引入
Spark 是用于处理大数据的集群计算框架 ,与其他大多数数据处理框架不同之处在于 Spark 没有以 MapReduce 作为执行引擎,而是使用它自己的分布式运行环境在集群上执行工作。另外 Spark 与 Hadoop 又紧密集成,Spark 可以在 YARN 上运行,并支持 Hadoop 文件格式及其存储后端(例如 HDFS)。
Spark 最突出的表现在于其能将 作业与作业之间的大规模的工作数据集存储在内存中。这种能力使得在性能上远超 MapReduce 好几个数量级,原因就在于 MapReduce 数据都是从磁盘上加载。根据 Spark 的处理模型有两类应用获益最大,分别是 迭代算法(即对一个数据集重复应用某个函数,直至满足退出条件)和 交互式分析(用户向数据集发出一系列专用的探索性查询) 。
另外 Spark 还因为其具有的 DAG 引擎更具吸引力,原因在于 DAG 引擎可以处理任意操作流水线,并为用户将其转化为单个任务。
基础
安装
从官方页面下载一个稳定版本的 Spark 二进制发行包(选择与当前使用 Hadoop 匹配的版本),然后在合适的位置解压文件包,并将 Spark 的解压路径添加到 PATH 中。
1 | tar -xzvf spark-x.y.z.tgz |
作业
Spark 像 MapReduce 一样也有 作业(job)的概念,只不过 Spark 的作业相比 MapReduce 更加通用,因为 Spark 作业可以由任意的多阶段(stages)有向无环图(DAG)构成,其中每个阶段大致相当于 MapReduce 中的 map 阶段或 reduce 阶段。
这些阶段又被 Spark 运行环境分解为多个任务(tash),任务并行运行在分布式集群中的 RDD 分区上,类似于 MapReduce 中的任务。
Spark 作业始终运行在应用(application)上下文中,它提供了 RDD 分组以及共享变量。一个应用可以串行或并行地运行多个作业,并为这些作业提供访问由同一应用的先前作业所缓存的 RDD 的机制。
RDD
RDD 又称弹性分布式数据集(Resilient Distributed Dataset,简称 RDD)是 Spark 最核心的概念,他是在集群中跨多个机器分区存储的一个只读的对象集合 ,在 Spark 应用中首先会加载一个或多个 RDD,他们作为输入通过一系列转换得到一组目标 RDD,然后对这些目标 RDD 执行一个动作。
弹性分布式数据集中的“弹性”是指 Spark 可以通过重新安排计算来自动重建丢失的分区。
RDD 是 Spark 最基本的抽象,RDD 关联着三个至关重要的属性:
- 依赖关系。
- 分区(包括一些位置信息)
- 计算函数:
Partition => Iterator[T]
这三大属性对于简单的 RDD 是不可或缺的,其他更高层的功能也都是基于这套模型构建的。首先,依赖关系列表会告诉 Spark 如何从必要的输入构建 RDD。其次,分区允许 Spark 将工作以分区为单位,分配到多个执行器上并行计算。最后,每个 RDD 都是一个计算函数 compute,可用于生成 RDD 所表示数据的 Iterator[T] 对象。
创建 RDD 共有三种方式:
- 来自一个内存中的对象集合(也称为并行化一个集合)。适用于对少量的输入数据进行并行的
CPU密集型计算。 - 使用外部存储器(例如
HDFS)中的数据集。创建一个外部数据集的引用。 - 对现有的
RDD进行转换。
窄依赖和宽依赖
在对每一个 RDD 操作时,都会得到一个新的 RDD,那么前后的两个 RDD 就有了某种联系,即新的 child RDD 会依赖旧的 parent RDD。目前这些依赖关系被分为: 窄依赖(NarrowDependency)和 宽依赖(ShuffleDependency)。
窄依赖
官方解释为:child RDD中的每个分区都依赖parent RDD中的一小部分分区。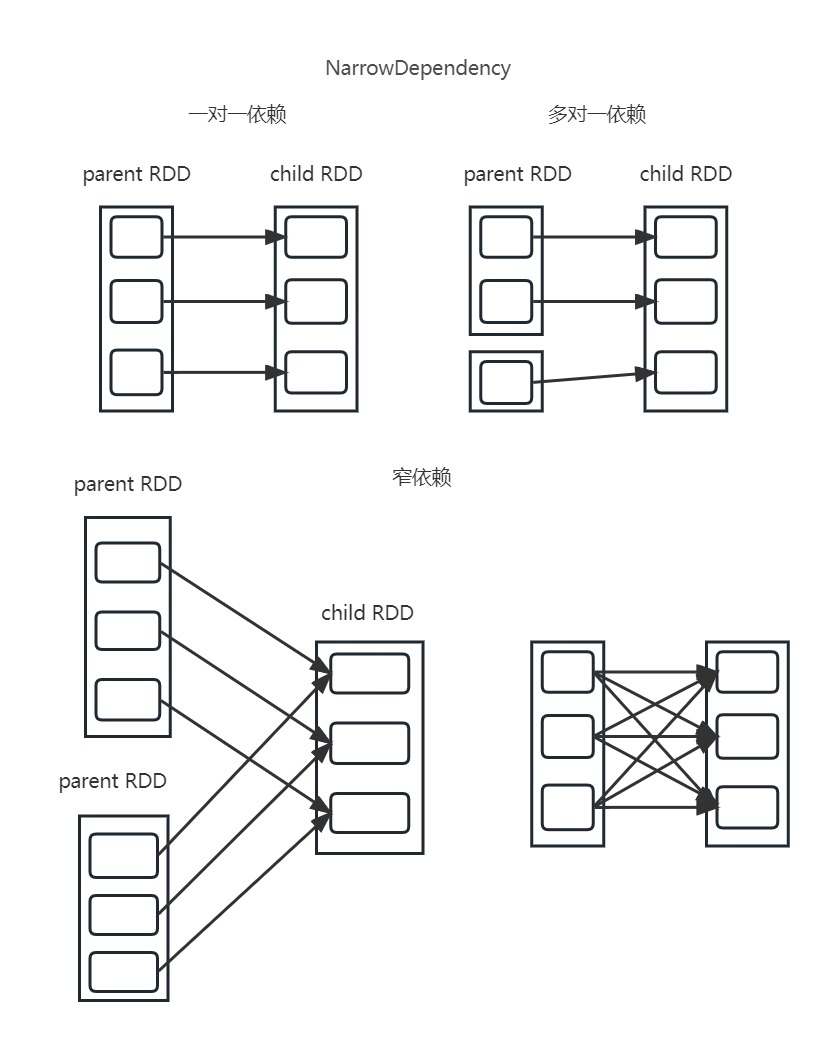
上图包括了有关窄依赖的各种依赖情况:
- 一对一依赖:
child RDD中的每个分区都只依赖parent RDD中的一个分区,并且child RDD的分区数和parent RDD的分区数相同。属于这种依赖关系的转换算子有map()、flatMap()、filter()等。 - 范围依赖:
child RDD和parent RDD的分区经过划分,每个范围内的父子RDD的分区都为一一对应的关系。属于这种依赖关系的转换算子有union()等。 - 窄依赖:窄依赖可以理解为一对一依赖和范围依赖的组合使用。属于这种依赖关系的转换算子有
join()、cartesian()、cogroup()等。
- 一对一依赖:
宽依赖
宽依赖官方解释为需要两个shuffle的两个stage的依赖。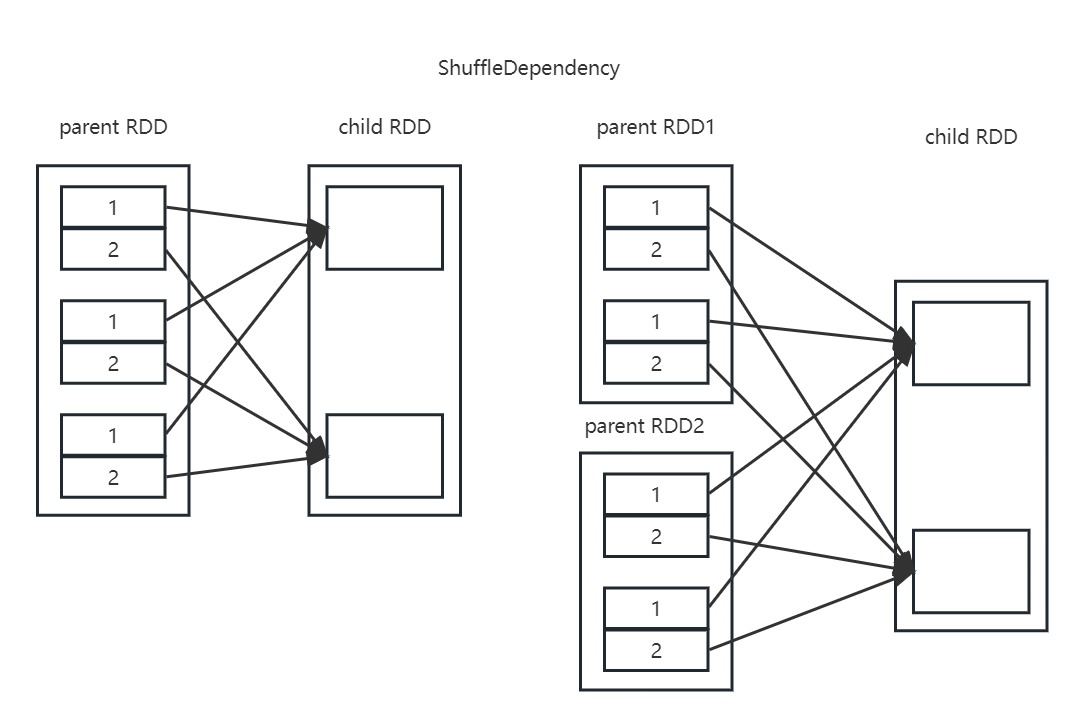
child RDD的一个分区依赖的是parent RDD中各个分区的某一部分,即child RDD的两个分区分别只依赖parent RDD中的部分,而计算出某个部分的过程,以及child RDD分别读取某个部分的过程(shuffle write/shuffle read),此过程正是shuffle开销所在。
转换和动作
Spark 对 RDD 提供了两大操作:转换(transformation) 和 动作(action) 。转换是从现有 RDD 生成新的 RDD,而动作则触发对 RDD 的计算并对计算结果执行某种操作,要么返回给用户,要么保存到外部存储器中。
