一个分类器都需要一个scoring参数或者score方法。param_grid:需要最优化的参数的取值,值为字典或者列表。scoring=None:模型评价标准,默认None。这时需要使用score函数,根据所选模型不同,评价准则不同。n_jobs:并行数,-1跟CPU核数一致。
总结
机器学习总体来说不像编程需要很强的计算机基础知识,但额外需要了解业务方面的知识以及对所使用包的熟悉程度,因此还是那句老话“实践出真知”。
引用
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!