简介
Dubbo是阿里巴巴在2011年开源的的分布式服务框架,是SOA服务化治理方案的核心框架。
Dubbo的整体架构如下: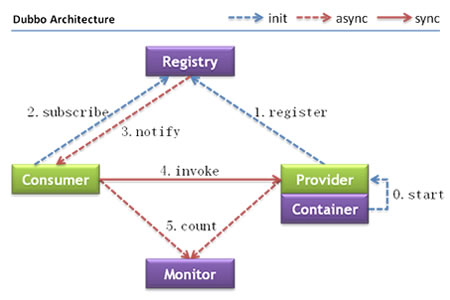
Dubbo主要提供三个方面的功能:
- 远程接口调用。
- 负载均衡和容错。
- 自动服务注册与发现。
首先准备环境,需要安装Zookeeper。详细的Zookeeper信息可以看我的另一篇博客。
第一个Hello World 程序
Dubbo 采用全Spring 配置方式。透明化接入应用,对应用没有任何API侵入,只需用Spring 加载Dubbo 的配置即可。
Dubbo 基于Spring 的Schema 扩展进行加载。
创建工程并添加依赖库
使用IDEA 创建一个Maven 项目,然后在该工程中创建三个项目(Module):远程接口项目(API)、服务端项目(Server)、客户端项目(Client),其中服务端项目和客户端项目都依赖远程接口项目。
添加依赖:
1 | <!--Dubbo--> |
定义远程服务接口
新建IHelloService 接口:
1 | package cn.vgbhfive.vid.vid_rpc.api; |
编写服务器程序
实现服务端的服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15package cn.vgbhfive.vid.vid_rpc.server.impl;
/**
* @time: 2018/11/7
* @author: Vgbh
*/
public class RPCService implements IHelloService {
private static final Logger log = LoggerFactory.getLogger(RPCService.class);
public String sayHello(String name) {
return name
}
}暴露服务
在Server 项目中使用Spring 配置声明暴露服务,在resource 目录下创建provider.xml 文件。配置如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://code.alibabatech.com/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://code.alibabatech.com/schema/dubbo
http://code.alibabatech.com/schema/dubbo/dubbo.xsd">
<!--提供者的应用名-->
<dubbo:application name="dubbo-server" />
<!--使用Zookeeper注册中心的地址-->
<dubbo:registry address="zookeeper://127.0.0.1:2181" />
<!--使用Dubbo协议在20880端口暴露服务-->
<dubbo:protocol name="dubbo" port="20880" />
<!--声明需要暴露的服务接口-->
<dubbo:service interface="cn.vgbhfive.vid.vid_rpc.api.IHelloService" ref="IdService" />
<!--和本地Bean一样实现服务-->
<bean id="IdService" class="cn.vgbhfive.vid.vid_rpc.server.impl.RPCService" />
</beans>加载配置
创建一个Server 启动类,通过该类来加载Spring 配置并提供远程服务。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19package cn.vgbhfive.vid.vid_rpc.server;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.stereotype.Component;
import java.io.IOException;
/**
* @time: 2018/11/7
* @author: Vgbh
*/
public class Server {
public static void main(String[] args) throws IOException {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext(new String[]{"provider.xml"});
context.start();
System.in.read();
}
}
编写客户端程序
- 在Client 项目中通过Spring 配置引用远程服务,在resource 目录下创建一个consumer.xml 文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://code.alibabatech.com/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://code.alibabatech.com/schema/dubbo