加载 RDD 或者执行转换并不会立即触发任何数据处理的操作,只不过是创建了一个计划,只有当对 RDD 执行某个动作时才会触发真正的计算。
如果想判断一个操作是转换还是动作,可以通过观察其返回类型:如果返回的类型是 RDD,那么他是一个转换否则就是一个动作。
在 Spark库中包含了丰富的操作,包含映射、分组、聚合、重新分区、采样、连接 RDD 以及把 RDD 作为集合来处理的各种转换,同时还包括将 RDD 物化为集合;对 RDD 进行统计数据的计算;从一个 RDD 中采样固定数量的元素;以及将 RDD 保存到外部存储器等各种动作。
Lineage 机制
相比其他系统的细颗粒度的内存数据更新级别的备份或者 LOG 机制,RDD 的 Lineage 记录的是粗颗粒度的特定数据的 Transformation 操作(如 filter、map、join 等)行为。
当某个 RDD 的部分分区数据丢失时,它可以通过 Lineage 记录获取足够的信息来重新运算和恢复丢失的数据分区,该记录的内容就是前面提到的 RDD 之间的依赖关系。
持久化
Spark 可以在跨集群的内存中缓存数据 ,也就意味着对数据集所做的任何计算都会非常快。相比较而言,MapReduce 在执行另一个计算时必须从磁盘重新加载输入数据集,即使他们可以使用中间数据集作为输入,但也无法摆脱始终从磁盘加载数据的事实,也必然影响其执行速度。
被缓存的 RDD 只能由同一应用的作业来读取。同理,应用终止时,作业所缓存的 RDD 都会被销毁,除非这些 RDD 已经被持久化保存,否则无法访问。
默认的持久化级别共分为两类: MEMORY_ONLY 是默认持久化级别,使用对象在内存中的常规表示方式; MEMORY_ONLY_SER 是一种更加紧凑的表示方法,通过把分区中的元素序列化为字节数组来实现的。MEMORY_ONLY_SER 相比 MEMORY_ONLY 多了一笔 CPU 的开销,但若是生成的序列化 RDD 分区的大小适合被保存在内存中,而默认的持久化方式无法做到,那就说明额外的开销是值得。另外 MEMORY_ONLY_SER 还可以减少垃圾回收的压力,因为每个 RDD 被存储为一个字节数组而不是大量的对象。
默认情况下,RDD 分区的序列化使用的是 Kryo 序列化方法,通过压缩序列化分区可以进一步节省空间,而这通常是更好的选择。
将 spark.rdd.compress 属性设置为 true,并且可选地设置 spark.io.compression.codec 属性。
序列化
在使用 Spark 的序列化时,需要从两个方面来考虑:
- 数据序列化
- 函数序列化(闭包函数)
数据
数据序列化在默认情况下,Spark 在通过网络将数据从一个 executor 发送到另一个 executor 时,或者以序列化的形式缓存(持久化)数据时,所使用的都是 Java 序列化机制。
使用 Kryo 序列化机制对于大多数 Spark 应用都是更好的选择,Kryo 是一个高效的通用 Java 序列化库,要想使用 Kryo 序列化机制,需要在应用中的 SparkConf 中设置 spark.serializer 属性,如下所示:
1 | conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") |
Kryo 不要求被序列化的类实现某个特性的的接口,因此如果旧的对象需要使用 Kryo 序列化也是可以的,在配置启用 Kryo 序列化之后就可以使用了,不过话虽如此,若是使用前可以在 Kryo 中对这些类进行注册,那么就可以提高其性能。这是因为 Kryo 需要写被序列化对象的类的引用,如果已经引用已经注册的类,那么引用标识就只是一个整数,否则就是完整的类名。
在 Kryo 注册类很简单,创建一个 KryoRegistrator 子类,重写 registerClasses() 方法:
1 | class CustomKryoRegistrator extends KryoRegistrator { |
最后在 driver 应用中将 spark.kryo.registrator 属性设置为你的 KryoRegistrator 实现的完全限定类名:
1 | conf.set("spark.kryo.registrator", "CustomKryoRegistrator") |
函数
通常函数的序列化都会谨守本分,对于 Spark 来说,即使在本地模式下,也需要序列化函数,假若引入一个不可序列化的函数,那么应该在开发期间就应该发现。
共享变量
Spark 应用可能会使用一些不属于 RDD 的数据,这些数据会被作为闭包函数的一部分被序列化后传递给下一个动作,这可以保证应用正常执行,但使用广播变量可以跟高效的完成相同的工作。
广播变量
广播变量(broadcast variable)在经过序列化后被发送给各个 executor,然后缓存在那里,以便后期任务可以在需要时访问它。它与常规变量不同,常规变量是作为闭包函数的一部分被序列化的,因此他们在每个任务中都要通过网络被传输一次。
广播变量的作用类似于 MapReduce 中的分布式缓存,两者的不同之处在于 Spark 将数据保存到内存中,只有在内存耗尽时才会溢出到磁盘上。
累加器
