HDFS
当数据集的大小超过一台计算机的存储上限时,就有必要对数据进行分区然后存储到其他的计算机上。管理网络中跨多台计算机存储的文件系统被称为分布式文件系统(distributed filesystem),该架构于网络之上,势必会引起网络编程的复杂性,因此分布式文件系统比普通磁盘文件系统更为复杂。Hadoop 自带一个称为 HDFS 的分布式文件系统,也是 Hadoop 的旗舰级文件系统,即 Hadoop Distributed Filesystem。
HDFS 以流式数据访问模式来存储超大文件,运行于商业硬件集群上。
- 超大文件。这里指的是具有几百
MB、几百GB或者以上大小的文件。 - 流式数据访问。
HDFS采用的是一次写入、多次读写的高效访问模式。 - 商业硬件。运行于各种商业硬件上即可,不需要专业的硬件。
HDFS 相关概念
数据块
每个磁盘都有默认的数据块大小,这是磁盘进行数据读/写的最小单位。构建于单个磁盘之上的文件系统通过磁盘块来管理该文件系统中的块,该文件系统块的大小可以是磁盘块的整数倍,文件系统块一般为几千个字节,而磁盘块一般为 512 字节。HDFS 也同样存在类似块(block)的概念,默认为 128MB。与单一磁盘上的文件系统类似,HDFS 上的文件也会被划分为块大小的多个分块(chunk),作为独立的存储单元。
与单一磁盘文件系统不同之处在于 HDFS 中小于一个块大小的文件不会占据整个块的空间。
那么 HDFS 中的块为什么这么大?有何好处?
HDFS中的块比磁盘的块大,其目的在于最小化寻址开销。如果块足够大,那么从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间,因此传输一个由多个块组成的大文件的时间取决于磁盘传输速率。
默认的块大小为128MB,但是很多情况下HDFS安装时会使用更大的块,并且随着新一代磁盘驱动器传输速率的提升,块的大小会被设置的更大。但是这个参数也不能被设置的太大,MapReduce中的map任务通常一次只处理一个块中的数据,因此如果任务数太少(小于集群中的节点数量),作业的运行速度就会很慢。对分布式文件系统中的块进行抽象带来的好处如下:
- 一个文件的大小可以大于网络中任意一个磁盘的容量。文件的所有块并不需要存储在同一块磁盘上,可以利用集群中任意一个磁盘进行存储。
- 使用抽象块而非整个文件作为存储单元,大大简化存储子系统的设计。将存储子系统的处理对象设置为块,可简化存储管理(块大小已经固定,因此计算存储容量相对容易),同时也消除了对元数据的顾虑(块只需要存储数据即可,并不需要存储文件的元数据,例如权限信息等,这样其它系统可以单独管理这些元数据)。
- 块非常适用于数据备份进而提供数据容错能力和提高可用性。
HDFS 中的 fsck 指令可以展示块信息。用法:
1 | hdfs fsck / -files -blocks |
namenode 和 datanode
HDFS 集群由两类节点以管理节点-工作节点模式运行,即一个 namenode(管理节点)和多个 datanode(工作节点)。
namenode 管理文件系统的命名空间,他维护着文件系统树及整颗树内所有的文件和目录,这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。同时 namenode 也负责记录每个文件中各个块所在的节点信息,但是并不会永久保存块的位置信息,因为这些信息会在系统启动时根据数据节点信息重建。datanode 是文件系统的工作节点,根据需要存储并检索数据块(受客户端或者 namenode 调度),并且还需要定期向 namenode 发送所存储块的列表和心跳请求。
