示例代码
1 | import graphql.ExecutionResult; |
简介
前提
Relay 是一种构建客户端应用程序的新方法,这些应用程序可以共同定位数据获取要求和React 组件。
我们不是将数据提取逻辑放在客户端应用程序的其他部分中 - 或者将此逻辑嵌入到服务器上的自定义端点中 - 而是与React 组件一起共同定位声明性数据获取规范。
此声明性规范的语言是GraphQL。
GraphQL
GraphQL 查询是由服务器解释的字符串,它返回指定格式的数据。
示例查询:
1 | { |
响应查询:
1 | { |
设计原则
- 分层
今天的大多数产品开发涉及视图层次结构的创建和操作。为了与这些应用程序的结构保持一致,GraphQL 查询本身是一组分层的字段。查询的形状就像它返回的数据一样。这是产品工程师描述数据要求的自然方式。 - 以产品为中心
GraphQL 是由视图和编写它们的前端工程师的要求无缘无故地驱动的。我们从他们的思维方式和要求开始,并构建实现这一点所必需的语言和运行时。 - 客户端指定的查询
在GraphQL中,查询规范在客户端而不是服务器中编码。这些查询以字段级粒度指定。在没有GraphQL 编写的绝大多数应用程序中,服务器确定在其各种脚本化端点中返回的数据。另一方面,GraphQL查询返回客户端要求的内容,而不再返回。 - 向后兼容
在没有强制升级的已部署本机移动应用程序的世界中,向后兼容性是一项挑战。例如,Facebook 在两周的固定周期内发布应用程序,并承诺维护这些应用程序至少两年。这意味着每个平台至少有 52个版本的客户端在任何给定时间查询我们的服务器。客户端指定的查询简化了对向后兼容性保证的管理。 - 结构化、任意代码
具有字段级粒度的查询语言通常直接查询存储引擎,例如SQL 。相反,GraphQL 将结构强加到服务器上,并公开由任意代码支持的字段。这允许服务器端灵活性和应用程序的整个表面区域上的统一,强大的API。 - 应用层协议
GraphQL 是一种应用层协议,不需要特定的传输。它是由服务器解析和解释的字符串。 - 强类型
GraphQL 是强类型的。给定查询,工具可以确保在执行之前,即在开发时,在GraphQL 类型系统中查询在语法上是正确和有效的,并且服务器可以对响应的形状和性质做出某些保证。这样可以更轻松地构建高质量的客户端工具。 - 内省
GraphQL 是内省的。客户端和工具可以使用GraphQL 语法本身查询类型系统。这是一个用于构建工具和客户端软件的强大平台,例如将输入数据自动解析为强类型接口。它在静态类型语言(如Swift ,Objective-C 和Java )中特别有用,因为它不需要重复且容易出错的代码将原始的,无类型的JSON 混合到强类型的业务对象中。
Spring Boot 开发
详细的开发内容,可以看我的Github地址。
全栈教程
这里有一个免费的开源教程开发网站,你可以试试。
简介
- 模式驱动的开发
开发合同(无论是以WSDL 还是Swagger 或其他任何形式)通常会预先深入而准确地理解客户的数据需求,而这种理解通常只是随着时间的推移而发展起来的。GraphQL 通过决定将哪些数据提取到客户端的独占域来方便地消除了这个障碍,从而开启了更顺畅的API演进的路径。GraphQL的自描述性质(通过内省查询)进一步补充了这一点,使得契约优先(或者更确切地说,在GraphQL 语言中的模式优先)方法既自然又简单。
GraphQL 中的模式是客户端和服务器之间的中心契约,描述了服务器提供的所有类型的数据以及所有操作(查询和突变)。除了客户端 - 服务器独立性和易于模拟的通常承诺之外,以模式优先的方式开发有助于实现将逻辑结构化为更简单和更简单的功能(单一责任原则)的良好实践,可以方便地用作解析器。
入门
初始化项目
本教程将使用Maven,请选择你喜欢的IDE 和适当的Maven 版本。定义架构
重要的是要注意,解析器函数是字段定义的组成部分,因此是模式的一部分。这意味着模式不仅仅是一个文档,而是一个运行时对象实例。
架构可以通过两种方式定义:以编程方式 - 在代码中手动组装类型定义。
使用模式定义语言(SDL) - 其中模式是从与前面章节中看到的文本语言无关的描述生成的,然后使用解析器函数动态连接。
前者并置了字段及其相关的结果,而后者则在数据和行为之间进行了明确的划分。我们将在此的大部分内容中使用SDL ,因为它允许简洁的示例。
表示链接的简单类型的SDL 定义可能如下:1
2
3
4type Link {
url: String!
description: String!
}并且获取所有链接的查询方式可以定义为:
1
2
3type Query {
allLinks: [Link]
}最后,包含此查询模式将定义为:
1
2
3schema {
query: Query
}将这些定义保存为一个名为schema.graphqls的文件中。
安装依赖项
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-java</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-java-tools</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-java-servlet</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.0.1</version>
<scope>provided</scope>
</dependency>其中对应的版本,可以自行修改。
设置服务器
对于jetty ,将插件添加到build部分。1
2
3
4
5
6
7
8
9
10<build>
<finalName>hackernews</finalName>
<plugins>
<plugin>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-maven-plugin</artifactId>
<version>9.4.6.v20170531</version>
</plugin>
</plugins>
</build>添加以下插件配置,将Java版本设为8,将servlet版本设为3.1。
1
2
3
4
5
6
7
8
9
10
11
12
13
14<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-war-plugin</artifactId>
<version>3.1.0</version>
</plugin>下面就配置可运行的类。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import com.coxautodev.graphql.tools.SchemaParser;
import javax.servlet.annotation.WebServlet;
import graphql.servlet.SimpleGraphQLServlet;
@WebServlet(urlPatterns = "/graphql")
public class GraphQLEndpoint extends SimpleGraphQLServlet {
public GraphQLEndpoint() {
super(SchemaParser.newParser()
.file("schema.graphqls") //parse the schema file created earlier
.build()
.makeExecutableSchema());
}
}现在启动服务器并访问http://localhost:8080/graphql 仍然会导致错误,因为没有连接解析器函数(因此定义的allLinks查询无法执行)。
一个简单的查询
查询解析器
为了保持强类型和直观设计,通常用等效的Java类表示GraphQL类型,用方法表示字段。graphql-java-tools定义了两种类型的类:数据类,它们为域建模,通常是简单的POJO,以及解析器,它们对查询和突变进行建模并包含解析器函数。通常,两者都需要对单个GraphQL类型进行建模。
目前为止的架构如下:1
2
3
4
5
6
7
8
9
10
11
12type Link {
url: String!
description: String!
}
type Query {
allLinks: [Link]
}
schema {
query: Query
}对他建模需要两个类:Link 和Query 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class Link {
private final String url;
private final String description;
public Link(String url, String description) {
this.url = url;
this.description = description;
}
public String getUrl() {
return url;
}
public String getDescription() {
return description;
}
}你还应该创建一个LinkRepository 类,它将整齐地隔离从存储中保存和加载链接的问题。这也使未来的扩展和重构变得更加容易。目前,链接只会保存在内存中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class LinkRepository {
private final List<Link> links;
public LinkRepository() {
links = new ArrayList<>();
//add some links to start off with
links.add(new Link("http://howtographql.com", "Your favorite GraphQL page"));
links.add(new Link("http://graphql.org/learn/", "The official docks"));
}
public List<Link> getAllLinks() {
return links;
}
public void saveLink(Link link) {
links.add(link);
}
}返回链接
与Link POJO 不同,Query 模型行为,因为它包含查询的解析器allLinks 。1
2
3
4
5
6
7
8
9
10
11
12public class Query implements GraphQLRootResolver {
private final LinkRepository linkRepository;
public Query(LinkRepository linkRepository) {
this.linkRepository = linkRepository;
}
public List<Link> allLinks() {
return linkRepository.getAllLinks();
}
}最后,您可以更新GraphQLEndpoint以在生成架构时正确注册解析器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class GraphQLEndpoint extends SimpleGraphQLServlet {
public GraphQLEndpoint() {
super(buildSchema());
}
private static GraphQLSchema buildSchema() {
