基础
Hive 是一个构建在 Hadoop 之上的数据仓库框架,其设计目的在于让精通 SQL 但编程技能较弱的运营人员能够对存放在 HDFS 中的大规模数据集执行查询。
但是由于其底层依赖的 Hadoop 和 HDFS 设计本身约束和局限性,限制 Hive 不支持记录级别的更新、插入或者删除操作,不过可以通过查询生成新表或将查询结果导入文件中来实现。同时由于 MapReduce 任务的启动过程需要消耗较长的时间,所以查询延时比较严重。

Hive 发行版本中包含 CLI 、 HWI (一个简单的网页界面)以及可通过 JDBC 、 ODBC 和一个 Thrift 服务器进行编程访问的几个模块。
所有的命令和查询都会进入 Driver(驱动模块),通过该模块对输入进行解析编译,对需求的计算进行优化,然后按照指定的步骤执行(通常是启动多个 MapReduce 任务 job 来执行)。当需要启动启动 MapReduce 任务(job)时,Hive 本身是不会生成 MapReduce 算法程序,相反 Hive 会通过一个 XML 文件的 job 执行计划驱动执行内置的、原生的 Mapper 和 Reduce 模块,即这些通用的模块函数类似于微型的语言翻译程序,而驱动此翻译程序的就是 XML 文件。Hive 通过和 JobTracker 通信来初始化 MapReduce 任务,而不必部署在 JobTracker 所在的管理节点上执行。Metastore(元数据存储)是一个独立的关系型数据库,Hive 会在其中保存表模式和其他系统元数据。
安装
Hive 一般运行在工作站上,将 SQL 查询转换为一系列在 Hadoop 集群上运行的作业。Hive 把数据组织为表,通过这种方式为存储在 HDFS 上的数据结构赋予结构,元数据(表模式等)存储在 metastore 数据库中。
Hive 的安装非常简单,首先必须安装相同版本的 Hadoop。 接下来下载相同版本的 Hive,然后把压缩包解压缩到合适的目录:
1 | tar xzf apache-hive-x.y.z-bin.tar.gz |
接下来就是将 Hive 加入到全局文件中:
1 | export HIVE_HOME=~/apache-hive-x.y.z-bin |
最后就是启动 Hive 的 shell 环境:
1 | hive |
环境配置
与 Hadoop 类似,Hive 用 XML 配置进行设置,配置文件为 hive-site.xml,位于在 Hive 的 conf 目录下。通过该文件可以设置每次运行 Hive 时希望使用的配置项,该目录下还包含 hive-default.xml (其中记录着 Hive 的选项及默认值)。
hive-site.xml 文件最适合存放详细的集群连接信息,可以使用 Hadoop 属性 fa.defaultFS 和 yarn.resourcemanager.address 来指定文件系统和资源管理器。默认值为本地文件系统和本地作业运行器(job runner)。
传递 --config 选项参数给 hive 命令,可以通过这种方式重新定义 Hive 查找 hive-site.xml 文件的目录:
1 | hive --config /Users/home/hive-conf |
传递 -hiveconf 选项来为单个会话(pre-session)设置属性。
1 | hive -hiveconf fs.defaultFS=hdfs://localhost -hiveconf mapper.framework.name=yarn |
还可以在一个会话中使用 SET 命令更改设置,这对于某个特定的查询修改 Hive 设置非常有用。
1 | SET mapper.framework.name=yarn |
设置属性有一个优先级层次,越小的值表示优先级越高:
Hive SET命令 。- 命令行
-hiveconf选项 。 hive-site.xml和Hadoop站点文件(core-site.xml、hdfs-site.xml、mapper-site.xml、yarn-site.xml)。Hive默认值和Hadoop默认文件(core-default.xml、hadfs-default.xml、mapper-default.xml、yarn-default.xml)。
基本使用
用户接口
CLIShell终端命令行(Command Line Interface),交互形式使用Hive命令行与Hive进行交互。JDBC/ODBCHive基于JDBC操作提供的客户端,用户可以通过连接来访问Hive Server服务。Web UI
通过浏览器访问Hive。
Thrift Server