累加器(accumulator)是在任务中只能对它做加法的共享变量,类似于 MapReduce 中的计数器。当作业完成后 driver 程序可以检索累加器的最终值。
作业运行机制
在 Spark 作业的最高层,他有两个独立的实体: driver 和 executor 。driver 负责托管应用(SparkContext)并为作业调度任务。executor 专属于应用,他在应用运行期间运行,并执行该应用的任务。通常 driver 作为一个不由集群管理器(cluster manager)管理的客户端来运行,而 executor 则运行在集群的计算机上。
提交
当对 RDD 执行一个动作时,会自动提交一个 Spark 作业。从内部看导致对 SparkContext 调用 runJob() 方法,然后将调用传递给作为 driver 的一部分运行的调度程序。调度程序由两部分组成: DAG 调用程序 和 任务调度程序 。DAG 调度程序把作业分解为若干阶段,并由这些阶段组成一个 DAG。任务调度程序则负责把每个阶段中的任务提交到集群。
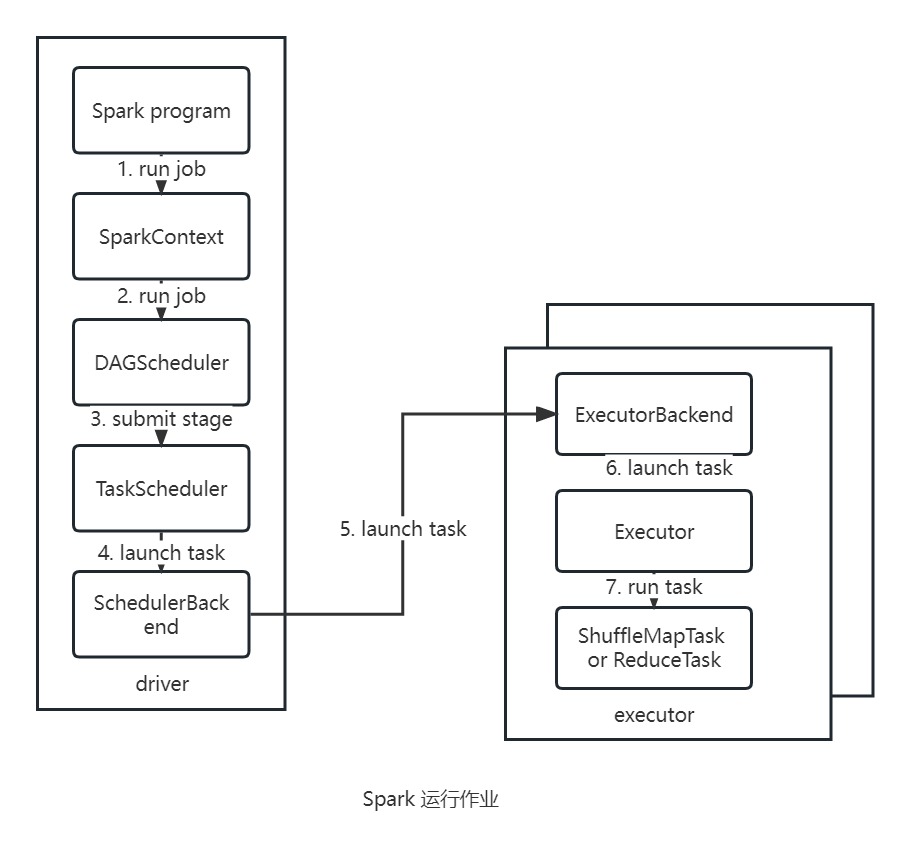
DAG 构建
要想了解一个作业如何被划分为阶段,首先需要了解在阶段中运行的任务的类型。有两种类型的任务: shuffle map 任务 和 result 任务 ,从任务类型的名称可以看出 Spark 会怎样处理任务的输出。
shuffle map任务。
顾名思义shuffle map任务类似于MapReduce中shuffle的map端部分。每个shuffle map任务在一个RDD分区上运行计算,并根据分区函数把输出写入到一组新的分区中,以允许在后面的阶段中取用(后面的阶段可能由shuffle map任务组成,也可能由result任务组成),shuffle map任务运行在除最终阶段之外的其他所有阶段中。result任务。
result任务运行在最终阶段,并将结果返回给用户程序。每个result任务在他自己的RDD分区上运行计算,然后把结果发送回driver,再由driver将每个分区的计算结果汇集成最终结果。
最简单的 Spark 作业不需要使用 shuffle,因此它只有一个由 result 任务构成阶段,就像是 MapReduce 中仅有 map 一样。而比较复杂的作业要涉及到分组操作,并且要求一个或多个 shuffle 阶段。
如果 RDD 已经被同一应用(SparkContext)中先前的作业持久化保存,那么 DAG 调度程序将会省掉一些任务,不会再创建一些阶段来重新计算(或者它的父 RDD)。
DAG 调度程序负责将一个阶段分解为若干任务以提交给任务调度程序。另外 DAG 调度程序会为每个任务赋予一个位置偏好(placement preference),以允许任务调度程序充分利用数据本地化(data locality)。
调度
当任务集合被发送到任务调度程序后,任务调度程序用该应用运行的 executor 的列表,在斟酌位置偏好的同时构建任务到 executor 的映射。接着任务调度程序将任务分配给具有内核的 executor,并且在 executor 完成运行任务时继续分配更多的任务,直到任务集合全部完成。默认情况下,每个任务到分配一个内核,不过也可以通过设置 spark.task.cpus 来更改。
任务调度程序在为某个 executor 分配任务时,首先分配的是进程本地化(process-local)任务,再分配节点本地(node-local)任务,然后分配机架本地(rack-local)任务,最后分配任意(非本地)任务或者推测任务(speculative task)。
这些被分配的任务通过调度程序后端启动。调度程序后端向 executor 后端发送远程启动任务的消息,以告知 executor 开始运行任务。
当任务成功完成或者失败时,executor 都会向 driver 发送状态更新信息。如果失败任务调度程序将在另一个 executor 上重新提交任务。若是启用推测任务(默认情况下不启用),它还会为运行缓慢的任务启动推测任务。
执行
executor 首先确保任务的 JAR 包和文件依赖关系都是最新的,executor 在本地高速缓存中保留了先前任务已使用的所有依赖,因此只有在更新的情况下才会重新下载。接下来由于任务代码是以启动任务消息的一部分而发送的序列化字节,因此需要反序列化任务代码(包括用户自己的函数)。最后执行任务代码,不过需要注意的是因为运行任务在于 executor 相同的 JVM 中,因此任务的启动没有进程开销。
任务可以向 driver 返回执行结果,这些执行结果被序列化并发送到 executor 后端,然后以状态更新消息的形式返回 driver。shuffle map 任务返回的是一些可以让下一个阶段检索其输出分区的消息,而 result 任务则返回其运行的分区的结果值,driver 将这些结果值收集起来,并把最终结果返回给用户的程序。
集群管理
Spark 如何依靠 executor 来运行构成 Spark 作业的任务,负责管理 executor 生命周期的是集群管理器(cluster manager),同时 Spark 提供了多种具有不同特性的集群管理器:
- 本地模式
在使用本地模式时,有一个executor与driver运行在同一个JVM中。此模式对于测试或运行小规模作业非常有用。 - 独立模式