LinkRepository linkRepository = new LinkRepository();
return SchemaParser.newParser()
.file("schema.graphqls")
.resolvers(new Query(linkRepository))
.build()
.makeExecutableSchema();
}
}注意如何将模式构建逻辑提取到一个单独的方法中,以便于将来添加。
如果您现在打开http://localhost:8080/graphql?query={allLinks{url}} ,您将看到您的第一个GraphQL查询正在执行,并为您提供如下结果:1
2
3
4
5
6
7
8
9
10
11
12{
"data": {
"allLinks": [
{
"url": "http://howtographql.com"
},
{
"url": "http://graphql.org/learn/"
}
]
}
}使用GraphiQL进行测试
GraphiQL是一个浏览器内的IDE,允许您探索模式,触发查询/突变并查看结果。
在index.html中添加对应的内容。1
2<link rel="stylesheet" href="//cdn.jsdelivr.net/npm/graphiql@0.11.2/graphiql.css" />
<script src="//cdn.jsdelivr.net/npm/graphiql@0.11.2/graphiql.js"></script>启动Jetty并打开http://localhost:8080/ ,你应该会看到一个很酷的环境,你可以测试你到目前为止构建的内容。
本次的测试内容: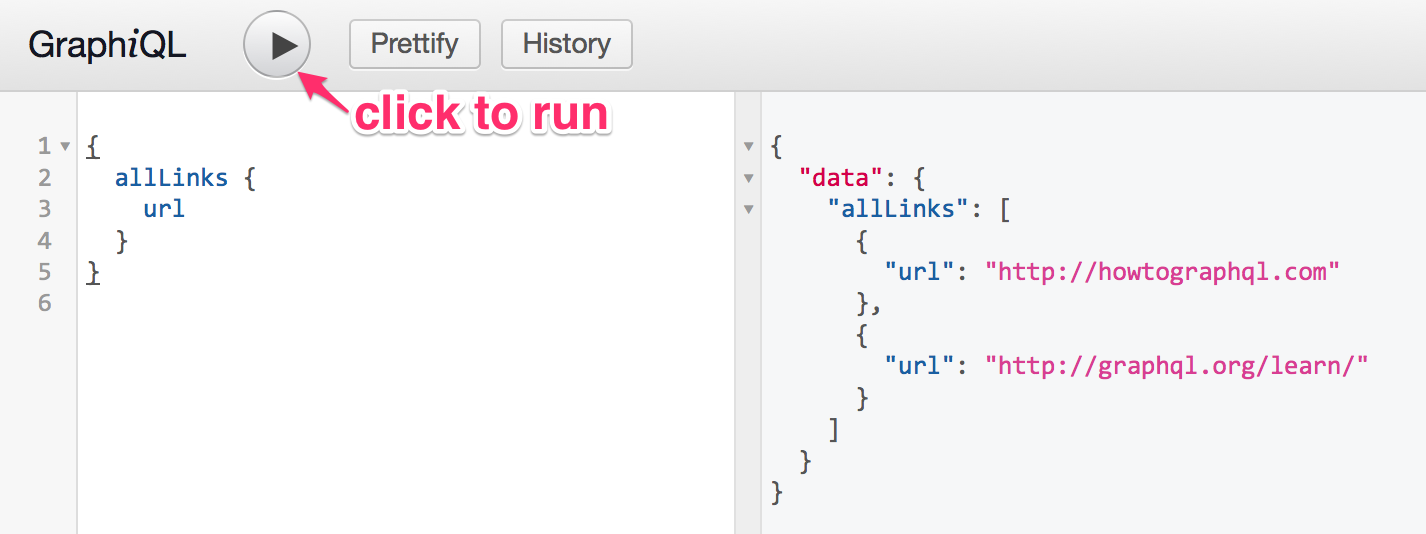
突变
首先描述在SDL 中创建链接的变动:
1 | type Mutation { |
添加此定义
1 | schema { |
带参数的解析器
创建变动的解析器(类似于已有的Query类):1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Mutation implements GraphQLRootResolver {
private final LinkRepository linkRepository;
public Mutation(LinkRepository linkRepository) {
this.linkRepository = linkRepository;
}
public Link createLink(String url, String description) {
Link newLink = new Link(url, description);
linkRepository.saveLink(newLink);
return newLink;
}
}最后,以与Query 在内部注册相同的方式注册这个新的解析器GraphQLEndpoint#buildSchema:
1
2
3
4
5
6
7
8private static GraphQLSchema buildSchema() {
LinkRepository linkRepository = new LinkRepository();
return SchemaParser.newParser()
.file("schema.graphqls")
.resolvers(new Query(linkRepository), new Mutation(linkRepository))
.build()
.makeExecutableSchema();
}创建链接
使用GraphiQL重新启动Jetty并测试: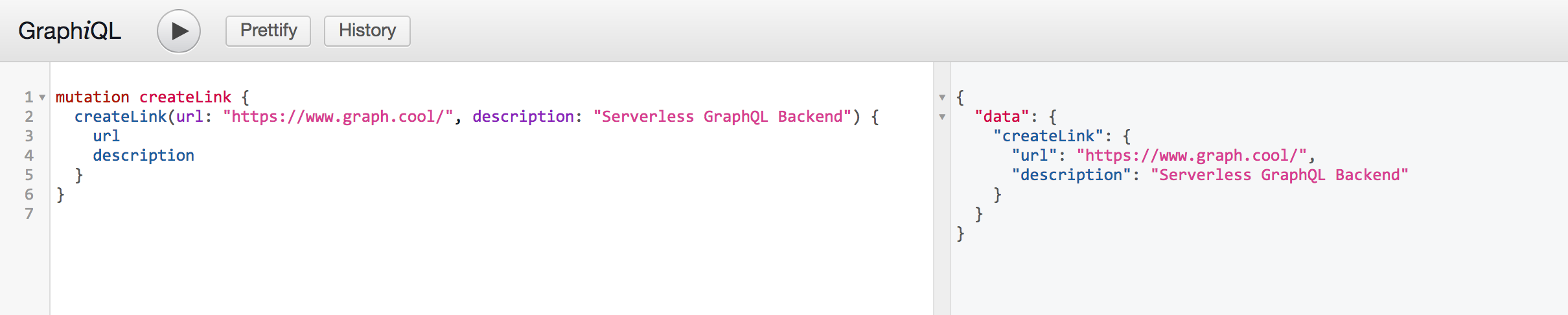
验证测试内容: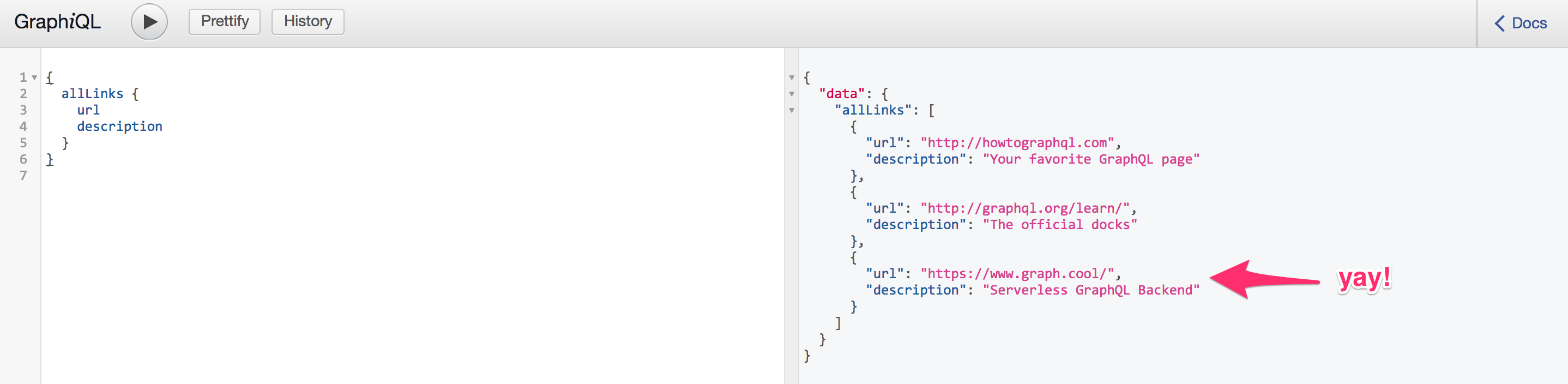
连接器
尽管它很有趣,但如果GraphQL API 没有连接到其他系统,无论是数据库,第三方API 还是类似的,它都不太可能有用。
由于解析器负责获取单个字段的值,因此很容易想象,在单个查询响应中,值可能同时来自多个存储和第三方API,而客户端不会受到影响。
重构链接类型
添加id 字段到Link 类型中1
2
3
4
5type Link {
id: ID!
url: String!
description: String
}类似的,重构Link 类以添加新字段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public class Link {
private final String id; //the new field
private final String url;
private final String description;
public Link(String url, String description) {
this(null, url, description);
}
public Link(String id, String url, String description) {
this.id = id;
this.url = url;
this.description = description;
}
public String getId() {
return id;
}
public String getUrl() {
return url;
}
public String getDescription() {
return description;
}
}连接Mongo DB
此项目,将使用Mongo DB 作为持久化存储,但通过完全遵循相同的方法,也可以集成其他的任意第三方系统成为解析器的基础服务程序。
- 安装Mongo DB
- 为项目添加依赖
1
2
3
4
5<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongodb-driver</artifactId>
<version>3.4.2</version>
</dependency> - 重构LinkRepository ,以便它持久化并加载来自MongoDB 的链接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35public class LinkRepository {
private final MongoCollection<Document> links;
public LinkRepository(MongoCollection<Document> links) {
this.links = links;
}
public Link findById(String id) {
Document doc = links.find(eq("_id", new ObjectId(id))).first();
return link(doc);
}
public List<Link> getAllLinks() {
List<Link> allLinks = new ArrayList<>();
for (Document doc : links.find()) {
allLinks.add(link(doc));
}
return allLinks;
}
public void saveLink(Link link) {
Document doc = new Document();
doc.append("url", link.getUrl());
doc.append("description", link.getDescription());
links.insertOne(doc);
}
private Link link(Document doc) {
return new Link(
doc.get("_id").toString(),
doc.getString("url"),
doc.getString("description"));
}
} - 将Query 类中的allLinks 方法更新为现在调用linkRepository.getAllLinks() 而不是linkRepository.allLinks() 。
- 您还必须更新GraphQLEndpoint以连接到MongoDB。
links从MongoDB 获取集合并提供给它LinkRepository。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public class GraphQLEndpoint extends SimpleGraphQLServlet {
private static final LinkRepository linkRepository;
static {
//Change to `new MongoClient("<host>:<port>")`
//if you don't have Mongo running locally on port 27017
MongoDatabase mongo = new MongoClient().getDatabase("hackernews");
linkRepository = new LinkRepository(mongo.getCollection("links"));
}
public GraphQLEndpoint() {
super(buildSchema());
}
private static GraphQLSchema buildSchema() {
return SchemaParser.newParser()
.file("schema.graphqls")
.resolvers(new Query(linkRepository), new Mutation(linkRepository))
.build()
.makeExecutableSchema();
}
}
- 性能
您可能已经注意到,到目前为止看到的执行策略有些复杂。想象一下,链接描述存储在不同的数据库中。这意味着像这样的查询字段的解析器description(对结果中的每个链接调用一次)将查询其他数据库,因为有多次链接。这是N + 1 问题的典型例子。解决方案是批量处理多个请求并一次解决它们。对于SQL 数据库,所需的解析器将如下所示:1
2
3
4
5query links {
allLinks {
description
}
}1
SELECT * FROM Descriptions WHERE link_id IN (1,2,3) // fetch descriptions for 3 links at once
认证
到目前为止一切都那么好,但如果不跟踪当前用户是谁,就不可能进行大量的交互。要成为一个很酷的Hackernews ,你的应用程序需要能够让用户注册和登录。
创建用户
- 定义变量和类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15type Mutation {
#The new mutation
createUser(name: String!, authProvider: AuthData!): User
createLink(url: String!, description: String!): Link
}
type User {
id: ID!
name: String!
email: String
password: String
}
input AuthData {
email: String!
password: String!