轻量级、跨语言的远程服务调用框架,Hive 集成该服务便于不同的编程语言调用 Hive 的接口。
Metastore
Metastore 是 Hive 元数据的集中存放地,通常包含两部分:服务和元数据的存储。元数据包含:表的名字、表的列和分区及属性、表的属性(内部表和外部表)、表数据所在目录。默认情况下,metastore 服务和 Hive 服务运行在同一个 JVM 中,包含一个内嵌的以本地磁盘作为存储的 Derby 数据库实例,被称为内嵌 metastore 配置(embedded metastore configuration)。
如果要支持多会话(以及多用户),需要使用一个独立的数据库。这是因为 MetaStore 通常存储在其自带的 Derby 数据库中,缺点是跟随 Hive 部署,数据目录不固定,且不支持多用户操作。另外现在支持外部 MySQL 与 Hive 交互用于存储元数据信息。
可以通过把 hive.metastore.uris 设为 metastore 服务器 URI(如果有多个服务器,各个 URI 之间使用逗号分隔),把 Hive 服务设为使用远程 metastore。metastore 服务器 URI 的形式为 thrift://host:port。
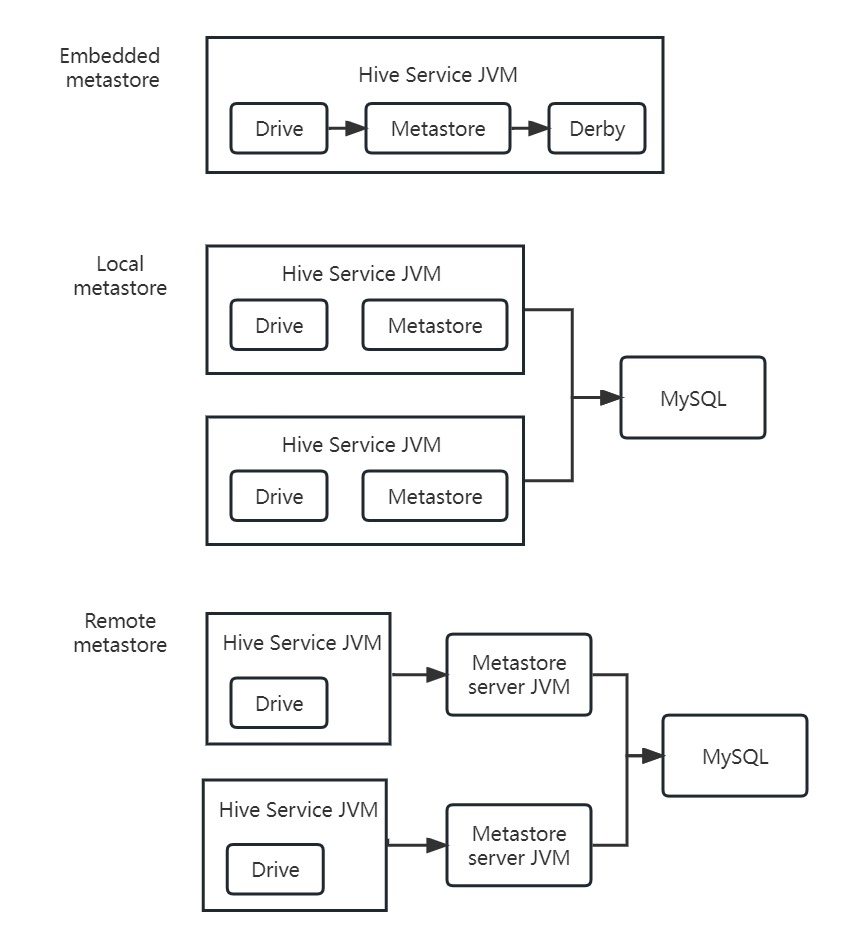
重要的 metastore 配置属性:
| 属性名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
hive.metastore.warehouse.dir |
URI |
/user/hive/warehouse |
相当于 fs.default.name 的目录,托管表就存储在这里 |
hive.metastore.uris |
逗号分隔的 URI |
未设定 | 如果未设置则使用当前的 metastore,否则连接到由 URI 列表指定要连接的远程 metastore 服务器。 |
javax.jddo.option.ConnectionURL |
URI |
jdbc:derby:;databaseName=metastoredb;create=true |
metastore 数据库的 JDBC URL |
javax.jddo.option.ConnectionDriveName |
字符串 | org.apache.derby.jdbc.EmbeddedDriver |
JDBC 驱动器的类名 |
javax.jddo.option.ConnectionUserName |
字符串 | APP |
JDBC 用户名 |
javax.jddo.option.ConnectionPassword |
字符串 | mine |
JDBC 密码 |
特性
计算引擎
目前 Hive 支持 MapReduce 、 Tez 和 Spark 三种计算引擎。
MapReduce计算引擎
请参考之前的博客内容。Spark计算引擎
请参考之前的博客内容。Tez计算引擎Apache Tez是进行大规模数据处理且支持DAG作业的计算框架,它直接源于MapReduce框架,除了能够支持MapReduce特性之外,还支持新的作业形式,并允许不同类型的作业能够在一个集群中运行。Tez将原有的Map和Reduce两个操作简化为一个新的概念 **Vertex**,并将原有的计算处理节点拆分成多个组成部分:Vertex Input、Vertex Output、SortingShuffling和Merging。计算节点之间的数据通信被统称为Edge,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。
通过允许Apache Hive运行更加复杂的DAG任务,之前需要多个MR jobs,但现在运行一个Tez任务中。
Tez和MapReduce作业的比较:Tez绕过MapReduce很多不必要的中间的数据存储和读取的过程,直接在一个作业中表达了MapReduce需要多个作业共同协作才能完成的事情。Tez和MapReduce一样都使用YARN作为资源调度和管理。但与MapReduce on YARN不同,Tez on YARN并不是将作业提交到ResourceManager,而是提交到AMPoolServer的服务上,AMPoolServer存放着若干个已经预先启动的ApplicationMaster服务。- 当用户提交一个
Tez作业上来后,AMPoolServer从中选择一个ApplicationMaster用于管理用户提交上来的作业,这样既可以节省ResourceManager创建ApplicationMaster的时间,而又能够重用每个ApplicationMaster的资源,节省了资源释放和创建时间。