http://code.alibabatech.com/schema/dubbo/dubbo.xsd">
<!--消费方的应用名,用于计算依赖关系,不是匹配条件,不要与提供方一样-->
<dubbo:application name="dubbo-client" />
<!--使用Zookeeper注册中心的地址-->
<dubbo:registry address="zookeeper://127.0.0.1:2181" />
<!--生成远程服务代理,可以和本地bean一样使用IdService-->
<dubbo:reference id="IdService" interface="cn.vgbhfive.vid.vid_rpc.api.IHelloService" />
</beans> - 加载配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22package cn.vgbhfive.vid.vid_rpc.server;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.stereotype.Component;
import java.io.IOException;
/**
* @time: 2018/11/7
* @author: Vgbh
*/
public class Client {
public static void main(String[] args) throws IOException {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext(new String[]{"consumer.xml"});
context.start();
IHelloService service = (IHelloService)context.getBean("IdService");
String str = service.sayHello("Hello World!");
System.out.println(str);
}
}
运行结果
1 | Hello World! |
SPI 机制
为什么首先介绍SPI 机制,估计大部分看过Dubbo 源码的人都很熟悉Dubbo 的SPI 机制,既然用了这么多,那就说明他很重要,所以首先来说它。
Dubbo SPI
Dubbo 并未使用 Java SPI,而是重新实现了一套功能更强的 SPI 机制。
添加配置类
1
2optimusPrime = org.apache.spi.OptimusPrime
bumblebee = org.apache.spi.Bumblebee与 Java SPI 实现类配置不同,Dubbo SPI 是通过键值对的方式进行配置,这样我们可以按需加载指定的实现类。
测试类
1
2
3
4
5
6
7
8
9
10
11
12public class DubboSPITest {
@Test
public void sayHello() throws Exception {
ExtensionLoader<Robot> extensionLoader =
ExtensionLoader.getExtensionLoader(Robot.class);
Robot optimusPrime = extensionLoader.getExtension("optimusPrime");
optimusPrime.sayHello();
Robot bumblebee = extensionLoader.getExtension("bumblebee");
bumblebee.sayHello();
}
}结果展示
1
2
3Java SPI
Hello, I am Optimus Prime.
Hello, I am Bumblebee.Dubbo SPI 除了支持按需加载接口实现类,还增加了 IOC 和 AOP 等特性。
配置方式
Dubbo的配置主要分为三大类:服务发现、服务治理和性能调优。这三大类配置不是独立存在的,而是贯穿所有配置项中的。
这三大类的主要作用如下:
- 服务发现类:表示该配置项用于服务的注册与发现,目的是让消费者找到提供者。
- 服务治理类:表示该配置项用于治理服务间的关系,或为开发测试提供便利条件。
- 性能调优类:表示该配置项用于调优性能,不同的选项回对性能产生不同的影响。
Dubbo支持的四种配置方式
XML 配置
我们可以使用XML 对Dubbo 进行配置,因为Dubbo 是使用Spring 的Schema 进行扩展标签和解析配置的,所以我们可以像使用Spring 的XML 配置方式一样进行配置。
比如之前Hello World程序中暴露服务的配置:
1 |
|
在以上配置中使用了Dubbo扩展的dubbo:application、dubbo:registry、dubbo:service等标签。