} - 创建的Java 类型:
User类:AuthData类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34public class User {
private final String id;
private final String name;
private final String email;
private final String password;
public User(String name, String email, String password) {
this(null, name, email, password);
}
public User(String id, String name, String email, String password) {
this.id = id;
this.name = name;
this.email = email;
this.password = password;
}
public String getId() {
return id;
}
public String getName() {
return name;
}
public String getEmail() {
return email;
}
public String getPassword() {
return password;
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public class AuthData {
private String email;
private String password;
public AuthData() {
}
public AuthData(String email, String password) {
this.email = email;
this.password = password;
}
public String getEmail() {
return email;
}
public String getPassword() {
return password;
}
public void setEmail(String email) {
this.email = email;
}
public void setPassword(String password) {
this.password = password;
}
} - 那么我觉得还需要一个新的存储库类来加载和存储用户LinkRepository。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42public class UserRepository {
private final MongoCollection<Document> users;
public UserRepository(MongoCollection<Document> users) {
this.users = users;
}
public User findByEmail(String email) {
Document doc = users.find(eq("email", email)).first();
return user(doc);
}
public User findById(String id) {
Document doc = users.find(eq("_id", new ObjectId(id))).first();
return user(doc);
}
public User saveUser(User user) {
Document doc = new Document();
doc.append("name", user.getName());
doc.append("email", user.getEmail());
doc.append("password", user.getPassword());
users.insertOne(doc);
return new User(
doc.get("_id").toString(),
user.getName(),
user.getEmail(),
user.getPassword());
}
private User user(Document doc) {
if (doc == null) {
return null;
}
return new User(
doc.get("_id").toString(),
doc.getString("name"),
doc.getString("email"),
doc.getString("password"));
}
} - 在添加新的createUser 解析器之前Mutation ,你必须重构它以接受构造函数中的UserRepository 实例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class Mutation implements GraphQLRootResolver {
private final LinkRepository linkRepository;
private final UserRepository userRepository;
public Mutation(LinkRepository linkRepository, UserRepository userRepository) {
this.linkRepository = linkRepository;
this.userRepository = userRepository;
}
public Link createLink(String url, String description) {
//stays the same
}
public User createUser(String name, AuthData auth) {
User newUser = new User(name, auth.getEmail(), auth.getPassword());
return userRepository.saveUser(newUser);
}
} - 最后,只需要实例化UserRepository 并更新架构构建逻辑GraphQLEndpoint 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15private static final LinkRepository linkRepository;
private static final UserRepository userRepository; //the new field
static {
MongoDatabase mongo = new MongoClient().getDatabase("hackernews");
linkRepository = new LinkRepository(mongo.getCollection("links"));
userRepository = new UserRepository(mongo.getCollection("users"));
}
//the rest is the same
private static GraphQLSchema buildSchema() {
return SchemaParser.newParser()
.file("schema.graphqls")
.resolvers(new Query(linkRepository), new Mutation(linkRepository, userRepository))
.build()
.makeExecutableSchema();
} - 下面就是测试了。
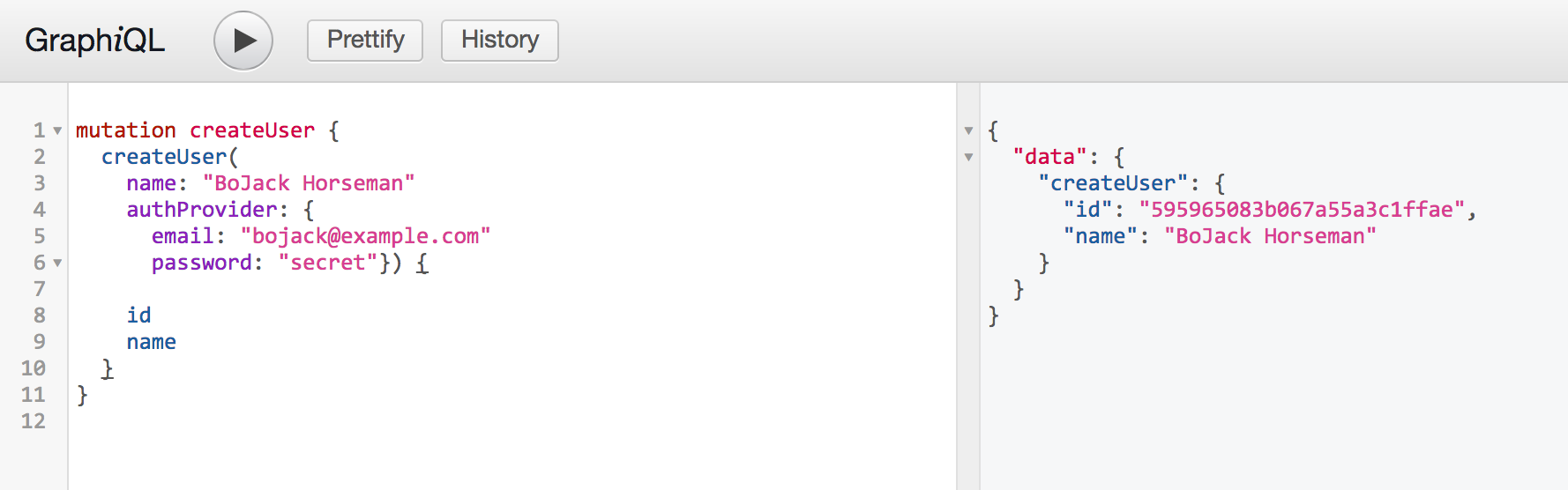
登录
- 首先在模式中定义新的变异和相关类型:
1
2
3
4
5
6
7
8type Mutation {
#other mutations stay the same
signinUser(auth: AuthData): SigninPayload
}
type SigninPayload {
token: String
user: User
} - 创建一个新类来为新类型建模
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class SigninPayload {
private final String token;
private final User user;
public SigninPayload(String token, User user) {
this.token = token;
this.user = user;
}
public String getToken() {
return token;
}
public User getUser() {
return user;
}
} - SigninPayload 数据类包含复杂(非标量)对象User ,所以它需要一个伴随解析器类。
1
2
3
4
5
6public class SigninResolver implements GraphQLResolver<SigninPayload> {
public User user(SigninPayload payload) {
return payload.getUser();
}
} - 添加新的顶级解析器 Mutation。
1
2
3
4
5
6
7public SigninPayload signinUser(AuthData auth) throws IllegalAccessException {
User user = userRepository.findByEmail(auth.getEmail());
if (user.getPassword().equals(auth.getPassword())) {
return new SigninPayload(user.getId(), user);
}
throw new GraphQLException("Invalid credentials");
} - 最后,更新架构构建逻辑GraphQLEndpoint 以包含新的解析器:
1
2
3
4
5
6
7
8return SchemaParser.newParser()
.file("schema.graphqls")
.resolvers(
new Query(linkRepository),
new Mutation(linkRepository, userRepository),
new SigninResolver())
.build()
.makeExecutableSchema(); - 重新启动Jetty并在GraphiQL 中测试:
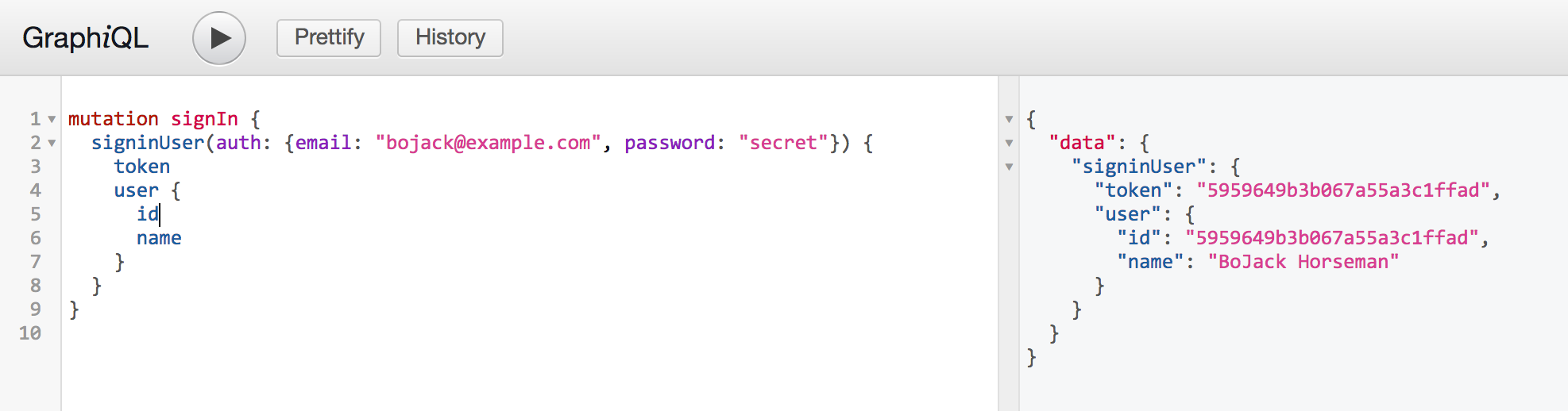
此示例中的标记只是用户标识。实际上,它应该是JWT或类似的。
验证
现在您已经有了对用户进行签名的方法,现在是时候处理对未来请求的身份验证了。执行此操作的常见方法是期望客户端(通常是浏览器)在标头中的每个后续请求成功登录后返回收到的令牌Authorization 。
- 配置GraphiQL 进行身份验证
作为服务器开发人员,这对您来说意味着您需要检查每个需要身份验证和/或授权的请求的标头值Authorization 。
在GraphQL 中,获取此类数据的方式(不是来自查询或突变本身)是通过上下文对象实现的。这是一个传递给在操作执行期间触发的所有解析器的值。
在SimpleGraphQLServlet 您的类GraphQLEndpoint 已经延伸提供了这样一个对象,并且其存储在HTTP 请求和响应中的对象。虽然这已经可以使用,但最好将其扩展为更直接地支持您的用例。
- 创建一个名为AuthContextextend GraphQLContext的类:
1
2
3
4
5
6
7
8
9
10
11
12
13public class AuthContext extends GraphQLContext {
private final User user;
public AuthContext(User user, Optional<HttpServletRequest> request, Optional<HttpServletResponse> response) {
super(request, response);
this.user = user;
}
public User getUser() {
return user;
}
} - 覆盖createContext方法GraphQLEndpoint以创建此上下文对象而不是原始对象:此代码将检查Authorization 标头是否存在,如果存在,请修剪Bearer 前缀并使用余数作为id 来获取用户。然后,用户将存储在您创建的自定义上下文中。AuthContext 所有需要它的解析器都可以访问它。
1
2
3
4
5
6
7
8
9
10
protected GraphQLContext createContext(Optional<HttpServletRequest> request, Optional<HttpServletResponse> response) {
User user = request
.map(req -> req.getHeader("Authorization"))
.filter(id -> !id.isEmpty())
.map(id -> id.replace("Bearer ", ""))
.map(userRepository::findById)
.orElse(null);
return new AuthContext(user, request, response);
}
- 扩展链接模型
首先修改链接模型以跟踪创建它的用户
1
2
3
4
5
6type Link {
id: ID!