客户端代表用户通过与 namenode 和 datanode 交互来访问整个文件系统,客户端通过提供一个类似于 POSIX 的文件系统接口来实现功能,而不需要知道 namenode 和 datanode 的存在。
细心的人会发现一个 namenode 不会存在单点故障吗?那么 Hadoop 提供了两种机制:
- 备份组成文件系统元数据持久状态的文件。
Hadoop可以通过配置使namenode在多个文件系统上保存元数据的持久状态,这些写操作都是实时同步的,并且还是原子操作。一般的配置都是在持久化本地磁盘时同时写入远程挂载的网络文件系统(NFS)。 - 运行一个辅助
namenode,但是他不能被用作namenode。这个辅助namenode的作用在于定期合并编辑日志与命名空间镜像,以防止镜像日志过大。另外辅助namenode通常部署在另外一台机器上,需要占用大量CPU时间和内存来执行合并操作。由于辅助namenode是定期同步主节点namenode,因此会存在保存的状态滞后于主节点,难免会丢失部分数据,这种情况下都是将远程挂载的NFS复制到辅助namenode作为新的主节点namenode运行。
块缓存
通常 datanode 从磁盘中读取块,但是对于频繁访问的块,该块可能会被显式地存储在 datanode 的内存中,以堆外缓存(off-heap block cache)的形式存在。默认情况下一个块仅缓存在一个 datanode 的内存中(可以针对文件修改 datanode 的数量)。
通过块缓存作业调度器在缓存块的 datanode 上执行任务,可以提高读操作的性能。当然用户可以通过在缓存池(cache pool)中增加一个 cache directive 来告诉 namenode 需要缓存哪些文件缓存多久。
缓存池是一个用于管理缓存权限和资源使用的管理性分组。
联邦 HDFS
namenode 在内存中保存着文件系统中每个文件和每个数据块的引用关系,这也意味着对于一个超大集群来说,内存将成为限制系统横向扩展的瓶颈。不过联邦 HDFS 允许系统通过添加多个 namenode 来实现横向扩展,即每个 namenode 管理文件系统命名空间中的一部分。
例如 A namenode 负责管理 /home/a 下的所有文件,而 B namenode 负责管理 /home/b 下的所有文件。
在联邦环境下每个 namenode 维护一个命名空间卷(namespace volume),由命名空间的元数据和一个数据块池(block pool)组成,数据块池包含该命名空间下文件的所有数据块。
命名空间卷之间是相互独立的,两两之间并不相互通信,甚至某一个 namenode 失效也不会影响到其他 namenode 的可用性;另外命名空间卷下的数据块池不能再切分,这就意味着集群中的 datanode 需要注册到每个 namenode 中,namenode 存储来自多个数据块池中的数据块。
客户端通过使用挂载数据表将文件路径映射到 namenode 来访问联邦 HDFS,通过 ViewFileSystem 和 viewfa://URI 进行配置和管理。
高可用性
通过联合使用在多个文件系统中备份 namenode 的元数据和通过备用 datanode 创建监测点防止数据丢失,但这依然无法解决文件系统的高可用性,namenode 依然存在单点失效(SPOF,single point of failure)的问题,如果 namenode 失效则 MapReduce 作业均无法读、写文件。
在这种情况下从一个失效的 namenode 恢复,管理员需要启动一个拥有文件系统元数据副本的新的 namenode ,并配置 datanode 和客户端以便使用新的 namenode,而新的 namenode 需要达到以下情形才能响应服务:
- 将命名空间的镜像导入内存中。
- 重演编辑日志。