Dubbo schema 配置参考
Dubbo的配置标签及他们之间的关系: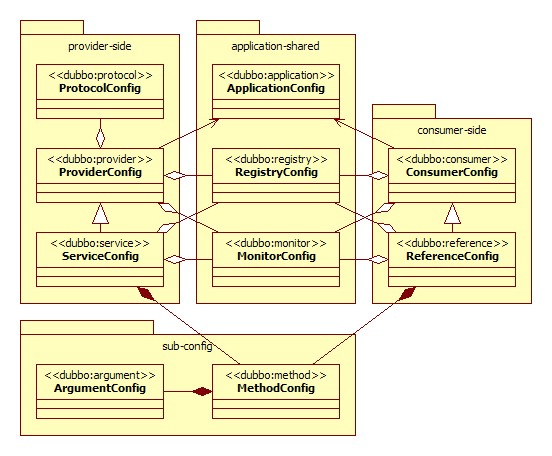
这些标签的用途和解释:
| 标签 | 用途 | 解释 |
|---|---|---|
| <dubbo:service/> | 服务配置 | 用于暴露一个服务,定义服务的元信息,一个服务可以被多个协议暴露,一个服务也可以注册多个到注册中心。 |
| <dubbo:reference/> | 引用配置 | 用于创建一个远程服务代理,一个引用可以指向多个注册中心。 |
| <dubbo:protocol/> | 协议配置 | 用于配置提供服务的协议信息,协议由提供者指定,消费者被动接收。 |
| <dubbo:application/> | 引用配置 | 用于配置当前的应用信息,不管是消费者还是提供者。 |
| <dubbo:module/> | 模块配置 | 用于配置当前的模块信息。 |
| <dubbo:registry/> | 注册中心配置 | 用于配置连接到注册中心相关的信息。 |
| <dubbo:monitor/> | 监控中心配置 | 用于配置连接到监控中心相关的信息。 |
| <dubbo:provider/> | 服务者配置 | 当ProtocolConfig 和ServiceConfig 的某属性没有配置时,采用此默认值。 |
| <dubbo:consumer/> | 提供者配置 | 当ReferenceConfig 的某属性值没有配置时,采用此默认值。 |
| <dubbo:method/> | 方法配置 | 用于ServiceConfig 和RefernceConfig 指定方法级的配置信息。 |
| <dubbo:argument/> | 参数配置 | 用于指定方法参数的配置信息。 |
配置的覆盖优先级: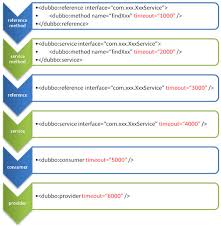
各优先级关系简单可总结为:
- 方法级优先,接口级次之,全局配置再次之。
- 如果级别一样,则消费者优先,提供者次之。
属性配置
我们还可以对Dubbo 使用properties 文件进行配置。
配置示例:
1 | dubbo.application.name = dubbo-server |
属性的配置规则遵循以下约定:
- 将XML配置的标签名加属性名,用点分隔,将多个属性拆分成多行。
- 如果XML有多行同名标签,则可用id 号区分,如果没有id 号,则将对所有同名标签生效。
各配置方式的覆盖优先级策略:
- JVM 启动-D 参数优先,这样可以使用户在部署和启动时进行参数重写。比如改写端口。
- XML 次之,如果在XML中有配置,则dubbo.properties 中的配置项则无效。
- Properties 最后,相当于默认值,只有XML没有被配置时,dubbo.prperties 的相应配置才会生效,通常用于共享公共配置。
API 配置
API 属性与XML 配置项是一一对应的。如下:
1 | ApplicationConfig.setName("dubbo-server") => |
注解配置
通过注解方式对Dubbo 进行配置,这样可以节省大量的XML 配置和属性配置。
对服务提供者配置如下:
1 |
|
使用@Service 注解暴露服务。
指定Dubbo 的扫描路径。
对服务消费者配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class DubboConfiguration {
public ApplicationConfig applicationConfig() {
ApplicationConfig applicationConfig = new ApplicationConfig();
applicationConfig.setName("dubbo-client");
return applicationConfig;
}
public ConsumerConfig consumerConfig() {
ConsumerConfig consumerConfig = new ConsumerConfig();
consumerConfig.setTimeout(3000);
return consumerConfig;
}
public RegistryConfig registryConfig() {
RegistryConfig registeryConfig = new RegistryConfig();
registryConfig.setAddress("zookeeper://127.0.0.1:2181");
registryConfig.setClient("curator");
return registryConfig;
}
}
使用@Reference 注解应用服务。
指定Dubbo 的扫描路径。
服务注册与发现
注册中心
注册中心
Dubbo 支持多注册中心,不仅支持多种形式的注册中心,而且支持同时向多个注册中心注册。