url: String!
description: String
postedBy: User
}Link类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34public class Link {
private final String id;
private final String url;
private final String description;
private final String userId;
public Link(String url, String description, String userId) {
this(null, url, description, userId);
}
public Link(String id, String url, String description, String userId) {
this.id = id;
this.url = url;
this.description = description;
this.userId = userId;
}
public String getId() {
return id;
}
public String getUrl() {
return url;
}
public String getDescription() {
return description;
}
public String getUserId() {
return userId;
}
}由于添加了非标量关系Link ,它现在需要一个LinkResolver 类
创建LinkResolver 以包含链接操作逻辑(Link只是保存数据)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class LinkResolver implements GraphQLResolver<Link> {
private final UserRepository userRepository;
public LinkResolver(UserRepository userRepository) {
this.userRepository = userRepository;
}
public User postedBy(Link link) {
if (link.getUserId() == null) {
return null;
}
return userRepository.findById(link.getUserId());
}
}注册新的解析器与SchemaParser
更新 GraphQLEndpoint#buildSchema 。1
2
3
4
5
6
7
8
9
10
11private static GraphQLSchema buildSchema() {
return SchemaParser.newParser()
.file("schema.graphqls")
.resolvers(
new Query(linkRepository),
new Mutation(linkRepository, userRepository),
new SigninResolver(),
new LinkResolver(userRepository))
.build()
.makeExecutableSchema();
}需要更新用于加载和保存链接的逻辑以处理新字段
加载并保存userId 。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30public class LinkRepository {
private final MongoCollection<Document> links;
public LinkRepository(MongoCollection<Document> links) {
this.links = links;
}
public List<Link> getAllLinks() {
List<Link> allLinks = new ArrayList<>();
for (Document doc : links.find()) {
Link link = new Link(
doc.get("_id").toString(),
doc.getString("url"),
doc.getString("description"),
doc.getString("postedBy")
);
allLinks.add(link);
}
return allLinks;
}
public void saveLink(Link link) {
Document doc = new Document();
doc.append("url", link.getUrl());
doc.append("description", link.getDescription());
doc.append("postedBy", link.getUserId());
links.insertOne(doc);
}
}最后,将当前登录的用户视为创建者
更改要插入的createLink 解析程序方法userId 。1
2
3
4
5
6
7//The way to inject the context is via DataFetchingEnvironment
public Link createLink(String url, String description, DataFetchingEnvironment env) {
AuthContext context = env.getContext();
Link newLink = new Link(url, description, context.getUser().getId());
linkRepository.saveLink(newLink);
return newLink;
}测试

验证测试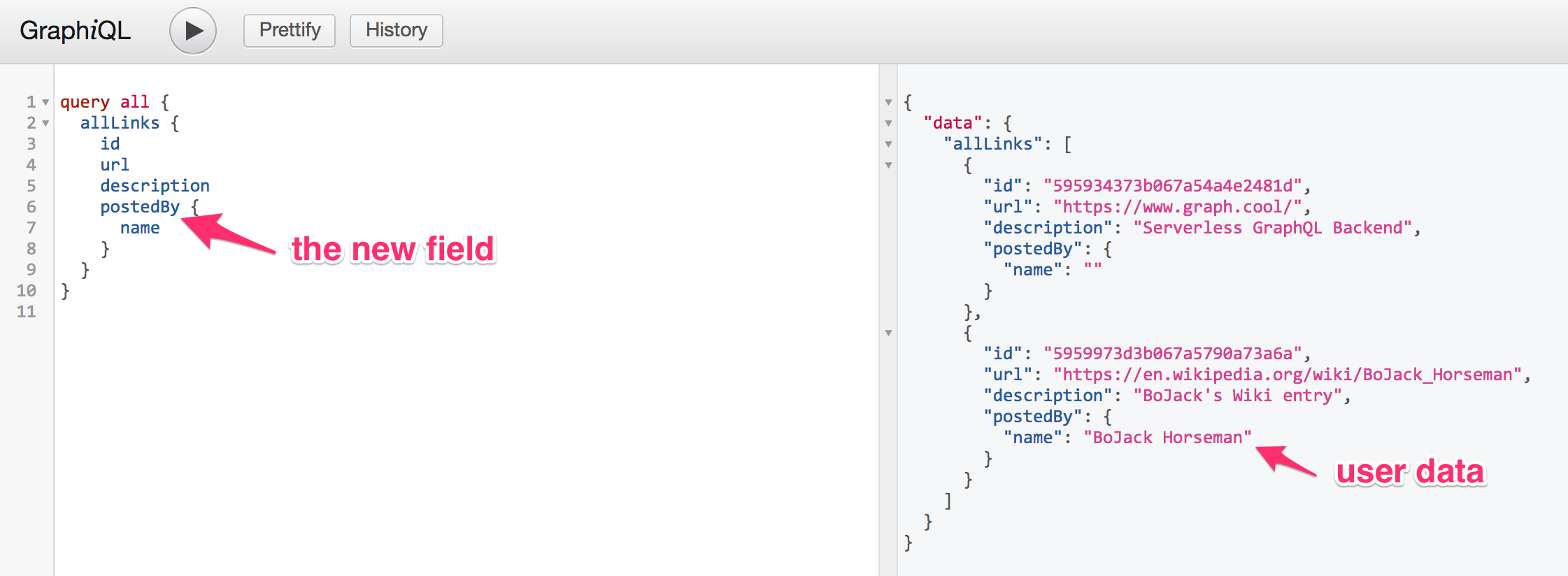
更多突变
投票链接
完成身份验证后,是时候将新功能引入系统 - 投票!用户应该能够投票选择他们喜欢的链接,以便稍后可以通过流行度来排序链接。
描述新的突变和相关类型
1
2
3
4
5
6
7
8
9
10
11
12
13type Mutation {
#the others stay the same
createVote(linkId: ID, userId: ID): Vote
}
type Vote {
id: ID!
createdAt: DateTime!
user: User!
link: Link!