- 接收到足够多的来自
datanode的数据块报告并退出安全模式。
对于一个大型集群 namenode 的冷启动需要 30 分钟以上,甚至更久。
为了解决上述遇到的问题,HDFS 支持在 2.x 版本支持高可用性,即通过配置一对活动-备用(active-standby)namenode。当活动 namenode 失效,备用 namenode 会接管它的任务并开始服务来自客户端的请求,不会有任何明显中断。不过要支持高可用性还需要以下几个方面的支持:
namenode之间通过高可用性共享存储实现编辑日志的共享。datanode需要同时向两个namenode发送数据块处理报告。- 客户端需要使用特定的机制来处理
namenode失效的问题,不过该机制对用户是透明的。 - 辅助
namenode的角色被备用namenode所包含,备用namenode为活动namenode命令空间设置周期性检查点。
命令行接口
命令行
现在通过命令行交互来进一步了解 HDFS,在设置伪分布配置时,有两个属性需要着重说明:
fs.defaultFS:设置为hdfs://localhost/,用于设置Hadoop的默认文件系统。
文件系统由URI指定,使用hdfs URI来配置HDFS为Hadoop的默认文件系统,HDFS的守护程序通过该属性项来确定HDFS namenode的主机及端口。dfs.replication:默认值为3,修改配置值设置为1,不然会出现副本不足的警告,因为HDFS无法将数据块复制到三个datanode上。
至此文件系统已经配置完毕,接下来就可以执行常见的文件系统操作。(相关命令行的内容可以看前一篇文章)
文件访问权限
针对文件和目录,HDFS 的权限模式和 POSIX 的权限模式非常相似。共提供三类权限模式:
- 只读权限(
r):读取文件或列出目录内容时需要该权限。 - 写入权限(
w):写入一个文件或是在一个目录上新建及删除文件或目录需要该权限。 - 可执行权限(
x):该权限对于文件而言可以忽略,不过在访问目录的子项时需要该权限。
每个文件和目录都有所属用户(owner)、所属组别(group)及模式(mode),这个模式是由所有用户的权限、组内用户的权限及其他用户的权限组成。
distcp
DistCp(分布式拷贝)是用于大规模集群内部和集群之间拷贝的工具,使用 Map/Reduce 实现文件分发、错误处理和恢复以及报告生成。通过把文件和目录的列表作为 map 任务的输入,每个任务会完成源列表中部分文件的拷贝。用法:
1 | bin/hadoop distcp [-p [rbugp]] [-i] [-log <logdir>] [-m <num_maps>] [-overwrite] [-update] [-f <urilist_uri>] <source-path> <dest-path> |
上述命令仅限于相同版本的 HDFS 之间拷贝数据。
p
保存文件信息。rbugp分别表示 副本数量、块大小、用户、组、权限。i
忽略失败log
记录日志到<logdir>m
同时拷贝的最大数目。overwrite
是否覆盖目标。update
如果源和目标的大小不一样则进行覆盖。f
使用<urilist_uri>作为源文件列表。
文件系统
Hadoop 有一个抽象的文件系统概念,而 HDFS 只是其中的一个实现。Java 抽象类 org.apache.hadoop.fs.FileSystem 定义了 Hadoop 文件系统的客户端接口,并且该抽象类也有几个具体的实现:
| 文件系统 | URI |
Java 实现 |
描述 |
|---|---|---|---|
Local |
file |
fs.LocalFileSystem |
使用客户端校验和的本地磁盘文件系统。其中使用 RawLocalFileSystem 表示无校验和的本地磁盘文件系统 |