目前Dubbo 支持的注册中心有以下四种:
- Multicast 注册中心。
该注册中心不需要驱动任何中心节点,只要广播地址一样,就可以互相发现。组播受网络结构限制,因此只适合小规模应用或开发阶段使用。组播地址为224.0.0.0 ~ 239.255.255.255。 - ZooKeeper 注册中心。
ZooKeeper 是Apache Hadoop 的子项目,是一个树形的目录服务,它以Fast Paxos 算法为基础,为分布式服务提供一致性服务,还支持变更推送功能,推荐在生产环境下使用。 - Redis 注册中心。
基于Redis 实现的注册中心,使用Redis 的Key/Map 结构存储服务的URL 地址和过期时间,同时使用Redis 的Publish/Subscribe 事件通知数据变更。 - Simple 注册中心。
它本身就是一个普通的Dubbo 服务,可以减少第三方依赖,以整体通信方式一致。
Dubbo 使用ZooKeeper
我们在服务提供者(Provider) 和服务消费者(Consumer) 的配置文件中使用<dubbo:registry /> 标签指定ZooKeeper 的地址后,就可以使用ZooKeeper 注册中心了。
配置代码如下:
1 | <dubbo:registry address="zookeeper://127.0.0.1:2181" /> |
Dubbo 目前支持zkclient 和curator 这两种ZooKeeper 客户端实现,默认情况下是zkclient ,若需要修改则只需要指定client=”curator” ,并添加对应的JAR 包即可。
- 默认使用zkclient
1
<dubbo:registry address="zookeeper://127.0.0.1:2181" />
- 使用curator 还可以通过group 属性将同一ZooKeeper 分成多组注册中心,如下:
1
<dubbo:registry address="zookeeper://127.0.0.1:2181" client="curator" />
1
2<dubbo:registry id="shanghaiRegistry" protocol="zookeeper" address="127.0.0.1:2181" group="shanghai" />
<dubbo:registry id="hangzhouRegistry" protocol="zookeeper" address="127.0.0.1:2181" group="hangzhou" />
ZooKeeper 集群配置
集群模式的注册中心注册
1
2
3<dubbo:registry address="zookeeper://192.168.1.10:2181" backup="192.168.1.11:2181, 192.168.1.12:2181" />
<!-- 或者 -->
<dubbo:registry protocol="zookeeper" address="192.168.1.10:2181, 192.168.1.11:2181, 192.168.1.12:2181" />多个ZooKeeper 的注册中心注册
1
2
3
4
5<!-- 多注册中心配置 -->
<dubbo:registry id="hangzhouRegistry" address="127.0.0.1:2181" />
<dubbo:registry id="hangzhouRegistry" address="127.0.0.1:2181" default="false" />
<!-- 向多个注册中心注册 -->
<dubbo:service interface="com.alibaba.hello.api.HelloService" version="1.0.0" ref="HelloService" registry="hangzhouRegistry, shanghaiRegistry" />
Dubbo 在ZooKeeper 中建立目录结构

注册流程、支持的功能
流程说明:
- 在服务提供者启动时,向/dubbo/com.foo.BarService/providers 目录下写入自己的URL 地址。
- 在服务消费者启动时,订阅/dubbo/com.foo.BarService/providers 目录下的提供者的URL 地址,并向/dubbo/com.foo.BarService/consumers 目录下写入自己的URL 地址。
- 在监控中心启动时,订阅/dubbo/com.foo.BarService 目录下的所有提供者个消费者的URL 地址。
支持的功能:
- 在提供者出现断电等异常停机时,注册中心能自动删除提供者的信息。
- 在注册中心重启时,能自动恢复注册数据及订阅请求。
- 在会话过期时,能自动恢复注册数据及订阅请求。
- 在设置<dubbo:registry check=”false” />时,记录失败注册和订阅请求,后台定时重试。