}
scalar DateTime创建类似的数据和解析器类
Vote 类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33public class Vote {
private final String id;
private final ZonedDateTime createdAt;
private final String userId;
private final String linkId;
public Vote(ZonedDateTime createdAt, String userId, String linkId) {
this(null, createdAt, userId, linkId);
}
public Vote(String id, ZonedDateTime createdAt, String userId, String linkId) {
this.id = id;
this.createdAt = createdAt;
this.userId = userId;
this.linkId = linkId;
}
public String getId() {
return id;
}
public ZonedDateTime getCreatedAt() {
return createdAt;
}
public String getUserId() {
return userId;
}
public String getLinkId() {
return linkId;
}
}VoteResolver 类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class VoteResolver implements GraphQLResolver<Vote> {
private final LinkRepository linkRepository;
private final UserRepository userRepository;
public VoteResolver(LinkRepository linkRepository, UserRepository userRepository) {
this.linkRepository = linkRepository;
this.userRepository = userRepository;
}
public User user(Vote vote) {
return userRepository.findById(vote.getUserId());
}
public Link link(Vote vote) {
return linkRepository.findById(vote.getLinkId());
}
}持久性类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46public class VoteRepository {
private final MongoCollection<Document> votes;
public VoteRepository(MongoCollection<Document> votes) {
this.votes = votes;
}
public List<Vote> findByUserId(String userId) {
List<Vote> list = new ArrayList<>();
for (Document doc : votes.find(eq("userId", userId))) {
list.add(vote(doc));
}
return list;
}
public List<Vote> findByLinkId(String linkId) {
List<Vote> list = new ArrayList<>();
for (Document doc : votes.find(eq("linkId", linkId))) {
list.add(vote(doc));
}
return list;
}
public Vote saveVote(Vote vote) {
Document doc = new Document();
doc.append("userId", vote.getUserId());
doc.append("linkId", vote.getLinkId());
doc.append("createdAt", Scalars.dateTime.getCoercing().serialize(vote.getCreatedAt()));
votes.insertOne(doc);
return new Vote(
doc.get("_id").toString(),
vote.getCreatedAt(),
vote.getUserId(),
vote.getLinkId());
}
private Vote vote(Document doc) {
return new Vote(
doc.get("_id").toString(),
ZonedDateTime.parse(doc.getString("createdAt")),
doc.getString("userId"),
doc.getString("linkId")
);
}
}需要创建一个新的标量类型来表示DateTime
需要一个实例GraphQLScalarType 。有关如何创建这些内容的参考,您可以查看内置类型。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public class Scalars {
public static GraphQLScalarType dateTime = new GraphQLScalarType("DateTime", "DataTime scalar", new Coercing() {
public String serialize(Object input) {
//serialize the ZonedDateTime into string on the way out
return ((ZonedDateTime)input).format(DateTimeFormatter.ISO_OFFSET_DATE_TIME);
}
public Object parseValue(Object input) {
return serialize(input);
}
public ZonedDateTime parseLiteral(Object input) {
//parse the string values coming in
if (input instanceof StringValue) {
return ZonedDateTime.parse(((StringValue) input).getValue());
} else {
return null;
}
}
});
}GraphQLEndpoint 需要知道新的存储库,解析器和标量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20private static final VoteRepository voteRepository;