Tez相比于MapReduce有以下几点重大改进:- 当查询需要有多个
Reduce逻辑时,Hive的MapReduce引擎会将计划分解,每个Redcue提交一个MapReduce作业。这个链中的所有MR作业都需要逐个调度,每个作业都必须从HDFS中重新读取上一个作业的输出并重新洗牌。而在Tez任务中,几个Reduce接收器可以直接连接,数据可以流水线传输,而不需要临时HDFS文件,这种模式称为MRR(Map-reduce-reduce)。 Tez还允许一次发送整个查询计划,实现应用程序动态规划,从而使框架能够更智能地分配资源,并通过各个阶段流水线传输数据。对于更复杂的查询来说,这是一个巨大的改进,因为它消除了IO/sync障碍和各个阶段之间的调度开销。- 在
MapReduce计算引擎中,无论数据大小,在洗牌阶段都以相同的方式执行,将数据序列化到磁盘,再由下游的程序去拉取,并反序列化。Tez可以允许小数据集完全在内存中处理,而MapReduce中没有这样的优化。仓库查询经常需要在处理完大量的数据后对小型数据集进行排序或聚合,因此Tez的优化也能极大地提升效率。
存储格式
Hive 支持的存储数的格式主要有: TEXTFILE(行式存储)、 SEQUENCEFILE(行式存储)、 ORC(列式存储)、 PARQUET(列式存储)。
行存储的特点: 查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
列存储的特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE
默认格式,数据不做压缩,磁盘开销大,数据解析也开销大。可结合 Gzip、Bzip2 使用(系统自动检查,执行查询时自动解压),但使用这种方式,Hive 就不会对数据进行切分,从而无法对数据进行并行操作。
ORC 格式
ORC (Optimized Row Columnar) 是 Hive 0.11 引入的新的存储格式。其可以看到每个 ORC 文件由 1 个或多个 Stripe 组成,每个 stripe 为 250MB 大小。Stripe 实际相当于 RowGroup 概念,不过大小由 4MB->250MB,这样能提升顺序读的吞吐率。
每个 Stripe 里有三部分组成,分别是:
Index Data
一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引只是记录某行的各字段在Row Data中的offset偏移量。RowData
存储的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。Stripe Footer
存的是各个stripe的元数据信息。每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,记录了整个文件的压缩类型以及FileFooter的长度信息等。
在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
PARQUET 格式
Parquet 是面向分析型业务的列式存储格式,以二进制方式存储的,因此是不可以直接读取的,文件中包括该文件的数据和元数据,所以 Parquet 格式文件是自解析的。
通常情况下,在存储 Parquet 数据的时候会按照 Block 大小设置行组的大小,由于一般情况下每一个 Mapper 任务处理数据的最小单位是一个 Block,这样可以把每一个行组由一个 Mapper 任务处理,增大任务执行并行度。
该 Parquet 文件的内容中:一个文件中可以存储多个行组,文件的首位都是该文件的 Magic Code,用于校验它是否是一个 Parquet文件;Footer length 记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量;文件的元数据中包括每一个行组的元数据信息和该文件存储数据的 Schema 信息;除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据。
在Parquet中,有三种类型的页:
- 数据页
数据页用于存储当前行组中该列的值。 - 字典页
字典页存储该列值的编码字典,每一个列块中最多包含一个字典页。 - 索引页
索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
压缩格式
在 Hive 中处理数据,一般都需要经过压缩,通过压缩来节省网络带宽。