独立模式的集群管理器是一个简单的分布式实现,它运行了一个master以及一个或多个worker。当Spark应用启动时,master要求worker代表应用生成多个executor进程,这种模式的主URL为spark://host:port。 Mesos模式
Apache Mesos是一个通用的集群资源管理器,它允许根据组织策略在不同的应用之间细化资源共享。默认情况下(细粒度模式)每个Spark任务被当作是一个Mesos任务运行,这样做可以更有效地使用集群资源,但是以额外的进程启动开销为代价。在粗粒度模式下executor在进程中运行任务,因此在Spark应用运行期间的集群资源由executor进程来掌管,这种模式的主URL为mesos://host:port。YARN模式
YARN是Hadoop中使用的资源管理器,每个运行的Spark应用对应于一个YARN应用实例,每个executor在自己的YARN容器中运行,这种模式的主URL为yarn-client或yarn-cluster。
YARN是唯一一个能够与Hadoop的Kerberos安全机制集成的集群管理器。
运行在 YARN 上的 Spark
在 YARN 上运行 Spark 提供了与其他 Hadoop 组件最紧密的集成,为了在 YARN 上运行,Spark 提供了两种部署模式: YARN 客户端模式和 YARN 集群模式。YARN 客户端模式的 driver 在客户端运行,而 YARN 集群模式的 driver 在 YARN 的 application master 集群上运行。
对于具有任何交互式组件的程序都必须使用 YARN 客户端模式,在交互式组件上的任何调试都是立即可见的。
另一方面 YARN 集群模式适用于生成作业(production job),因为整个应用在集群上运行,这样更易于保留日志文件(包括来自 driver 的日志文件)以供稍后检查。如果 application master 出现故障,YARN 还可以尝试重新运行该应用。
YARN客户端模式
在YARN客户端模式下,当driver构建新的SparkContext实例时就会启动与YARN之间的交互,该SparkContext向YARN资源管理器提交一个YARN应用,而YARN资源管理器则启动集群节点管理器上的YARN容器,并在其中运行一个名为SparkExecutorLauncher的application master。该ExecutorLauncher的工作是启动YARN容器中的executor,为了做到这一点ExecutorLauncher要向资源管理器请求资源,然后启动ExecutorBackend进程作为分配给它的容器。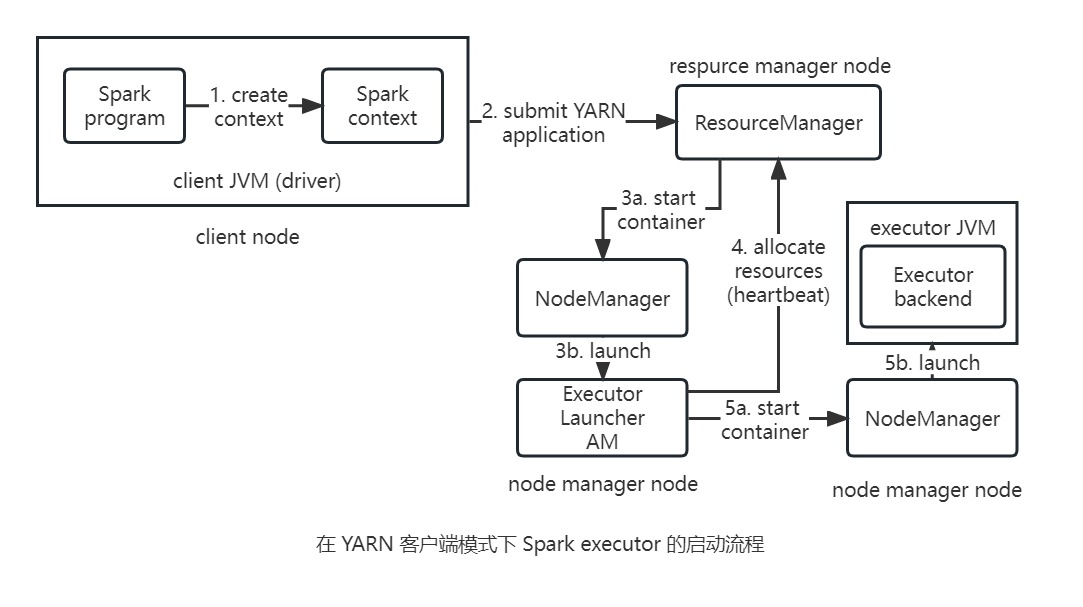
每个
executor在启动时都会连接回SparkContext,并注册自身。因此这就向SparkContext提供了关于可用于运行任务的executor的数量及其位置的信息,之后这些信息会被用在任务的位置偏好策路中。YARN资源管理器的地址并没有在主URL中指定(这与使用独立模式或Mesos模式的集群管理器不同),而是从HADOOP_CONF_DIR环境变量指定的目录中的Hadoop配置中选取。YARN集群模式
在YARN集群模式下,用户的driver程序在YARN的application master进程中运行,spark-submit客户端将会启动YARN应用,但是它不会运行任何用户代码。剩余过程与客户端模式相同,除了application master在为executor分配资源之前先启动driver程序外。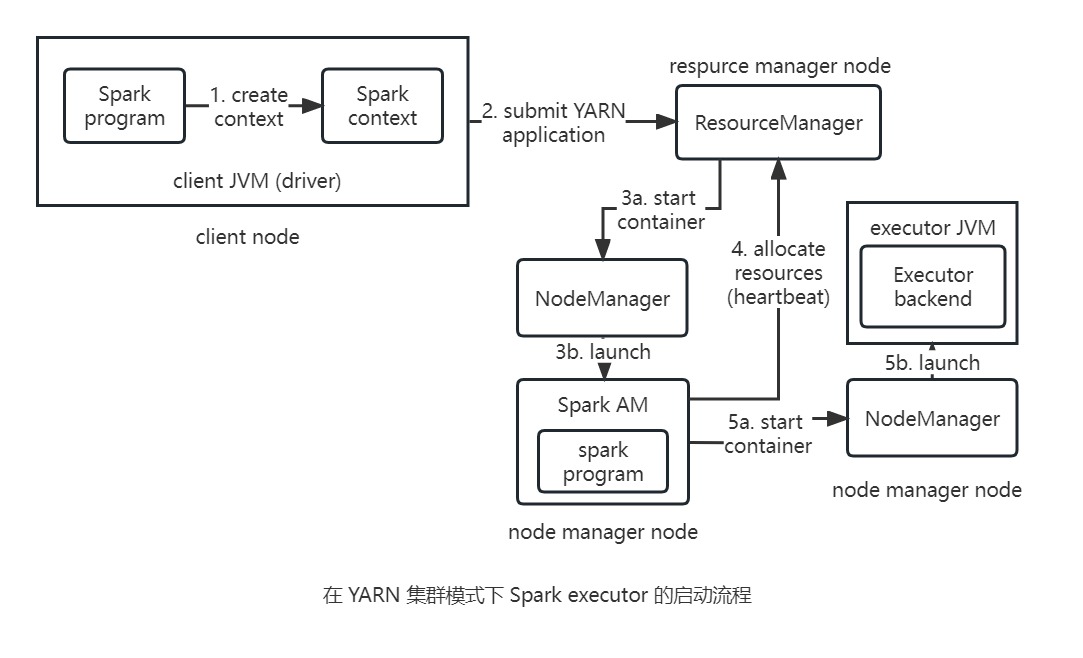
在这两种 YARN 模式下,executor 都是在还没有任何本地数据位置信息之前先启动的,因此最终有可能会导致 executor 与存有作业所希望访同文件的 datanode 不在一起。而这些对于交互式会话是可以接受的,特别是因为会话开始之前可能开不知道需要访问哪些数据集。但是对于生成作业来说情况并非如此,所以 Spark 提供了一种方法,可以在 YARN 群集模式下运行时提供一些有关位置的提示,以提高数据本地性。
sparkContext 构造函数可以使用第二个参数来传递一个优选位置,该优选位置是利用 InputFormatInfo 辅助类根据输人格式和路径计算得到的。因此当向资源管理器请求分配时 application master 需要用到这个优选位置。
数据结构化 DataFrame
Spark 的 DataFrame 是结构化的、有格式的 ,且支持一些特定的操作,就像分布式内存中的表那样,每列都有名字,有表结构定义,每列都有特定的数据类型:整数、字符串型、数组、映射表、实数、日期、时间戳等。另外 DataFrame 中的数据是不可变的,Spark 记录着所有转化操作的血缘关系。可以添加列或者改变已有列的名字和数据类型,这些操作都会创建新的 DataFrame ,原有的 DataFrame 则会保留。在 DataFrame 中,一列与其名字和对应的 Spark 数据类型都在表结构中定义。
数据类型
基本数据类型:
ByteTypeShortTypeIntegerTypeLongTypeFloatTypeDoubleTypeStringTypeBooleanTypeDecimalType
复杂数据类型:
BinaryTypeTimestampTypeDateTypeArrayTypeMapTypeStructTypeStructField
表结构