HDFS |
hdfs |
hdfs.DistributedFileSystem |
Hadoop 的分布式文件系统。将 HDFS 设计成与 MapReduce 结合使用,可以实现高性能。 |
WebHDFS |
Webhdfs |
Hdfs.web.WebHdfsFileSystem |
基于 HTTP 的文件系统,提供对 HDFS 的认证读/写访问。 |
Secure WebHdfs |
swebhdfs |
hdfs.web.SWebHdfsFileSystem | WebHDFS 的 HTTPS 版本 |
HAR |
har |
fa.HarFileSystem |
一个构建在其他文件系统之上用于文件存档的文件系统。Hadoop 存档文件通常用于将 HDFS 中的多个文件打包成一个存档文件,以减少 namenode 内存的使用。使用 hadoop 的 achive 命令来创建 HAR 文件。 |
View |
viewfs |
viewfs.ViewFileSystem |
针对其他 Hadoop 文件系统的客户端挂载表。通常用于为联邦 namenode 创建挂载点。 |
FTP |
ftp |
fa.ftp.FTPFileSystem |
由 FTP 服务器支持的文件系统 |
S3 |
S3a |
fa.s3a.S3AFileSystem |
由 Amazon S3 支持的文件系统。替代老版的 s3n 实现。 |
Azure |
wasb |
fs.azure.NativeAzureFileSystem |
由 Microsoft Azure 支持的文件系统。 |
Swift |
swift |
fs.swift.snative.SwiftNativeFileSystem |
由 OpenStack Swift 支持的文件系统。 |
Hadoop 对文件系统提供了许多接口,一般使用 URI 方案来选取合适的文件系统实例进行交互。例如列出本地文件系统根目录下的文件:
1 | bin/hadoop fs -ls file:/// |
接口
Hadoop 是用 Java 写的,通过 Java API 可以调用大部分 Hadoop 文件系统的交互操作。
HTTP
非Java开发的应用访问HDFS会很不方便,因此由WebHDFS协议提供的HTTP REST API则使得其他语言开发的应用能够更方便地与HDFS交互。HTTP接口比原生Java客户端要慢,因此尽量不要传输特大数据。通过
HTTP访问HDFS有两种方法:- 直接访问,
HDFS守护进程直接服务于来住客户端的HTTP请求。
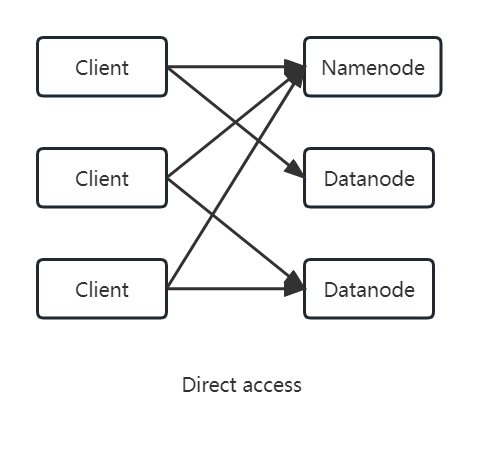
namenode和datanode内嵌的web服务器作为WebHDFS的端节点运行。文件元数据操作由namenode管理,文件读/写操作首先被发往namenode,由namenode发送一个HTTP重定向至某个客户端,指示以流方式传输文件数据的目的或源datanode。(由于dfs.webhdfs.enabled被设置为true,WebHDFS默认是启用状态) - 通过代理(一个或多个)访问,客户端通常使用
DistributedFileSystem API访问HDFS。
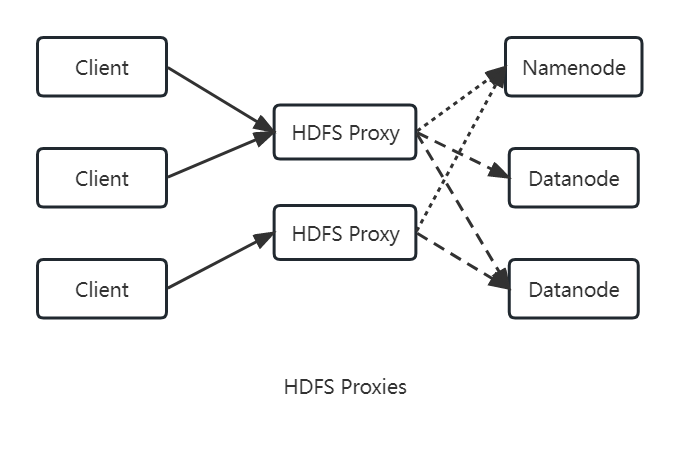
依靠一个或多个独立代理服务器通过HTTP访问HDFS。所有到集群的网路通信都需要经过代理,因此客户端从不直接访问namenode和datanode。HttpFS代理提供和WebHDFS相同的HTTP和HTTPS接口,这样客户端能够通过webhdfs URI协议访问这类接口。