static {
// the rest stays
voteRepository = new VoteRepository(mongo.getCollection("votes"));
}
private static GraphQLSchema buildSchema() {
return SchemaParser.newParser()
.file("schema.graphqls")
.resolvers(
new Query(linkRepository),
new Mutation(linkRepository, userRepository, voteRepository),
new SigninResolver(),
new LinkResolver(userRepository),
new VoteResolver(linkRepository, userRepository)) //new resolver
.scalars(Scalars.dateTime) //register the new scalar
.build()
.makeExecutableSchema();
}创建新的突变解析器
1
2
3
4public Vote createVote(String linkId, String userId) {
ZonedDateTime now = Instant.now().atZone(ZoneOffset.UTC);
return voteRepository.saveVote(new Vote(now, userId, linkId));
}测试
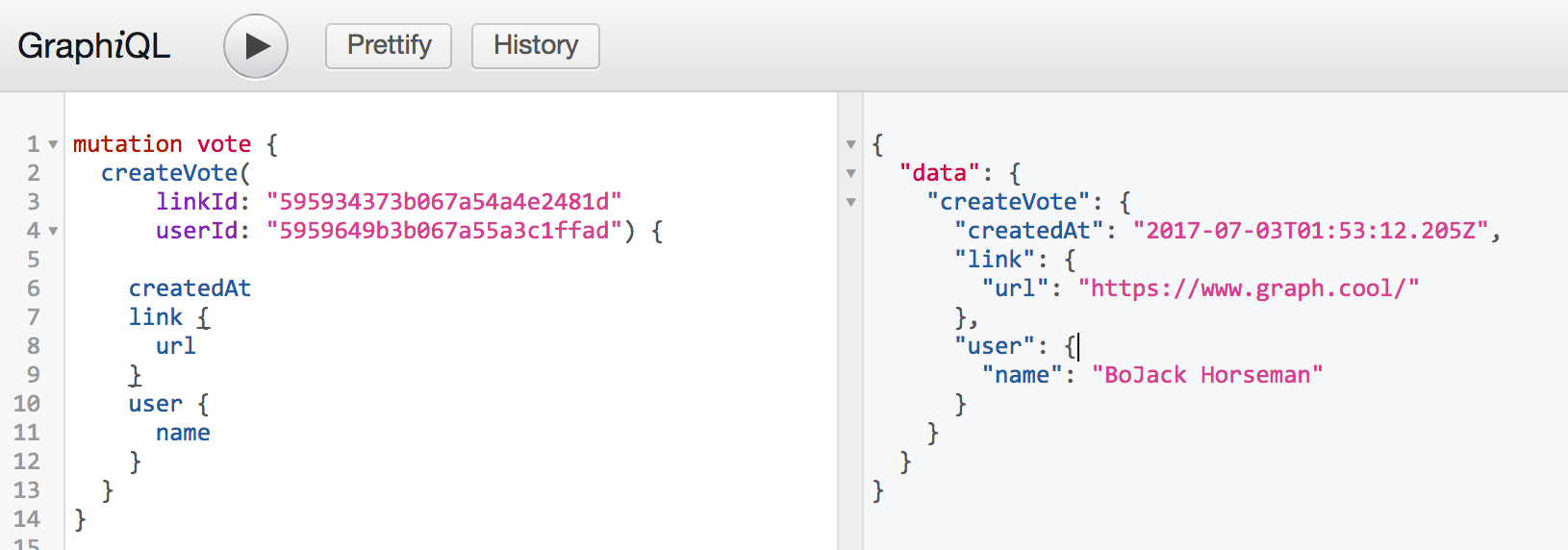
异常处理
前提
你可能已经看到出现GraphiQL 时出现错误,因此您可能对服务器出现问题时会发生什么事情有一些直觉。在最简单的情况下,如果您错误地输入查询,您将在响应的专用字段中看到错误errors 。
响应
GraphQL 强调了一致性和可预测性,并且在这种语气中,来自GraphQL 服务器的响应总是具有可预测的结构,包括3个字段:
- 存储操作结果的data 字段。
- 该errors 字段,保留在执行操作期间累积的所有错误。
- 具有任意内容的可选extensions 字段,通常是关于响应的元数据。
处理方式
任何GraphQL 服务器都会自动处理语法和验证错误并适当地通知客户端,但解析器函数中遇到的异常通常需要特定于应用程序的处理。使用当前堆栈,可以在几个不同的级别上自定义错误处理。
在最高级别,graphql-java-servlet 公开一种方法(称为isClientError ),该方法决定是将消息的消息逐字地发送到客户端,还是由通用服务器错误消息将其隐藏。默认情况下,只会按原样发送语法和验证错误。这是一个合理的默认值,因为异常消息和堆栈跟踪可能会泄露出大量最不可见的公共视图信息。然而,无信息的错误消息(甚至是太多的消息)会对API 的可用性产生严重的负面影响。该方法决定是将消息的消息逐字地发送到客户端,还是由通用消息将其隐藏。
示例
通过首先询问链接中不存在的字段来检查GraphiQL 中的默认行为address :链接中不存在的字段来检查GraphiQL 中的默认行为。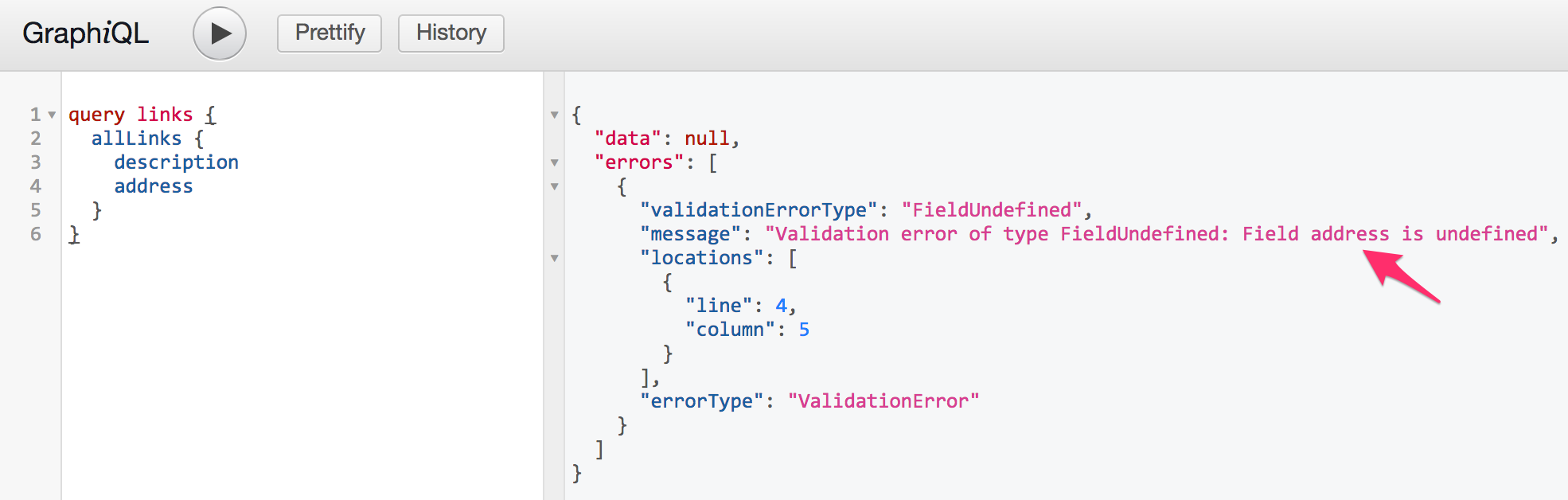
然后检查特定于应用程序的错误的行为,例如,提供错误的密码signinUser: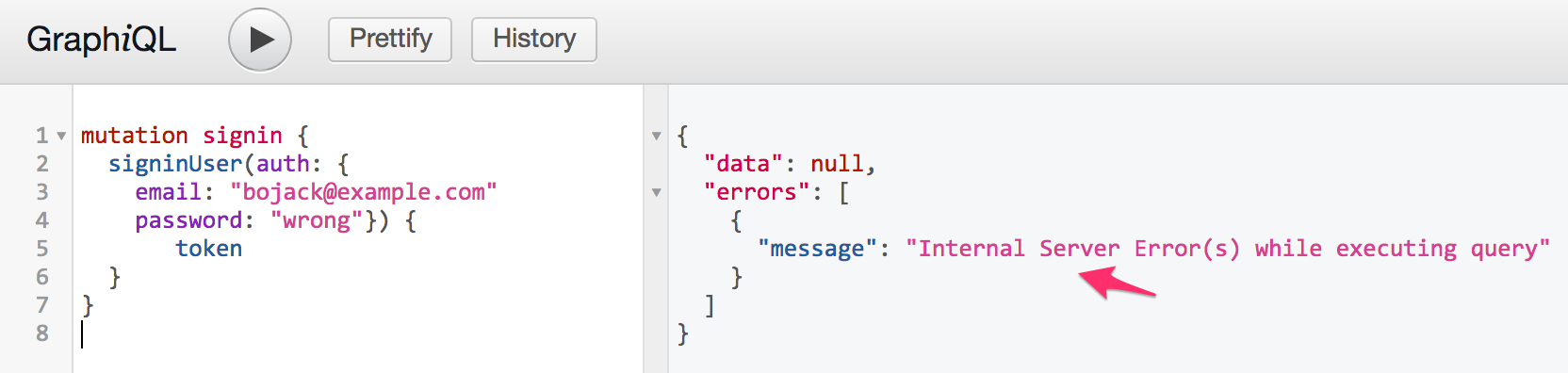
要允许用户正确清理外发邮件,同时保持其相关性和特定性,请graphql-java-servlet 公开另一个扩展点:GraphQLServlet#filterGraphQLErrors 方法。通过重写此方法,可以在收集的错误发送到客户端之前对其进行清理、过滤、包装或以其他方式转换。
一个很好的用例是使用对客户端有用的额外信息来丰富消息。
解决
- 转发数据获取异常消息,同时仍然隐藏相应的堆栈跟踪,您应该首先创建一个简单的包装类:这个包装器做的不多 - 它只是指示Jackson(JSON 的序列化库)在序列化期间忽略链接的异常。这样,堆栈跟踪将无法到达客户端。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import com.fasterxml.jackson.annotation.JsonIgnore;
import graphql.ExceptionWhileDataFetching;
public class SanitizedError extends ExceptionWhileDataFetching {
public SanitizedError(ExceptionWhileDataFetching inner) {
super(inner.getException());
}
public Throwable getException() {
return super.getException();
}
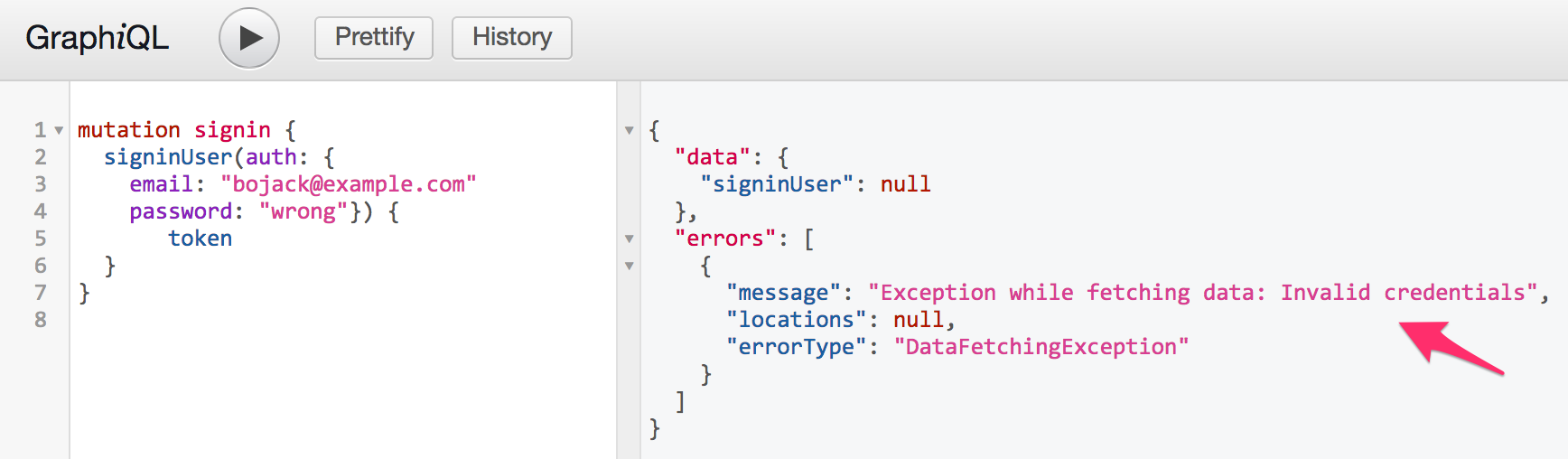
} - 然后,通过重写包的所有数据取例外filterGraphQLErrors 的GraphQLEndpoint :这样,除了语法和验证错误之外,数据获取错误将具有发送到客户端的精确消息,但没有粗略的细节。所有其他错误类型仍将隐藏在通用消息后面。
1
2
3
4
5
6
7
protected List<GraphQLError> filterGraphQLErrors(List<GraphQLError> errors) {
return errors.stream()
.filter(e -> e instanceof ExceptionWhileDataFetching || super.isClientError(e))
.map(e -> e instanceof ExceptionWhileDataFetching ? new SanitizedError((ExceptionWhileDataFetching) e) : e)
.collect(Collectors.toList());
}
测试
对于更低级别的控制,可以自定义执行策略(执行操作的方式,由ExecutionStrategy 接口建模),以及将Java异常转换为GraphQL 错误的覆盖ExecutionStrategy#handleDataFetchingException 方法。
要使用自定义执行策略,请将构造函数更改GraphQLEndpoint 为:
1 | public GraphQLEndpoint() { |
订阅
正如你在入门教程中所了解到的,GraphQL 规范定义了一种实时推送式更新机制,称为订阅在响应的专用字段中看到错误。虽然graphql-java 它解析了订阅请求,但是在那里之后就没有再更新了。
过滤
正如您在前面的章节中所看到的,查询和突变可以通过参数获取输入。由于参数没有附加固有的语义,并且无论你将它们定义为什么意思,你都可以通过简单地指定用于此目的的参数来轻松实现过滤等常见功能。
将应用此想法将过滤添加到已定义的allLinks查询中
在其架构定义中添加一个新参数
1
2
3
4
5
6
7
8type Query {
allLinks(filter: LinkFilter): [Link]
}
input LinkFilter {