Spark 中的表结构为 DataFrame 定义了各列的名字和对应的数据类型。从外部数据源读取结构化数据时,表结构就会派上用场。相较于在读取数据时确定数据结构,提前定义表结构有如下优点:
- 可以避免
Spark推断数据类型的额外开销。 - 可以防止
Spark为决定表结构而单独创建一个作业来从数据文件读取很大一部分内容,对于较大的数据文件而言,其耗时相当长 。 - 可以尽早发现数据与表结构不匹配 。
定义表结构有两种方式:
- 编程的方式。
1
2
3schema = StructType([StructField("author", StringType(), False),
StructField("title", StringType(), False),
StructField("pages", IntegerType(), False)]) - 使用数据定义语言(
data definition language, DDL)。1
schema = "author STRING, title STRING, pages INT"
行与列
DataFrame 中的具名列与 Pandas 中的 DataFrame 对象的具名列,以及关系数据库表的列的概念上是类似的:描述的都是一种字段。Spark 的文档对列有 col 和 Column 两种表示。Column 是列对象的类名,而 col() 是标准的内建函数,返回一个 Column 对象。DataFrame 中的 Column 对象不能单独存在,在一条记录中,每一列都是行的一部分,所有的行共同组成整个 DataFrame。
Spark 中的行是用 Row 对象来表示的,它包含一列或多列,各列既可以是相同的类型,也可以是不同的类型。由于 Row 是 Spark 中的对象,表示一系列字段的有序集合,因此可以在编程中很容易的实例化 Row 对象,并用自 0 开始的下标访问该对象的各字段。
表与视图
表存放数据,Spark 中的每张表都关联有相应的元数据,而这些元数据是表及其数据的一些信息,包括表结构、描述、表名、数据库名、列名、分区、实际数据所在的物理位置等,这些全都存放在中心化的元数据库中。Spark 没有专门的元数据库,默认使用 Apache Hive 的元数据库来保存表的所有数据 ,仓库路径位于 /user/hive/warehouse。如果想要想要修改默认路径,可以修改 Spark 配置变量 spark.sql.warehouse.dir 为别的路径,这个路径既可以是本地路径,也可以是外部的分布式存储。
管理表
Spark 允许创建两种表:
- 有管理表
Spark既管理元数据,也管理文件存储上的数据。这里的文件存储可以理解为本地文件系统或HDFS,也可以是外部的对象存储系统。 - 无管理表
Spark只管理元数据,需要自行管理外部数据源中的数据。
基本操作
创建数据库和表
1
2
3
4
5CREATE DATABASE demo_db;
USE demo_db;
CREATE TABLE demo_table_1 (date STRING, delay INT, distance INT);
CREATE TABLE demo_table_2 (date STRING, delay INT, distance INT) USING csv OPTIONS (PATH '/data/learing/data.csv');新增视图
1
CREATE OR REPLACE TEMP VIEW [global_temp.]test_view AS SELECT date, delay, distance FROM demo_table_1 WHERE distance = 2;
缓存
SQL表1
2CACHE [LAZY] TABLE <table-name>
UNCACHE TABLE <table-name>
数据源
DataFrameReader
DataFrameReader 是从数据源读取数据到 DataFrame 所用到的核心结构。用法有固定的格式和推荐的使用模式:
1 | DataFrameReader.format(args).option("key", "value").schema(args).load() |
这种将一串方法串联起来使用的模式在 Spark 中很常见,可读性也不错。
需要注意的是只能通过 SparkSession 实例访问 DataFrameReader,也就是说不能自行创建 DataFrameReader 实例,获取该实例的方法如下:
1 | SparkSession.read // 返回 DataFrameReader 从静态数据源读取 DataFrame |
DataFrameReader 的公有方法如下:
| 方法 | 参数 | 说明 |
|---|---|---|
format() |
"parquet"、 "csv"、 "txt"、 "json"、 "orc"、 "avro" |
如果不指定方法的格式,则使用 spark.sql.sources.default 所指定的默认格式 |
option() |
("mode", [PERMISSIVE FAILFAST DROPMALFORMAD]) 、 ("inferSchema", [true false])、("path", "path_file_data_source") |
一系列键值对,Spark 文档中解释了不同模式下的对应行为 |