httpFS代理的启动独立于namenode和datanode的守护进程,使用httpfs.sh脚本启动,默认在一个不同的端口上监听(端口号为14000)。
上述两者都使用了
WebHDFS协议。- 直接访问,
CHadoop提供了一个名为libhdfs的C语言库,该语言库是Java FileSystem接口类的一个镜像,使用Java原生接口(JNI, Java Native Interface)调用Java文件系统客户端。同时还有一个libwebhdfs库,该库是WebHDFS接口的实现。NFS
使用Hadoop的NFSv3网关将HDFS挂载为本地客户端的文件系统的想法是可行的。可以通过使用Unix程序与该文件系统交互,通过任意一种编程语言调用POSIX库来访问文件系统,由于HDFS仅能以 追加模式 写文件,因此可以往文件末尾添加数据,但不能随即修改文件。FUSE
用户空间文件系统(FUSE, FileSystem in Userspace)允许将用户空间实现的文件系统作为Unix文件系统进行集成。通过使用Hadoop的Fuse-DFS功能模块,HDFS或者任何一个Hadoop文件系统均可以作为一个标准的本地文件系统进行挂载。Fuse-DFS是用C语言实现的,使用libhdfs作为访问HDFS的接口。
对于挂载HDFS的解决方案,Hadoop NFS相比Fuse-DFS更优先选择。
Java 接口
该部分主要探索 Hadoop 的 FileSystem 类,该类是与 Hadoop 的某一个文件系统进行交互的 API。
读取数据
Hadoop URL
从 Hadoop 文件系统读取文件,最简单的办法就是使用 java.net.URL 对象打开数据流,然后从中读取数据。示例:
1 | public class CatURL { |
运行示例:
1 | % bin/hadoop CatURL hdfs://localhost/user/vgbh/test.txt |
Java 程序要想识别 Hadoop 的 hdfs URL,需要通过 FsUrlStreamHandlerFactory 实例调用 java.net.URL 对象的 setURLStreamHandlerFactory 方法。另外可以调用 Hadoop 中的 IOUtils 类,并在 finally 子句中关闭数据流,同时在输入流和输出流之间复制数据。setURLStreamHandlerFactory 方法在每一个虚拟机中只能被调用一次,通常在静态方法中调用,该限制则意味着如果程序的其他组件已经声明了 FsUrlStreamHandlerFactory 实例,那么就不能使用该方法从 Hadoop 中读取数据。
FileSystem API
前一个部分有时候会遇到不能设置 FsUrlStreamHandlerFactory 实例,那么这种情况下可以使用 FileSystem API 来打开一个文件的输入流。Hadoop 文件系统通过 Hadoop Path 对象来表示一个文件,因此可以将路径视为一个文件系统 URI 。
FileSystem 是一个通用的文件系统 API,那么第一步就是获取对应的文件系统实例:
1 | public static FileSystem get(Configuration conf [,URI uri] [,String user]) throws IOException |
conf:Configuration对象封装了客户端或服务器的配置,通过配置文件读取类路径来实现(etc/hadoop/core-site.xml)。uri:根据给定的URI确定使用的文件系统。user:给定用户来访问文件系统。
在某些情况下希望获得本地文件系统的运行实例,此时使用 getLocal 方法会更加方便:
1 | public static LocalFileSystem getLocal(Configuration conf) throws IOException |
接下来的第二部就是在获取到 FileSystem 之后,就可以调用 open() 函数来获取文件的输入流:
1 | public FSDataInputStream open(Path f [,int bufferSize]) throws IOException |
bufferSize 表示可设置缓冲区的大小,不设置时默认大小为 4KB。
完整代码如下:
1 | public class CatFileSystem { |
运行示例:
1 | % bin/hadoop CatFileSystem hdfs://localhost/user/vgbh/test.txt |
关于更多的使用方法可以了解下 FileSystem 的接口类 Seekable 和 PositionedReadable
写入数据
FileSystem 类有一系列新建文件的方法。
最简单的方法就是给准备创建的文件一个
Path对象,然后返回一个用于写入数据的输出流:1
public FSDataOutputStream create(Path f) throws IOException
此方法有多个重载版本,允许指定是否强制覆盖现有文件、文件备份数量、写入文件时缓冲区大小、文件块大小以及文件权限。还有一个重载方法
Progressable用于传递回调接口,可以将数据写入datanode的进度通知给应用。create()方法能够为需要写入当当前并不存在的文件创建父目录。如果不希望这样,可以在写入时先调用exist()方法检查父目录是否存在。使用
append()方法在一个现有文件的末尾追加数据,追加操作允许一个writer打开文件后在访问该文件的最后偏移量处追加数据:1
public FSDataOutputStream append(Path f) throws IOException
FSDataOutputStream 与 FSDataInputStream 不同之处在于,前者不允许在文件中定位。因为 HDFS 只允许对一个已打开的文件顺序写入或者在末尾添加数据。
完整示例代码如下:
1 | public class FileCopyWithProgress { |
运行示例:
1 | % bin/hadoop FileCopyWithProgress input/vgbh/a.txt hdfs://localhost/user/vgbh/test_1.txt |
目录
FileSystem 实例提供了创建目录的方法,该方法可以一次性创建所有必要但还没有的目录,均创建成功后返回 true
1 | public boolean mkdirs(Path f) throws IOException |
查询文件
文件元数据
任何文件系统的重要特征其中之一都是提供其目录结构浏览和检索所存文件和目录相关信息的功能。FileStatus 类封装了文件系统中文件和目录的元数据,包括文件长度、块大小、复本、修改时间、所有者以及权限信息。FileSystem 的 getFileStatus() 方法用于获取文件或目录的 FileStatus 对象。
1 | public FileStatus getFileStatus(Path f) throws FileNotFoundException |
列表
在查找到文件或目录的相关信息后,那么就下来就是列出目录中的内容。FileSystem 的 listStatus() 方法可以实现:
1 | public FileStatus[] listStatus(Path f [,PathFilter filter]) throws IOException |