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 | 对应的编解码器 |
|---|---|---|---|---|---|
DEFAULT |
无 | DEFAULT |
.deflate |
否 | org.apache.hadoop.io.compress.DefaultCodec |
Gzip |
gzip |
DEFAULT |
.gz |
否 | org.apache.hadoop.io.compress.GzipCodec |
bzip2 |
bzip2 |
bzip2 |
.bz2 |
是 | org.apache.hadoop.io.compress.BZip2Codec |
LZO |
lzop |
LZO |
.lzo |
否 | com.hadoop.compression.lzo.LzopCodec |
LZ4 |
无 | LZ4 |
.lz4 |
否 | org.apache.hadoop.io.compress.Lz4Codec |
Snappy |
无 | Snappy |
.snappy |
否 | org.apache.hadoop.io.compress.SnappyCodec |
底层执行原理

Driver 运行器
Driver 组件完成 HQL 查询语句从词法分析,语法分析,编译,优化,以及生成逻辑执行计划的生成。生成的逻辑执行计划存储在 HDFS 中,并随后由 MapReduce 调用执行。Hive 的核心是驱动引擎, 驱动引擎由四部分组成:
- 解释器:解释器的作用是将
HiveSQL语句转换为抽象语法树(AST)。 - 编译器:编译器是将语法树编译为逻辑执行计划。
- 优化器:优化器是对逻辑执行计划进行优化。
- 执行器:执行器是调用底层的运行框架执行逻辑执行计划。
执行流程
HiveQL 通过命令行或者客户端提交,经过 Compiler 编译器,运用 MetaStore 中的元数据进行类型检测和语法分析,生成一个逻辑方案(Logical Plan),然后通过的优化处理,产生一个 MapReduce 任务。

与传统数据库比较
Hive 在很多方面与传统的数据库类似,但由于需要支持 MapReduce 和 HDFS 就意味着其体系结构有别于传统数据库,而这些区别又影响着 Hive 所支持的特性。
读时模式和写时模式
在加载时发现数据不符合模式,则拒绝加载数据,因为数据是在写入数据库时对照模式进行检查,因此这一设计又被称为“写时模式” 。而 Hive 对数据的验证并不在加载数据时进行,而是在查询时进行,被称为“读时模式” 。
读时模式不需要读取数据来进行“解析”,再进行序列化并以数据库内部格式存入磁盘,因此可以使数据加载非常迅速。写时模式可以对列进行索引,并对数据进行压缩,但这也会导致加载数据会额外耗时,由此有利于提升查询性能。
更新、事务和索引
更新、索引和事务这些是传统数据库最要的特性,但 Hive 并不支持这些,因为需要支持 MapReduce 操作 HDFS 数据,因此 “全表扫描” 是常态化操作,而表更新则是将数据变换后放入新表实现。
更新
HDFS不提供就地文件更新,因此插入、更新、删除等一系列引起数据变化的操作都会被保存在一个较小的增量文件中,由metastore在后台运行的MapReduce任务定期将这些增量文件合并到基表文件中。
上述功能的支持必须启用事务,以保证对表进行读取操作时可以看到表的一致性快照。锁
Hive引入了表级(table-level)和分区级(partition-level)的锁,因此可以防止一个进程删除正在被另一个进程读取的表。该锁由ZooKeeper透明管理,因此用户不必执行获取和释放锁的操作,但可以通过SHOW LOCKS语句获取已经获得了哪些锁的信息。默认情况下,未启用锁的功能。索引
Hive的索引目前被分为两类:紧凑索引(compact index)和位图索引(bitmap index)。
紧凑索引存储每个值的HDFS块号,而不是存储文件内偏移量,因此存储不会占用过多的磁盘空间,并且对于值被聚簇(clustered)存储于相近行的情况,索引仍然能够有效。
位图索引使用压缩的位集合(bitset)来高效存储某个特殊值的行,而这种索引一般适用于较少取值的列(例如性别和国家)。
其他 SQL-on-hadoop
