简介
分而治之ForkJoin 框架。
ForkJoin 框架是Java7 提供了的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架,这种开发方法也叫分治编程。 分治编程可以极大地利用CPU资源,提高任务执行的效率,也是目前与多线程有关的最新的技术。
ForkJoin 框架
流程图
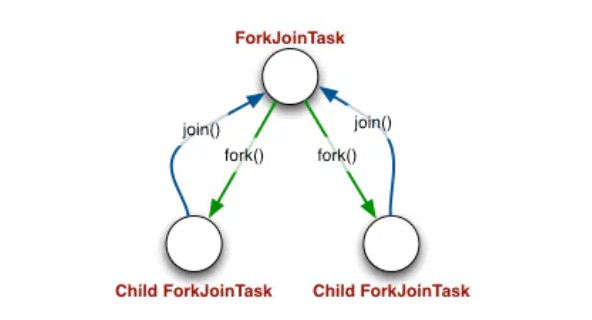
工作窃取算法
ForkJoin 框架使用了工作窃取(work-stealing)算法,工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
- Fork-Join 框架的线程池ForkJoinPool 的任务分为“外部任务” 和 “内部任务”。
- “外部任务”是放在 ForkJoinPool 的全局队列里;
- ForkJoinPool 池中的每个线程都维护着一个内部队列,用于存放“内部任务”。
- 线程切割任务得到的子任务就会作为“内部任务”放到内部队列中。
- 当此线程要想要拿到子任务的计算结果时,先判断子任务有没有完成,如果没有完成,则再判断子任务有没有被其他线程“窃取”,一旦子任务被窃取了则去执行本线程“内部队列”的其他任务,或者扫描其他的任务队列,窃取任务,如果子任务没有被窃取,则由本线程来完成。
- 最后,当线程完成了其“内部任务”,处于空闲的状态时,就会去扫描其他的任务队列,窃取任务。
若一个工作线程的任务队列为空没有任务执行时,便从其他工作线程中获取任务主动执行。为了实现工作窃取,在工作线程中维护了双端队列,窃取任务线程从队尾获取任务,被窃取任务线程从队头获取任务。这种机制充分利用线程进行并行计算,减少了线程竞争。但是当队列中只存在一个任务时,两个线程去取反而会造成资源浪费。
优点
- 线程是不会因为等待某个子任务的完成或者没有内部任务要执行而被阻塞等待、挂起,而是会扫描所有的队列,窃取任务,直到所有队列都为空时,才会被挂起。
- Fork-Join 框架在多CPU的环境下,能提供很好的并行性能。在使用普通线程池的情况下,当CPU不再是性能瓶颈时,能并行地运行多个线程,然而却因为要互斥访问一个任务队列而导致性能提高不上去。而 Fork-Join 框架为每个线程为维护着一个内部任务队列,以及一个全局的任务队列,而且任务队列都是双向队列,可从首尾两端来获取任务,极大地减少了竞争的可能性,提高并行的性能。
缺点
- 当线程窃取任务的时间比线程执行任务所需时间较大时,那就会得不偿失。
核心类
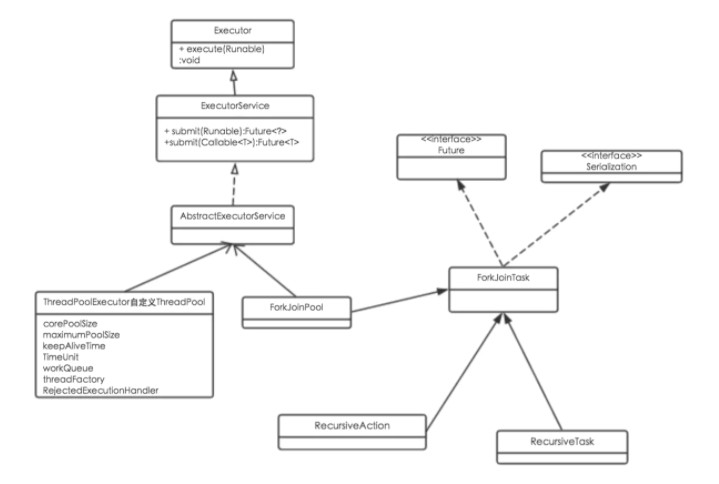
ForkJoinPool
ForkJoinPool 是ForkJoin 框架中的任务调度器,和ThreadPoolExecutor 一样实现了自己的线程池,提供了三种调度子任务的方法:
- execute: 异步执行指定任务,无返回结果。
- invoke、invokeAll: 异步执行指定任务,等待完成才返回结果。
- submit: 异步执行指定任务,并立即返回一个Future对象。
ForkJoinTask
Fork/Join 框架中的实际的执行任务类,有以下两种实现,一般继承这两种实现类即可:
- RecursiveAction: 用于无结果返回的子任务。
- RecursiveTask: 用于有结果返回的子任务。
Demo
1 | public class ForkJoinTest { |
结果输出:
1 | 500000000500000000 |
从结果看出,并行的时间损耗明显要少于串行的,这就是并行任务的好处。
尽管如此,在使用ForkJoin 时也得注意,不要盲目使用。
- 如果任务拆解的很深,系统内的线程数量堆积,导致系统性能性能严重下降。
- 如果函数的调用栈很深,会导致栈内存溢出。
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!