schema() |
DDL 字符串或 StructType 对象 |
对于 JSON 或者 CSV 格式,可以使用 option() 方法自行推断表结构 |
load() |
/path/source |
要读取的数据源路径 |
从静态的 Parquet 数据源读取数据不需要提供数据结构,因为 Parquet 文件的元数据通常包含表结构信息。不过对于流式数据源,表结构信息是需要提供的。
DataFrameWriter
DataFrameWriter 是 DataFrameReader 的反面,将数据保存或写入特定的数据源。与 DataFrameReader 不同,DataFrameWriter 需要从保存的 DataFrame 获取,推荐的使用模式如下:
1 | DataFrameWriter.format(args).option(args).bucketBy(args).partitionBy(args).save(path) |
DataFrameWriter 的公有方法如下:
| 方法 | 参数 | 说明 |
|---|---|---|
format() |
"parquet"、 "csv"、 "txt"、 "json"、 "orc"、 "avro" |
如果不指定方法的格式,则使用 spark.sql.sources.default 所指定的默认格式 |
option() |
("mode", append [overwrite ignore error])、 ("path", "path_to_write_to") |
一系列键值对,Spark 文档中解释了不同模式下的对应行为 |
bucketBy() |
(numBuckets, col, ..., coln) |
按桶写入时,指定桶数量和分桶所依据字段的名字列表 |
save() |
"/path/source" |
写入的路径 |
saveAsTable() |
"table_name" |
写入的表名 |
文件类型
ParquetSpark的默认数据源,很多大数据框架和平台都支持,它是一种开源的列式存储文件格式,提供多种I/O优化措施(比如压缩,以节省存储空间,支持快速访问数据列)。JSONJSON的全称为JavaScript Object Notation,它 是一种常见的数据格式。JSON有两种表示格式:单行模式和多行模式。CSVCSV格式应用非常官方,是一种将所有数据字段用逗号隔开的文本文件格式。在这些用逗号隔开的字段中,每行表示一条记录。(这里的逗号分隔符号是可以被修改的)AvroAvro格式有很多优点,包括直接映射JSON、快速且高效、支持多种编程语言。ORC
作为另一种优化后的列式存储文件格式,Spark支持ORC的向量化读。向量化读通常会成块()读入数据,而不俗一次读一行,同时操作会串起来,降低扫描、过滤、聚合、连接等集中操作时的CPU使用率。
高阶函数
复杂数据类型由简单数据类型组合而成,而实际则是经常直接操作复杂数据类型,操作复杂数据类型的方式有以下两种:
- 将嵌套的结构打散到多行,调用某个函数,然后重建嵌套结构。
- 构建用户自定义函数。
这两种方式都有助于以表格格式处理问题,一般会涉及到 get_json_object()、from_json()、to_json()、explode() 和 selectExpr() 等工具函数。
打散再重组
1 | SELECT id, collect_list(value + 1) AS values |
上述的嵌套的 SQL 语句中,先执行 EXPLODE(values),会为每一个 value 创建新的一行(包括 id 字段)。collect_list() 返回的是未去重的对象列表,由于 GROUP BY 语句会触发数据混洗操作,因此重新组合的数组顺序和原数组不一定相同。
自定义函数
要想自行上述等价的任务,也可以创建 UDF,用 map() 迭代各个元素并执行额外的操作。
1 | val = plusOneInt = (values: Array[Int] => { |
然后可以在 Spark SQL 中使用这个 UDF。
1 | spark.sql("SELECT id, plusOneInt(values) AS values FROM table").show() |
由于没有顺序问题,这种方法比使用 explode() 和 collect_list() 好一些,但序列化和反序列化过程本身开销很大。
复杂类型的内建函数
Spark 专门为复杂数据类型准备的内建函数,完整列表可以参考官方文档。
高阶函数
除了上述的内建函数外,还有部分高阶函数接受匿名 lambda 函数作为参数,示例如下:
1 | # transform 函数接受一个数组和匿名函数作为输入,通过对数组的每个元素应用匿名函数,该函数将结果赋值到输出数组,透明地创建出一个新数组。 |
transform()1
transform(array<T>, function<T, U>): array<U>
通过对输入数组的每个元素使用一个函数,
transform()函数会生成新的数组。filter()1
filter(array<T>, function<T, Boolean>): array<T>
filter()函数输出的数组仅包含输入数组中让布尔表达式结果为true的元素。exists()1
exists(array<T>, function<T, V, Boolean>): Boolean