针对 Hive 的局限性,也有其他的 SQL-on-Hadoop 技术出现,那么 Cloudera Impala 就是其中的佼佼者,他是开源交互式 SQL 引擎,Impala 在性能上要强于 MapReduce 的 Hive 高一个数量级。Impala 使用专门的守护进程,这些守护进程运行在集群中的每个数据节点上,当客户端发起查询时,会首先联系任意一个运行了 Impala 守护进程的节点,该节点会被当作该查询的协调(coordination)节点。协调节点向集群中的其他 Impala 守护进程分发工作,并收集结果以形成该查询的完整结果集。Impala 使用 Hive 的 Metastore 并支持 Hive 格式和绝大多数的 HiveQL 结构,因此在实际中这两者可以直观地相互移植,或者运行在同一个集群上。
当然也有 Hortonworks 的 Stinger 计划支持 Tez 作为执行引擎,再加上矢量化查询引擎等其他改进技术,使 Hive 在性能上得到很大的提升。
Apache phoenix 则采取了另一种完全不同的方式,提供基于 HBase 的 SQL,通过 JDBC 驱动实现 SQL 访问,JDBC 驱动将查询转换为 HBase 扫描,并利用 HBase 协同处理器来执行服务器端的聚合,当然数据也存储在 HBase 中。
HiveQL
Hive 的 SQL 被称为 HiveQL,是 SQL-92、 MySQL、 Oracle SQL 的混合体。其概要比较如下:
| 特性 | SQL |
HiveQL |
|---|---|---|
| 更新 | UPDATE、 INSERT、 DELETE |
UPDATE、 INSERT、 DELETE |
| 事务 | 支持 | 有限支持 |
| 索引 | 支持 | 支持 |
| 延迟 | 亚秒级 | 分钟级 |
| 数据类型 | 整数、浮点数、定点数、文本和二进制串、时间 | 布尔型、整数、浮点数、文本和二进制串、时间戳、数组、映射、结构 |
| 函数 | 数百个内置函数 | 数百个内置函数 |
| 多表插入 | 不支持 | 支持 |
CREATE TABLE AS SELECT |
SQL-92 中不支持,但有些数据库支持 |
支持 |
SELECT |
SQL-92 |
SQL-92。支持偏序的 SORT BY,可限制返回数量的 LIMIT |
| 连接 | SQL-92 支持或变相支持 |
内连接、外连接、半连接、映射连接、交叉连接 |
| 子查询 | 在任何子句中支持的或不相关的 | 只能在 FROM、 WHERE 或 HAVING 子句中 |
| 视图 | 可更新 | 只读 |
| 扩展点 | 用户定义函数、存储过程 | 用户定义函数、MapReduce 脚本 |
数据类型
Hive 支持原子和复杂数据类型。原子数据类型包括数值型、布尔型、字符串类型和时间戳类型。复杂数据类型包括数组、映射和结构。
Hive 提供了普通 SQL 操作符,包括:关系操作符、算术操作符和逻辑操作符。
自定义函数
用户自定义函数(UDF)是一个允许用户通过扩展 HiveQL 的强大功能,用户通过 Java 编写自己的 UDF,在将自定义函数加入用户会话后,就可以跟内置函数一样使用。Hive 提供了多种类型的用户自定义函数,每一种都会针对输入数据执行特定的转换过程,具体类型包含以下三种:
UDF (User Defined Function):一进一出。传入一个值,逻辑运算后返回一个值,如内置函数的floor、round等。UDAF (User Defined Aggregation Funtion):多进一出。传入多行数据,根据选定的值group by后返回一行结果,类似sum、count。UDTF (User Defined Table Generating Functions):一进多出。基于特定的一行值输入,返回展开多行输出,类似内置函数explode。
创建自定义函数步骤如下:
- 编写自定义函数
引入依赖1
2
3
4
5<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${version}</version>
</dependency> - 编译部署
自定义函数代码编写完成后,编译打包为jar文件。
部署jar文件要根据部署模式进行调整,本地模式则是将jar文件采用本地模式部署,而非本地模式则是将jar文件放置到共享存储(HHDFS)上。1
2
3
4
5
6
7本地模式
ADD jar hive-jar-test-1.0.0.jar
Added hive-jar-test-1.0.0.jar to class path
list jars;
hive-jar-test-1.0.0.jar
非本地模式
hadoop fs -put hive-jar-test-1.0.0.jar /usr/home/hive-jar-test-1.0.0.jar Hive中注册函数