当 f 传入的参数为一个文件时,那么就会返回数组长度为 1 的 FileStatus 对象;但若是一个目录时,则返回多个 FileStatus 对象,表示此目录中包含的目录和文件。另外重载方法允许使用 PathFilter 来限制匹配的文件和目录 。
文件模式
偶尔会出现在单个操作中处理一批文件的需求。因此在一个表达式中使用通配符来匹配多个文件正是解决办法,无需列举每个文件和目录来指定输入。Hadoop 为执行通配符提供了 globStatus() 方法,该方法返回路径格式与指定模式匹配的所有 FileStatus 组成的数组,并按路径排序。PathFilter 参数作为可选项进一步对匹配结果进行限制。
1 | public FileStatus[] globStatus(Path pathPattern [,PathFilter filter]) throws IOException |
另外 Hadoop 支持的通配符与 Unix bash shell 支持的相同。
PathFilter 对象
通配符模式有时并不能够精确地描述想要的文件集。因此 FileSystem 的 listStatus() 和 globStatus() 方法均提供了可选的 PathFilter 对象来控制通配符。
1 | public interface PathFilter { |
删除数据
FileSystem 的 delete() 方法可以永久性删除文件或目录。如果 f 是一个文件或空目录,则 recursive 值就会被忽略,只有值为 true 时非空目录及其内容才会被删除,否则会抛出 IOException 异常。
1 | public boolean delete(Path f, boolean recursive) throws IOException |
数据读取和写入
了解客户端如何与 HDFS、datanode、namenode 进行交互,明白如何读取和写入文件。
剖析读取
下图展示在读取文件时事件的发生顺序: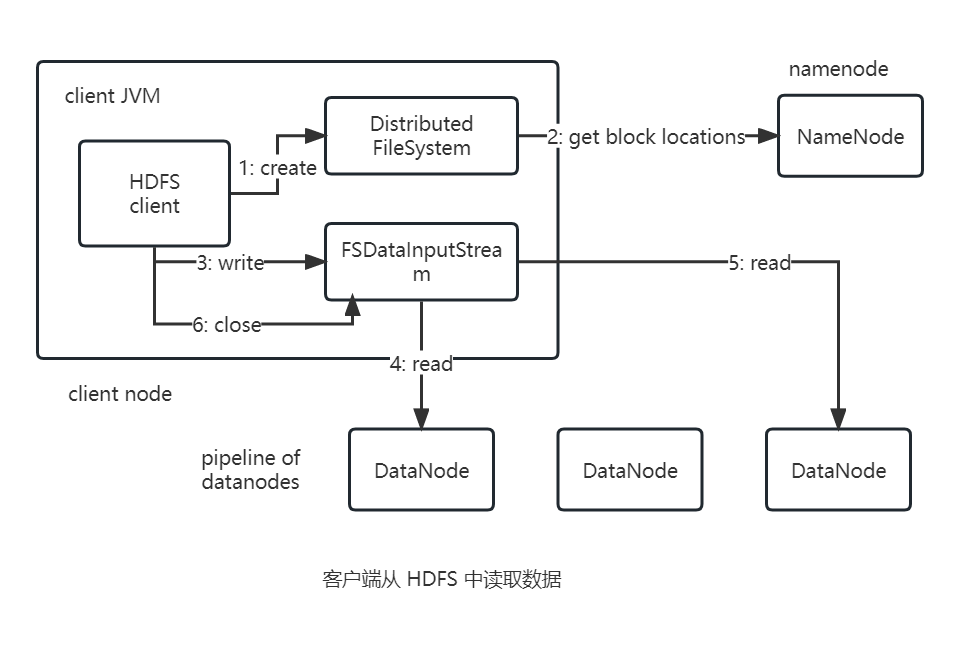
open
客户端通过调用FileSystem对象的open()方法来打开需要读取的文件,对于HDFS来说该文件就是一个DistributedFileSystem实例。get block locationsDistributedFileSystem实例通过远程过程调用(RPC)来调用namenode,以确定文件起始块的位置。DistributedFileSystem类返回一个FSDataInputStream对象(支持文件定位的输入流)给客户端以便读取数据。FSDataInputStream类内部封装DFSInputStream对象,该对象管理datanode和namenode的I/O。
对于每一个数据块,namenode会返回存有该块副本的datanode地址,该地址根据距离客户端的距离进行排序。read
接着客户端对输入流调用read()方法,存储着文件起始几个块的datanode地址的DFSInputStream随即连接距离最近的文件中第一个块所在的datanode。
在读取数据时如果遇到异常(例如通信异常或者检查校验和未通过),会尝试从这个块的另一个邻近的datanode读取数据,然后标记这个datanode,之后不会再在这个datanode上读取数据。read
通过对数据流反复调用read()方法,就可以将数据从datanode传输到客户端。read
在读取到数据的末端时,DFSInputStream关闭与该datanode的连接,然后寻找下一个块的最佳datanode。这些内部操作对于客户端都是透明的,对客户端来说一直在读取一个连续的数据流。