当输入数组中有任意一元素满足布尔函数时,
exists()函数返回true。reduce()1
reduce(array<T>, B, function<B, T, B>, function<B, R>)
通过函数
function<B, T, B>,reduce()函数可以将数组的元素合并到缓冲区B,最后对最终缓冲区使用最终函数function<B, R>,并将数组归约为单个值。
高阶操作
联合
将具有相同表结构的DataFrame联合起来。1
2
3
4
5# 联合两种表
bar = deplays.union(foo)
bar.createOrReplaceTempView("bar")
# 展示联合结果
bar.filtyer(expr("origin == 'SEA' AND destination == 'SFO' AND date LIKE '0010%' AND deplay > 0")).show()连接
连接两个DataFrame是常用操作之一。
默认情况下连接为inner join,可选的种类包含inner、cross、outer、full、full_outer、left、left_outer、right、right_outer、left_semi和left_anti。1
foo.join(ports, ports.IATA == foo.origin).select("City", "date", "deplay", "distance").show()
窗口
窗口函数使用窗口(一个范围内的输入行)中各行的值计算出一组值来返回,返回的一般是新的一行。通过使用窗口函数可以在每次操作一组的同时,返回的行数仍然和输入行数一一对应。1
2
3SELECT origin, destiation, TotalDelays, rank
FROM (SELECT origin, destiation, TotalDelays, dense_rank() OVER (PARTITION BY origin ORDER BY TotalDelays DESC) as rank) t
WHERE rank <= 3修改
对DataFrame进行修改,DataFrame本身不允许被修改,不过可以通过新建DataFrame的方式来实现修改。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 增加新列
foo2 = (foo.withColumn("status", expr("CASE WHEN delay <= 10 THEN 'On-time' ELSE 'Delayed' END")))
foo2.show()
# 删除列
foo3 = foo2.drop("delay")
foo3.show()
# 修改列名
foo4 = foo3.withColumnRenamed("status", "flight_status")
foo4.show()
# 转置(将行与列数据互换)
SELECT * FROM (
SELECT destination, CAST(SUBSTRING(date, 0, 2) AS int) AS month, delay FROM departureDelays WHERE origin = 'SEA'
)
PIVOT (
CAST(AVG(delay) AS DECIMAL(4, 2)) AS AvgDelay, MAX(delay) AS MaxDelay FOR month IN (1 JAN, 2 FEB)
)
ORDER BY destination
数据结构化 Dataset
前面看过了 DataFrame,那么你基本上就理解了 Dataset,不过还是有那么一些差别,Dataset 主要区分两种特性: 有类型和无类型 。
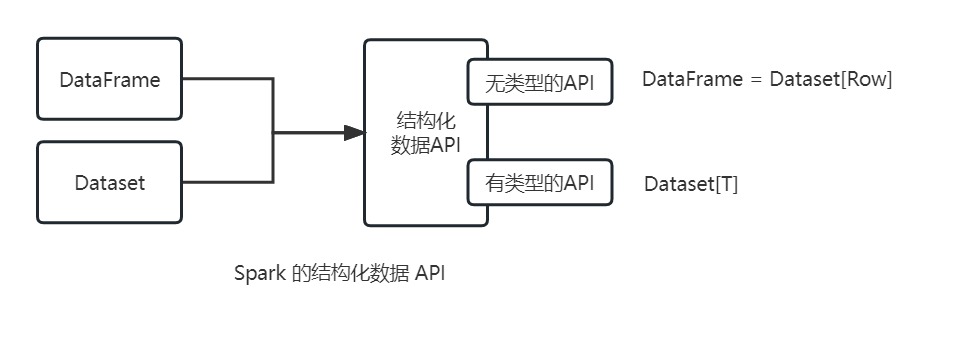
从概念上看,可以将 DataFrame 看作是 Dataset[Row] 这种由普通对象组成的集合的一个别称,其中 Row 是普通的无类型对象,可以包含不同数据类型的字段。而 Dataset 则与之相反,是由同一类型的对象所组成的集合。正如官方文档中描述的那样:
一种由领域专用对象组成的强类型集合,可以使用函数式或关系型的操作将其并行转化。
| 语言 | 有类型和无类型的主要抽象结构 | 有类型或无类型 |
|---|---|---|
Scala |
Dataset[T] 和 DataFrame(Dataset[Row] 的别命) |
都有 |
Java |
Dataset<T> |
有类型 |
Python |
DataFrame |
普通 Row 对象,无类型 |
R |
DataFrame |
普通 Row 对象,无类型 |
转化数据
Dataset 是强类型的对象集合,这些对象可以使用函数式或关系型的算子并行转化。可用的转化操作包括 map()、reduce()、filter()、select() 和 aggregate(),这些方法都属于高阶函数,他们接受 lambda 表达式、闭包或函数作为参数,然后返回结果,因此这些操作非常适合函数式编程。
不过上述 Dataset 是有不足之处的,在使用高阶函数时,会产生从 Spark 内部的 Tungsten 格式反序列化为 JVM 对象的开销,那么避免多余的序列化和反序列化的策略有以下两种:
- 在查询中使用
DSL表达式,避免过多地使用lambda表达式的匿名函数作为高阶函数的参数。 - 将查询串联起来,以尽量减少序列化和反序列化。
编码器
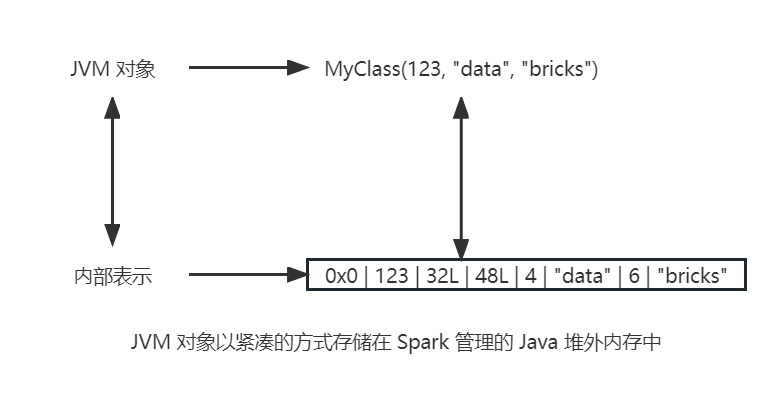
编码器将堆外内存中的数据从 Tungsten 格式转为 JVM 对象,即编码器承担着在 Spark 内部格式和 JVM 对象之间序列化和反序列化 Dataset 对象 。Spark 支持自动生成原生类型、Scala 样例类和 JavaBean 的编码器。比起 Java 和 Kryo 的序列化和反序列化,Spark 的编码器要快很多。
Spark 不为 Dataset 或 DataFrame 创建基于 JVM 的对象,而会分配 Java 堆外内存来存储数据,并使用编码器将内存表示的数据转为 JVM 对象。
当数据以紧凑的方式存储并通过指针和偏移量访问时,编码器可以快速序列化和反序列化数据。
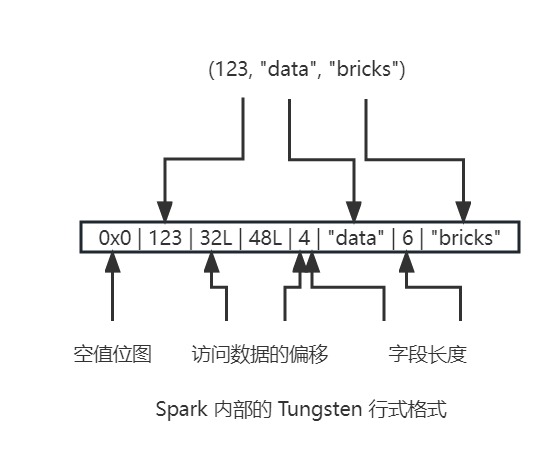
相比 JVM 自建的序列化和反序列化,Dataset 编码器的优点如下:
Spark内部的Tungsten二进制格式将对象存储在Java的堆内存之外,存储的方式很紧凑,因此对象占用的空间更小。- 通过使用指针和计算出的内存地址与偏移量来访问内存,编码器可以实现快速序列化。
- 在接收端,编码器能快速地将二进制格式反序列化为
Spark内部的表示形式。编码器不受JVM垃圾回收暂停的影响。
Spark 引擎
在编程层面上,Spark SQL 允许开发人员对带有表结构的结构化数据发起兼容 ANSI SQL:2003 标准的查询。至此 Spark SQL 已经演变成一个非常重要的引擎,许多高层的结构化功能都是基于它构建出来的,除了可以对数据发起类似 SQL 的查询,Spark SQL 引擎还支持下列功能:
- 统一
Spark的各个组件,允许在Java、Scala、Python、R程序中将结构化数据集抽象为DataFrame或Dataset,从而简化编程工作。 - 连接
Apache Hive的元数据库和表。 - 从结构化的文件格式(
JSON、CSV、Text、Avro、Parquet、ORC等)使用给定的表结构读取结构化数据,并将数据转换为临时表。 - 为快速的数据探索提供交互式
Spark SQL shell。 - 通过标准的
JDBS/ODBC连接器,提供与外部工具互相连接的纽带。 - 生成优化后的查询计划和紧凑的
JVM二进制代码,用于最终执行。
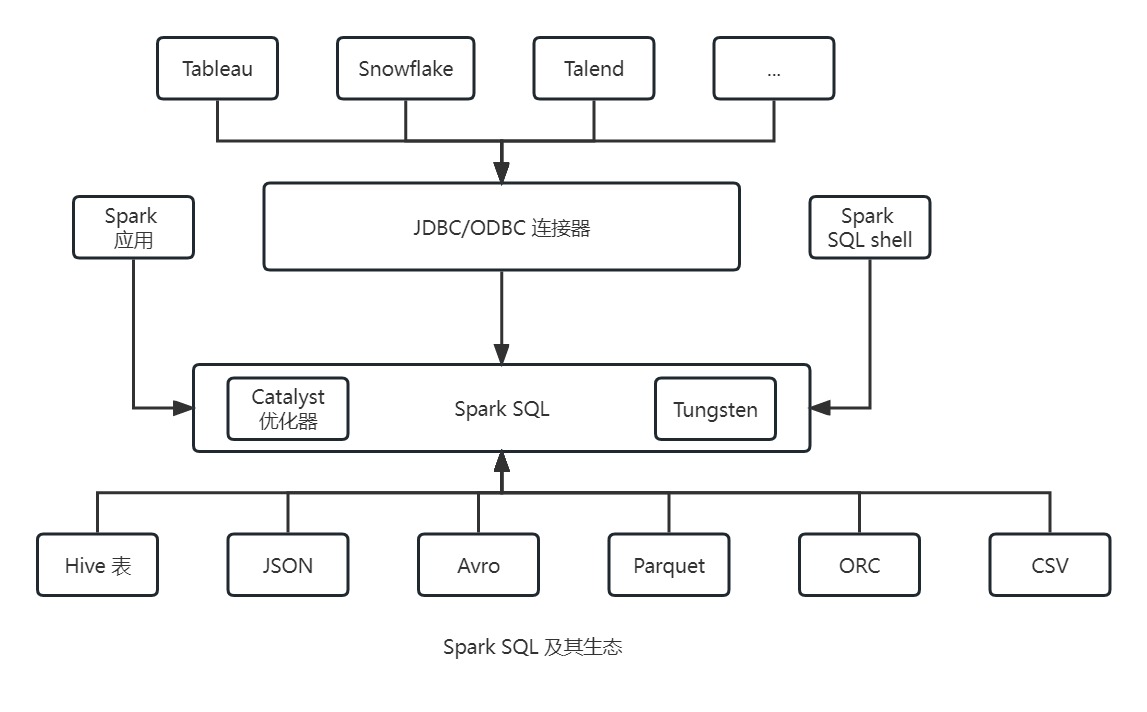
Spark SQL 引擎的核心是 Catalyst 优化器和 Tungsten 项目 ,其两者共同支撑高层的 DataFrame API 和 Dataset API,以及 SQL 查询。
Catalyst 优化器
Catalyst 优化器接受计算查询作为参数,并将查询转化为执行计划。共分为四个转换阶段:
- 解析
Spark SQL引擎首先会为SQL或DataFrame查询生成相应的抽象语法树(abstract synrax tree, AST)。所有的列名和表名都会通过查询内部元数据而解析出来,全部解析完成后,会进入下一阶段。 - 逻辑优化
这个阶段在内部共分为两步。通过应用基于规则的优化策略,Catalyst优化器会首先构建出多个计划,然后使用基于代价的优化器(cost-based optimizer, CBO)为每个计划计算出执行开销。这些计划以算子树的形式呈现,其优化过程包括常量折叠、谓词下推、列裁剪、布尔表达式简化等,最终获得的逻辑计划作为下一阶段的输入,用于生成物理计划。 - 生成物理计划hexo
Spark SQL会为选中的逻辑计划生成最佳的物理计划,这个物理计划由Spark执行引擎可用的物理算子组成。 - 生成二进制代码
在查询优化的最终阶段,Spark会最终生成高效的Java字节码,用于在各个机器上执行。而在这个过程中用到了Tungsten项目,实现了执行计划的全局代码生成。
那什么是全局代码生成呢?他是物理计划的一个优化阶段,将整个查询合并为一个函数,避免虚函数调用,利用CPU寄存器存放中间数据,而这种高效策略可以显著提升CPU效率和性能。
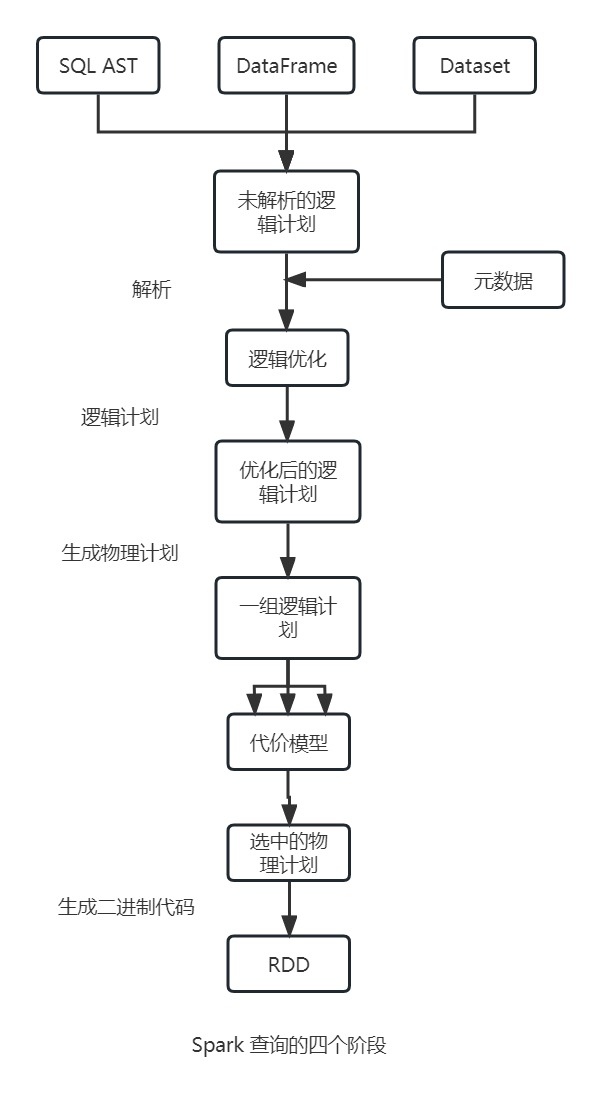
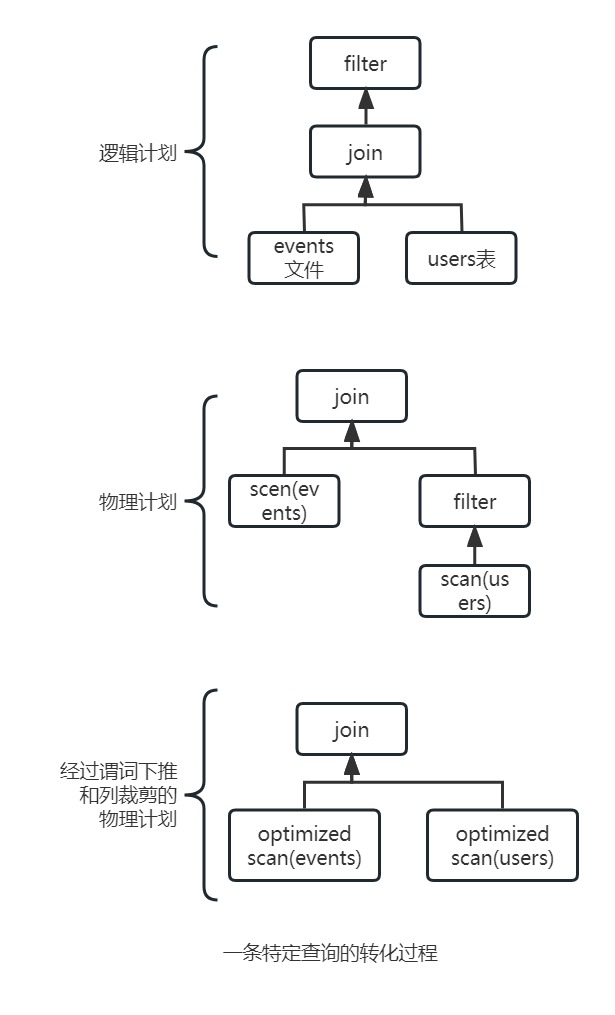
通过上面的图示,可以发现只要执行过程相同,最终会生成相似的查询计划和一样的字节码用于执行,也就是说,无论使用什么编程语言,查询都会经过同样的过程,所生成的字节码很有可能都是一样的。
在经过最初的解析阶段之后,查询计划会被 Catalyst 优化器转化和重排。
Tungsten 项目
Tungsten 项目致力于提升 Spark 应用对内存和 CPU 的利用率,使性能达到硬件的极限,主要包含以下内容:
Memory Management and Binary Processing:off-heap管理内存,降低对象的开销和消除JVM GC带来的延时。Cache-aware computation: 优化存储,提升CPU L1/L2/L3缓存命中率。Code generation: 优化Spark SQL的代码生成部分,提升CPU利用率。
引用
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!