注册函数也被分为两种:临时函数和永久函数,临时注册函数用于解决一些临时特殊的业务需求开发的函数,Hive注册的临时函数只在当前会话中可用,注册函数时需要使用temporary关键字声明。注册函数时未使用临时关键字temporary的都为永久函数,在所有会话中都可用。1
CREATE [temporary] FUNCTION [dbname.]function_name AS class_name [USING jar | file | archive 'file_url']
- 使用自定义函数
函数全名使用dbname.function_name表示,使用的时候可以直接用函数全名,但查询如果在当前库下操作,则使用函数名即可。1
SELECT id, test_udf_lower(content) FROM test_table_1 LIMIT 10;
- 销毁自定义函数
1
DROP [temporary] FUNCTION [dbname.]function_name AS class_name;
UDF
编写 UDF,需要继承 org.apache.hadoop.hive.ql.exec.UDF 并重写 evaluate 函数。
1 | package org.example; |
UDF 必须有返回类型,可以返回 null,但返回类型不能为 void。
UDAF
1 | package org.example; |
函数执行过程:
PARTIAL1:从原始数据到部分聚合数据的过程,会调用iterate()和terminatePartial()方法。iterate()函数负责解析输入数据,而terminatePartial()负责输出当前临时聚合结果。该阶段可以理解为对应MapReduce过程中的Map阶段。PARTIAL2:从部分聚合数据到部分聚合数据的过程(多次聚合),会调用merge()和terminatePartial()方法。merge()函数负责聚合Map阶段terminatePartial()函数输出的部分聚合结果,terminatePartial()负责输出当前临时聚合结果。阶段可以理解为对应MapReduce过程中的Combine阶段。FINAL: 从部分聚合数据到全部聚合数据的过程,会调用merge()和terminate()方法。merge()函数负责聚合Map阶段或者Combine阶段terminatePartial()函数输出的部分聚合结果。terminate()方法负责输出Reduce阶段最终的聚合结果。该阶段可以理解为对应MapReduce过程中的Reduce阶段。COMPLETE: 从原始数据直接到全部聚合数据的过程,会调用iterate()和terminate()方法。可以理解为MapReduce过程中的直接Map输出阶段,没有Reduce阶段。
还有另外一种实现方式是继承 org.apache.hadoop.hive.ql.exec.UDAF,并且包含一个或多个嵌套的、实现了 org.apache.hadoop.hive.ql.UDAFEvaluator 的静态类。
数据库
表
Hive 的表在逻辑上由存储的数据和描述表中数据形式的相关元数据组成。数据一般存放在 HDFS 中,但它也可以放在其他任何 Hadoop 文件系统中,包括本地文件系统或 S3。Hive 把元数据存放在关系型数据库中,而不是放在 HDFS 中。
托管表和外部表
在 Hive 中创建表时,默认情况下由 Hive 负责管理数据,这也就意味着要将数据移入仓库目录,被称为内部表。而另外一种则是外部表,数据存放在仓库目录以外的地方。
这两种表的区别在于 LOAD 和 DROP 命令的语义上:
LOAD
托管表:加载数据到托管表时,会将数据文件移入到仓库目录下。1
2CREATE TABLE test_table_1(content STRING);
LOAD DATA INPATH '/usr/home/data.txt' INTO TABLE test_table_1;
外部表:1
2CREATE EXTERNAL TABLE test_table_2 (content STRING) LOCATION '/usr/home/data.txt';
LOAD DATA INPATH '/usr/home/data.txt' INTO TABLE test_table_2;DROP
托管表:执行上述操作,会将其元数据和数据一起被删除,这也就是 “托管数据” 的含义。1
DROP TABLE test_table_1;
外部表:删除外部表并不会删除数据,仅会删除元数据。1
DROP TABLE test_table_2;
那么如何选择并使用这两种类型的表呢?