description_contains: String
url_contains: String
}这种方法只是一个例子。您也可以使用任何其他格式实现过滤。
创建相应的数据类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import com.fasterxml.jackson.annotation.JsonProperty;
public class LinkFilter {
private String descriptionContains;
private String urlContains;
//the name must match the schema
public String getDescriptionContains() {
return descriptionContains;
}
public void setDescriptionContains(String descriptionContains) {
this.descriptionContains = descriptionContains;
}
public String getUrlContains() {
return urlContains;
}
public void setUrlContains(String urlContains) {
this.urlContains = urlContains;
}
}逻辑需要允许过滤
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public List<Link> getAllLinks(LinkFilter filter) {
Optional<Bson> mongoFilter = Optional.ofNullable(filter).map(this::buildFilter);
List<Link> allLinks = new ArrayList<>();
for (Document doc : mongoFilter.map(links::find).orElseGet(links::find)) {
allLinks.add(link(doc));
}
return allLinks;
}
//builds a Bson from a LinkFilter
private Bson buildFilter(LinkFilter filter) {
String descriptionPattern = filter.getDescriptionContains();
String urlPattern = filter.getUrlContains();
Bson descriptionCondition = null;
Bson urlCondition = null;
if (descriptionPattern != null && !descriptionPattern.isEmpty()) {
descriptionCondition = regex("description", ".*" + descriptionPattern + ".*", "i");
}
if (urlPattern != null && !urlPattern.isEmpty()) {
urlCondition = regex("url", ".*" + urlPattern + ".*", "i");
}
if (descriptionCondition != null && urlCondition != null) {
return and(descriptionCondition, urlCondition);
}
return descriptionCondition != null ? descriptionCondition : urlCondition;
}更新Query以将新参数添加到顶级方法
1
2
3public List<Link> allLinks(LinkFilter filter) {
return linkRepository.getAllLinks(filter);
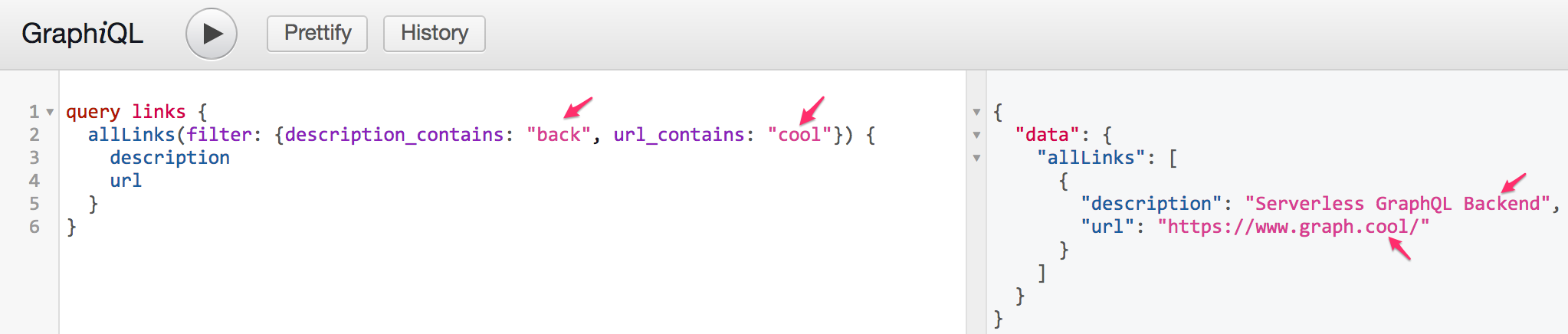
}测试
分页和排序
随着链接数量的增加,列出所有链接变得不太可行。按理说你应该引入只能请求多个链接并通过结果分页的功能。
在本教程中,您将实现一个名为limit-offset 分页的简单分页方法(类似于您可能从SQL 中了解到的)。这种方法不适用于前端的Relay ,因为Relay 需要通过连接的概念进行基于光标的分页。您可以在GraphQL 文档中阅读有关分页的更多信息。
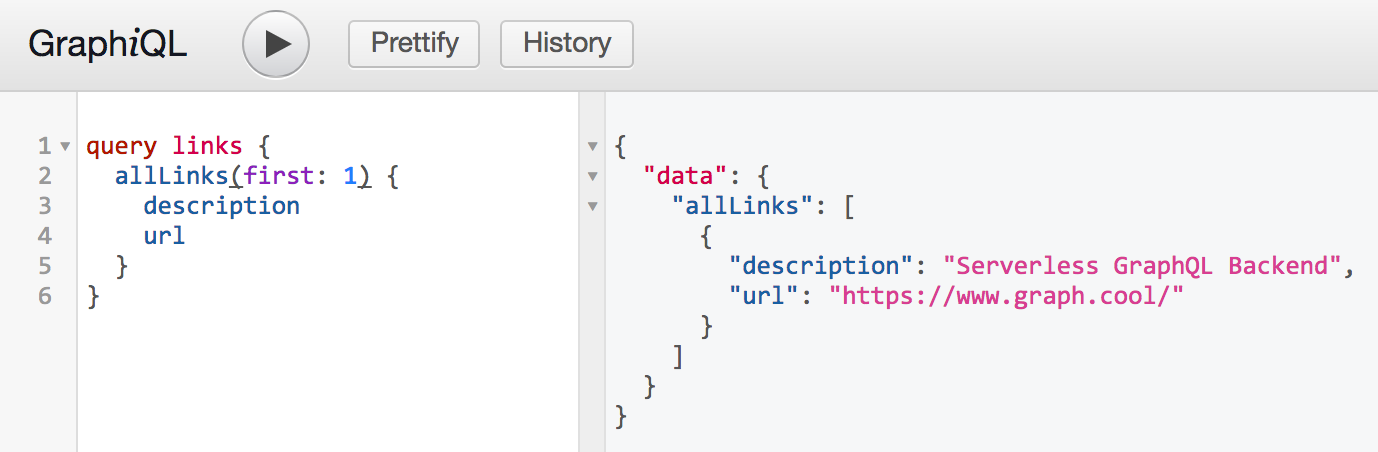
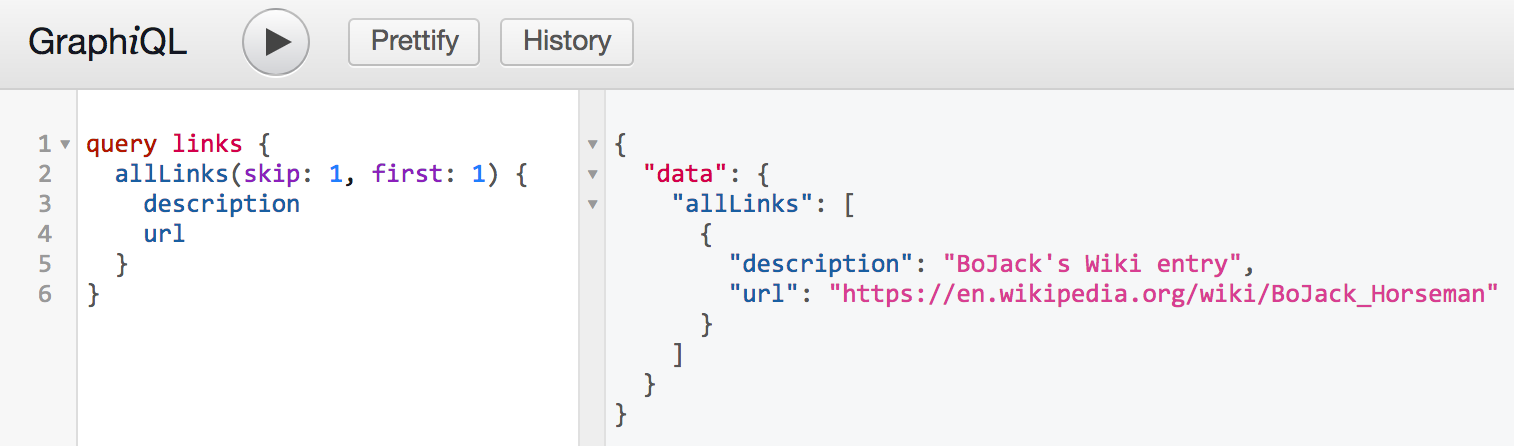
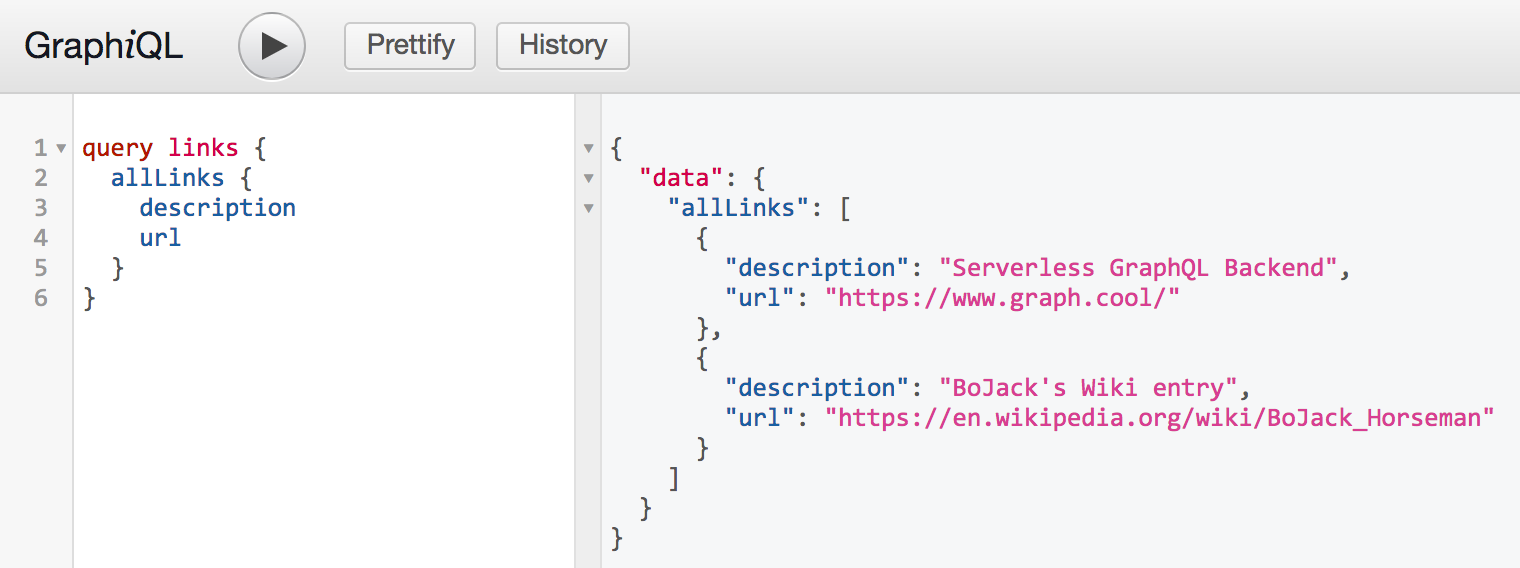
添加两个新参数以使客户端能够指定它们所需的链接数以及从哪个索引开始
1
2
3type Query {
allLinks(filter: LinkFilter, skip: Int = 0, first: Int = 0): [Link]
}更新存储库方法(LinkRepository#getAllLinks)以获取并使用这些新参数
1
2
3
4
5
6
7
8
9
10public List<Link> getAllLinks(LinkFilter filter, int skip, int first) {
Optional<Bson> mongoFilter = Optional.ofNullable(filter).map(this::buildFilter);
List<Link> allLinks = new ArrayList<>();
FindIterable<Document> documents = mongoFilter.map(links::find).orElseGet(links::find);
for (Document doc : documents.skip(skip).limit(first)) {
allLinks.add(link(doc));
}
return allLinks;
}更新类中的顶级方法Query
1
2
3public List<Link> allLinks(LinkFilter filter, Number skip, Number first) {
return linkRepository.getAllLinks(filter, skip.intValue(), first.intValue());
}两者的参数类型必须是Number 因为graphql-java-tools 有时Integer 会根据上下文尝试填充,有时会填充BigInteger 。
测试
模式开发的替代方法
到目前为止,开发的方式称为模式优先,因为始终首先定义模式。这种风格具有重要的好处,在本教程的开头讨论过,它适用于没有遗留代码的新项目。尽管如此,可能已经注意到,在强类和静态类型语言(如Java )中,它会导致大量重复。例如,重新审视开发类型的方式Link 。
在架构中定义:
1 | type Link { |
创建了对应的POJO 类:
1 | public class Link { |