客户端从流中读取数据时,块是按照打开DFSInputStream与datanode新建连接的顺序读取的,同时也会根据需要询问namenode来检索下一批数据块的datanode的位置。close
一旦客户端读取数据完成,FSDataInputStream就会调用close()方法。
关于距离客户端最近的 datanode 的网络拓扑可以自行了解。
剖析写入
下图展示文件是如何写入 HDFS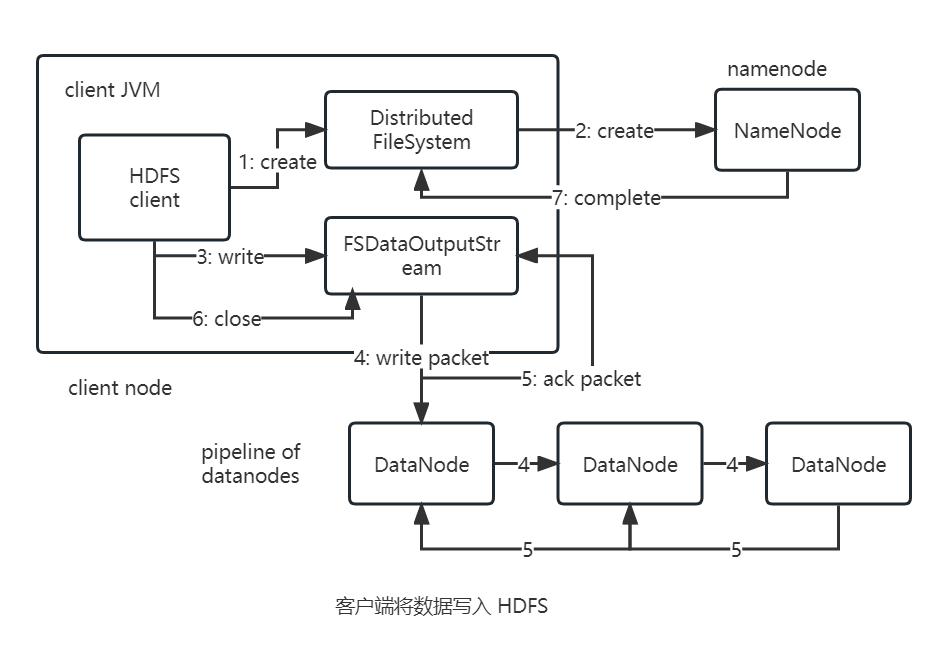
create
客户端通过对DistributedFileSystem对象调用create()方法来新建文件。createDistributedFileSystem对象对namenode发起一个RPC调用,在文件系统的命名空间中新建一个空文件(还没有相应的数据块),namenode在收到请求后开始执行各种不同的检查以确保该文件不存在且客户端有创建该文件的权限。接着DistributedFileSystem向客户端返回一个FSDataOutputStream对象,然后客户端开始写入数据。FSDataOutputStream内部封装了一个DFSOutputStream对象,该对象负责处理datanode和namenode之间的通信。write
在客户端写入数据时,DFSOutputStream将它分成一个个的数据包,并写入内部队列,称为数据队列(data queue)。write packetDataStreamer处理数据队列,挑选出适合存储数据副本的一组datanode,并据此来要求namenode分配新的数据块;一组datanode组成一个管线,DataStreamer将数据包以流式传输到管线中第一个datanode,该datanode存储数据包并将它发送到下一个管线中,以此类推知道datanode数量达到设置的复本数量。ack packetDFSOutputStream内部也维护着一个内部数据包队列来等待datanode的收到确认回执,称为确认队列(ack queue)。收到管道中所有datanode确认信息后,该数据包才会从确认队列中被删除。close
客户端完成数据的写入后,对数据流调用close()方法。complete
该操作将剩余的所有数据包写入datanode管线,并在联系到namenode告知其文件写入完成之前等待确认。namenode此时已知写入文件有哪些块组成(DataStreamer请求分配数据块),因此最终只需要等待数据块完成最小量的复制就会返回成功。
一致模型
文件系统的一致模型(coherency mode)描述了文件读/写的数据可见性。HDFS 为了满足性能牺牲了一些 POSIX 要求,具体如下:
- 新建文件后能立即在文件系统的命名空间中可见,但是写入文件的内容并不能立即可见。
- 当写入的数据超过一个块后,第一个数据块对于新的
reader是可见的,总之当前正在写入的块对于其他reader不可见。 HDFS中的FSDataOutputStream类使用hflush()方法可以将所有缓存刷新到datanode中;hflush()方法执行成功后,对于所有新的reader而言,HDFS可以保证目前已写入到文件中的数据均到达datanode的管道且对所有的reader都是可见的。- 注意
hflush()方法不能保证datanode已经将数据写到磁盘上,仅确保数据保存在datanode的内存中。hsync()方法可以确保将数据写入到磁盘上,类似于POSIX中的fsync()系统调用。
关于在何时调用 hflush() 和 hsync() 需要在应用程序和性能之间做平衡,选择最合适的调用频率。
引用
Hadoop-基础
Hadoop源生实用工具之distcp
Unix bash shell
个人备注
此博客内容均为作者学习所做笔记,侵删!
若转作其他用途,请注明来源!