有一个经验法则就是,如果需要所有的处理都由 Hive 完成,那么应该使用托管表。如果要使用其他的工具来处理数据集则使用外部表。
分区和桶
Hive 将表组织成分区(partition),这是一种根据分区列(partition column)的值对表进行粗略划分的机制。使用分区可以加快数据分片(slice)的查询速度。
表或分区可以进一步分为桶(bucket),会为数据提供额外的结构以获得更高效的查询处理。
分区
一个表可以通过多个维度来进行分区。分区是在创建表的时候用PARTITIONED BY子句定义的,该子句需要定义列的列表。1
2CREATE TABLE test_table_3 (ts INT, line STRING)
PARTITIONED BY (dt STRING, country STRING);而在文件系统级别,分区只是表目录下嵌套的子目录,将更多的文件加载到表目录之后,目录结构如下:
1
2
3
4
5
6
7
8
9
10
11
12/usr/home/warehouse/test_table_3
dt=2023-05-16
country=CN
file1
file2
country=EU
file5
file6
dt=2023-05-17
country=CN
file3
file4之后使用
SHOW PARTITIONS命令显示表中的分区列表:1
2
3
4hive> SHOW PARTITIONS test_table_3
dt=2023-05-16/country=CN
dt=2023-05-16/country=EU
dt=2023-05-17/country=CNPARTITIONED BY子句中的列定义是表中正式的列,称为分区列(partition column),但数据中并不包含这些列的值,而是源于目录名。
在日常的查询中以通常的方式使用分区列,Hive会对输入进行修剪,从而只扫描相关分区。1
SELECT ts FROM test_table_3 where country = 'CN';
桶
将表(或分区)组织成桶(bucket)有以下优点:- 获得更高的查询处理效率。桶为表增加了额外的结构,在处理查询时能够利用这个结构,具体为连接两个在相同列上划分了桶的表,可以使用
map端连接高效地实现。 - 使取样更加高效。在处理大规模数据集时,能使用数据的一部分进行查询,会带来很多方便。
Hive使用CLUSTERED BY子句来指定划分桶所用的列和要划分的桶的个数:
1
2CREATE TABLE test_table_4 (ts INT, line STRING)
CLUSTERED BY (id) INTO 4 BUCKETS;在实际物理存储上,每个桶就是表(或分区)目录里的一个文件,其文件名并不重要,但桶
n是按照字典序排列的第n个文件。事实上桶对应于MapReduce的输出文件分区:一个作业产生的桶和reduce任务个数相同。
可以通过查看刚才创建的bucketed_users表的布局来了解这一情况:
1
2
3
4
5dfs -ls /usr/home/warehouse/bucketed_users;
000000_0
000001_0
000002_0
000003_0使用
TABLESAMPLE子句对表进行取样,可以获得相同的结果,该子句会查询限定在表的一部分桶内,而不是整个表:
1
2
3
4hive> SELECT * FROM bucketed_users TABLESAMPLE(BUCKET 1 OUT OF 4 ON id);
4 Ann
0 Nat
2 Joe- 获得更高的查询处理效率。桶为表增加了额外的结构,在处理查询时能够利用这个结构,具体为连接两个在相同列上划分了桶的表,可以使用
导入数据
前面已经使用 LOAD DATA 操作,通过把文件复制或移动到表的目录中,从而把数据导入到 Hive 的表(或分区)。也可以使用 INSERT 语句把数据从一个 Hive 表填充到另一个,或在新建表时使用 CTAS (CREATE TABLE ... AS SELECT)结构。
INSERT1
INSERT OVERWRITE TABLE target [PARTITION(dt)] SELECT col1, col2 FROM source;
OVERWRITE关键字意味着目标表(分区)中的内容会被替换掉。多表插入
1
2
3FROM source
INSERT OVERWRITE TABLE table_by_year SELECT year, COUNT(DISTINCT table) GROUP BY year