这两个块都包含完全相同的信息。更糟糕的是,改变一个需要立即改变另一个。这使得重构变得风险和繁琐。另一方面,如果尝试将GraphQL API 引入现有项目,则编写模式实际上意味着重新描述整个现有模型。这既昂贵又容易出错,并且仍然存在重复问题。
代码优先风格
架构优先样式的常见替代方法(称为代码优先)是从现有模型生成架构。这使架构和模型保持同步,从而简化了重构。它也适用于在现有代码库之上引入GraphQL 的项目。
这种方法的缺点是,在编写某些服务器代码之前,架构不存在,从而在客户端和服务器端工作之间引入依赖关系。一种解决方法是使用服务器上的存根来快速生成模式,然后与客户端并行开发真实的服务器代码。
Java/GraphQL 生态系统催生了一些促进这种开发风格的库。你可以在这里找到它们。
设置graphql-sqpr
添加依赖
1
2
3
4
5<dependency>
<groupId>io.leangen.graphql</groupId>
<artifactId>spqr</artifactId>
<version>0.9.1</version>
</dependency>通过配置如下启用javac 选项maven-compiler-plugin
1
2
3
4
5
6
7
8
9
10<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<compilerArgs>
<arg>-parameters</arg>
</compilerArgs>
</configuration>
</plugin>运行,以使新选项生效
1
mvn clean package
使用graphql-spqr 生成模式
- 修改通过GraphQL 公开的方法有关此代码的一些注意事项:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class Query { //1
private final LinkRepository linkRepository;
public Query(LinkRepository linkRepository) {
this.linkRepository = linkRepository;
}
//2
public List<Link> allLinks(LinkFilter filter,
Number skip, //3
Number first) {
return linkRepository.getAllLinks(filter, skip.intValue(), first.intValue());
}
}
- GraphQLRootResolver 不再需要实现(也不需要实现graphql-java-tools)。事实上,graphql-spqr 为了确保代码不需要特殊的类,接口或任何修改以便通过GraphQL 公开。
- 注释完全是可选的,但默认配置将期望它们位于顶层。
- 默认情况下,方法参数的名称将在架构中使用。使用@GraphQLArgument 是一种更改名称和设置默认值的方法。所有这些都是可行的,没有注释。
- LinkResolver特点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class LinkResolver { //1
private final UserRepository userRepository;
LinkResolver(UserRepository userRepository) {
this.userRepository = userRepository;
}
public User postedBy( Link link) { //2
if (link.getUserId() == null) {
return null;
}
return userRepository.findById(link.getUserId());
}
}
- 不再是implements GraphQLResolver 。
- @GraphQLContext 用于将外部方法连接到类型中。此映射在语义上与Link 类包含方法时相同public User postedBy() {…}。以这种方式,可以使逻辑与数据分离,但仍然产生深度嵌套的结构。
- 暴露createLink 突变注意事项:
1
2
3
4
5
6//1
public Link createLink(String url, String description, AuthContext context) { //2
Link newLink = new Link(url, description, context.getUser().getId());
linkRepository.saveLink(newLink);
return newLink;
}
- 通过暴露突变@GraphQLMutation 。
- AuthContext 直接注入@GraphQLRootContext 。不再需要DataFetchingEnvironment ,这很好地消除了对逻辑层中特定代码的依赖性graphql-java 。
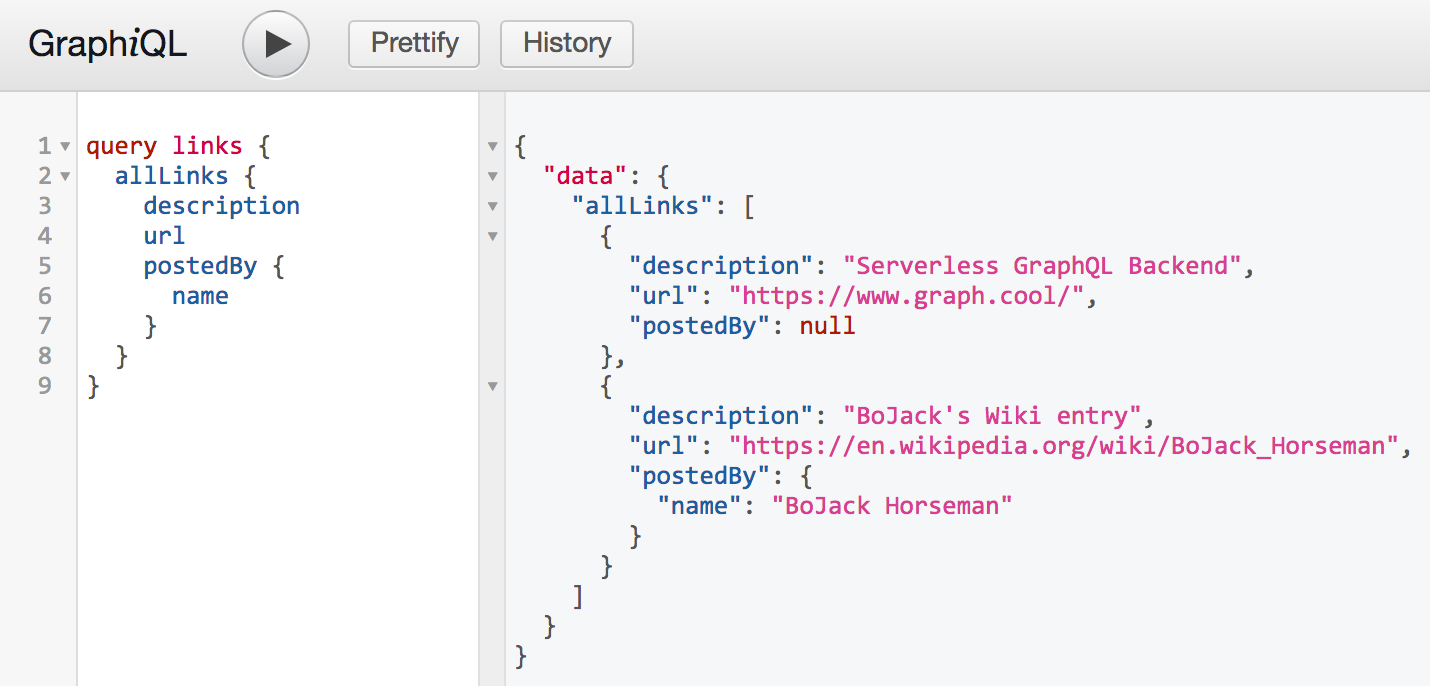
从类生成模式,请更新GraphQLEndoint#buildSchema
1
2
3
4
5
6
7
8
9private static GraphQLSchema buildSchema() {
Query query = new Query(linkRepository); //create or inject the service beans
LinkResolver linkResolver = new LinkResolver(userRepository);
Mutation mutation = new Mutation(linkRepository, userRepository, voteRepository);
return new GraphQLSchemaGenerator()
.withOperationsFromSingletons(query, linkResolver, mutation) //register the beans
.generate(); //done :)
}测试
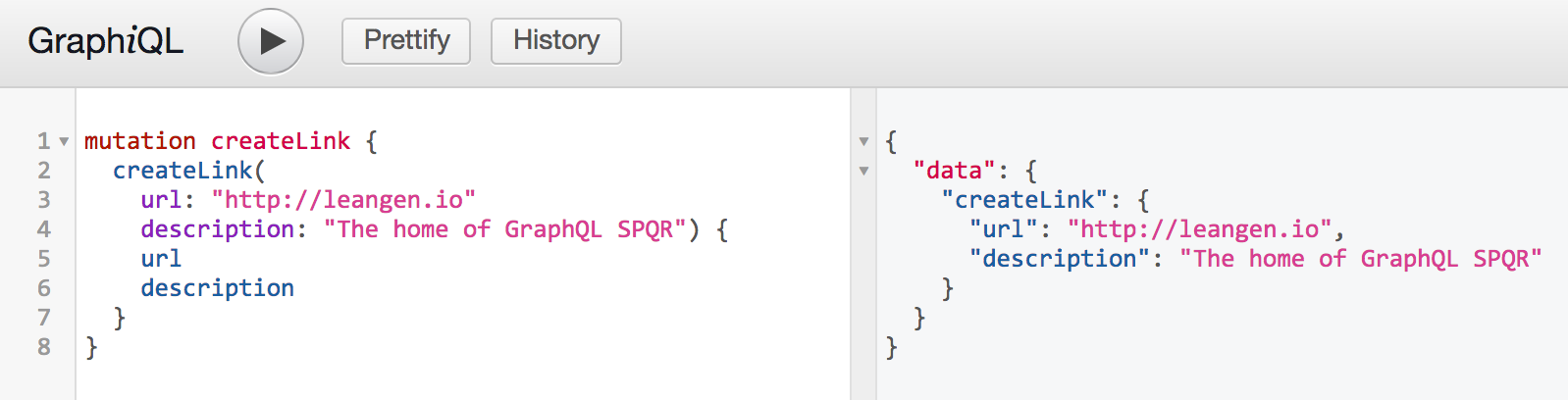
注意的重点:
- 从未明确定义架构(这意味着不必在代码更改时更新它)。
- 不必将操纵Links 的逻辑分为顶级查询(allLinks 内部Query ),嵌入式查询(postedBy 内部LinkResolver )和突变(createLink 内部Mutation )。在链接上运行的所有查询和突变都可以放在一个类中(例如LinkService ),但将它们分开也不是一个障碍。这意味着你的遗留代码和最佳实践可以保持不变。
摘要
GraphQL 提供了一种简洁明了的方式:类型的方式
- 描述和操纵数据
- 准确地获取并且仅获取所需的数据
- 收到可预测的结果。
在整个教程中,已经学会了如何在自己的项目中利用这些优势,但仍有许多领域需要您自己探索。如何处理动态数据结构?如何防范恶意查询?缓存等难以理解的主题。
请记住,GraphQL 是一种新兴技术,特别是在Java 的生态系统中。版本的变化、想法和最佳实践的发展和转变,因此请务必密切关注本教程,因为它可能会偶尔更新,甚至可能会被完全重写,以保持相关性。