INSERT OVERWRITE TABLE table_by_month SELECT month, COUNT(DISTINCT table) GROUP BY month这种多表插入比使用单独的
INSERT效率更高,因为只需要扫描一遍源表就可以生成多个不相交的输出。CTAS语句
将Hive查询的结果输出到一个新的表内是非常方便的,新表的列的定义是从SELECT子句所检索的列导出的。1
2
3CREATE TABLE target
AS
SELECT col1, col2 FROM source;
表的修改和删除
由于 Hive 使用读时模式(schema on read),所以表在创建之后可以非常灵活地支持对表定义的修改。使用 ALTER TABLE 语句来重命名表:
1 | ALTER TABLE source RENAME TO target; |
此命令除更新元数据外,还会将表目录移动到对应的目录下。
另外也支持修改列的定义,添加新的列,甚至用一组新的列替换表内已有的列:
1 | ALTER TABLE target ADD COLUMNS (col3 STRING); |
DROP TABLE 语句用于删除表的数据和元数据。如果是外部表则只删除元数据,数据不会受到影响。
但若是需要仅删除表内的数据,保留表的定义,则需要使用 TRUNCATE TABLE 语句:
1 | TRUNCATE TABLE target; |
查询数据
排序和聚集
Hive 中可以使用标准的 ORDER BY 子句对数据进行排序, ORDER BY 将对输入执行并行全排序。
但是在很多情况下,并不需要对结果全局排序,那么可以使用 Hive 的非标准的扩展 SORT BY ,SORT BY 为每一个 reducer 文件产生一个排序文件。DISTRIBUTE BY 子句可以控制某个特定列到 reducer,通常是为了后续的聚集操作。如果 SORT BY 和 DISTRIBUTE BY 中所使用的列相同,可以缩写为 CLUSTER BY 以便同时指定两者所用的列。
MapReduce 脚本
与 Hadoop Streaming 类似,TRANSFORM、 MAP 和 REDUCE 子句可以在 Hive 中调用外部脚本或程序。
1 | #!/usr/bin/env python |
1 | ADD FILE /usr/home/ ./is_year.py |
子查询
子查询是内嵌在另一个 SQL 语句中的 SELECT 语句。Hive 对子查询的支持很有限,他只允许子查询出现在 SELECT 语句的 FROM 子句中 ,或者某些情况下的 WHERE 子句中。
视图
视图是一种用 SELECT 语句定义的虚表(virtual table)。视图可以用来以一种不同于磁盘实际存储的形式把数据呈现给用户,视图也可以用来限制用户,使其只能访问被授权的可以看到的子表。
Hive 创建视图时并不把视图物化存储在磁盘上,相反视图的 SELECT 语句只是在执行引用视图的语句时才执行。SHOW TABLES 命令的输出结果里包含视图。还可以使用 DESCRIBE EXTENDED view_name 命令来查看某个视图的详细信息,包括用于定义它的那个查询。
1 | CREATE VIEW valid_table |
EXPLAIN
在查询语句之前加上 EXPLAIN 关键字,就可以了解到查询计划和其他的信息来更加直观的展示 Hive 是如何将查询任务转化为 MapReduce 任务。
1 | EXPLAIN SELECT sum(col1) FROM target; |
首先会输出抽象语法树。其表明 Hive 是如何将查询解析为 token(符号)和 literal(字面值)的,是将查询转化到最终结果的一部分。
1 | ABSTRACT SYNTAX TREE: |
接下来可以看到列明 col1、 表明 target 还有 sum 函数。
1 | STAGE DEPENDENCIES: |
一个 Hive 任务会包含一个或多个 stage 阶段,不同的 stage 阶段间会存在着依赖关系。一个 stage 可以是一个 MapReduce 任务,也可以是一个抽样阶段,或者一个合并阶段,还可以是一个 limit 阶段,以及 Hive 需要的其他任务的一个阶段。
默认情况下,Hive 一次只执行一个 stage(阶段)。
除此之外还可以使用 EXPLAIN EXTENDED 语句产生更多的输出信息。
引用
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!