- 可通过<dubbo:registry username=”admin” password=”1234” />设置ZooKeeper 的登陆账号和密码。
- 可通过<dubbo:registry group=”dubbo” />设置ZooKeeper 的根节点,在不设置时使用无根树。
- 支持* 号通配符<dubbo:reference group=”*” varsion=”*” />,可订阅服务的所有分组和所有版本的提供者。
服务暴露
在服务通过注册中心注册后,那么就需要使用<dubbo:service /> 标签进行服务暴露了。如下:
1 | <dubbo:service interface="com.bill.api.IHelloService" ref="helloService" /> |
其中,interface 属性为提供服务的接口,ref 属性为该接口的具体实现类的引用。
延迟暴露
如果服务需要预热的时间,比如初始化缓存、等待相关资源就位,就可以使用delay 属性进行服务延迟暴露,如下:
1 | <!-- 延迟5秒暴露服务 --> |
并发控制
如果一个服务的并发量过大,超出了服务器的承载能力,那么就需要限制连接的数量了,如下:
1 | <!-- 限制IHelloService 接口的每个方法,服务器端的并发执行(或占用线程池的线程数)不能超过10个 --> |
除了限制接口中的所有方法,还可以限制接口中的制定的方法,如下:
1 | <!-- 限制IHelloService 接口的sayHello() 方法,服务器端的并发执行(或占用线程池的线程数)不能超过10个 --> |
以上是服务提供者实现的并发控制,客户端同样可以实现并发控制,即通过actives 属性限制,如下:
1 | <!-- 限制IHelloService 接口的每个方法,每个客户端的并发执行(或占用线程池的线程数)不能超过10个 --> |
同服务提供者一样,除了限制接口中的所有方法,还可以限制接口中的制定的方法,如下:
1 | <!-- 限制IHelloService 接口的sayHello() 方法,每个客户端的并发执行(或占用线程池的线程数)不能超过10个 --> |
控制连接
为了保障服务的稳定性,除了限制并发线程,还可以限制服务端的连接数,如下:
1 | <!-- 限制服务器端的连接数不能超过10个 --> |
同样也可以限制客户端的使用连接数,如下:
1 | <dubbo:reference interface="com.bill.IHelloService" connections="10" /> |
如果<dubbo:reference /> 和<dubbo:service /> 都配置了connections ,则<dubbo:reference />优先。由于服务提供者了解自身的承载能力,推荐让服务提供者控制连接数。
服务隔离
在服务暴露的过程中,除了常用的控制并发、控制连接数、服务隔离也是很重要的。
服务隔离是为了在系统发生故障时限定传播范围和范围影响,从而保证只要出问题的服务不可用,其他服务还是正常的。
隔离一般有线程隔离、读写隔离、集群隔离和机房隔离,而Dubbo 提供了分组隔离,即使用group 属性分组,如下:
1 | <!-- 将服务提供者分组,分为QQ 和WeChat 两登录组 --> |
服务暴露还提供了很多有用的配置属性,比如version 版本号、timeout 服务请求超时、retries 服务请求失败重试次数、weight 服务权重、cluster 集群方式等。
更多的属性配置,可以查看官网“schema 配置参考手册”中<dubbo:service /> 标签的内容。
引用服务
在服务提供者暴露服务之后,服务消费者就可以使用以下方式引用服务了。如下:
1 | <!-- 生成远程服务代理类,可以像本地的类一样使用helloService --> |
服务异步调用
默认情况下是使用同步的方式进行远程调用的,若想使用异步方式,则可以设置async 属性为true ,并使用Future 获取返回值。如下:
1 | <!-- 在配置中设置异步调用的方式 --> |
下面是异步调用的代码,如下:
1 | // 获取远程服务 |
在异步调用中还可以设置是否需要等待发送和返回值,如下:
- sent=”true” :等待消息发出,消息发送失败将抛出异常。
- sent=”false” :不等待消息发出,将消息放入I/O 队列中,即刻返回。
- return=”false” :只是想异步,完全忽略返回值,减少Future对象的创建和管理成本。
如下:
1 | <dubbo:method name="sayHello" async="true" sent="true" /> |
时间通知机制
Dubbo 的异步调用是基于NIO 的非阻塞机制实现的,客户端不需要启动多线程即可完成并行调用多个远程服务,相对多线程开销较小,一些记录日志信息的服务可以直接使用异步调用执行。
异步调用和同步调用的过程如下:
在远程调用的过程中如果出现异常或者回调,则可以使用Dubbo 的时间通知机制,主要有以下三种事件:
- oninvoke(args1, args2): 为在远程调用之前触发的事件。
- onreturn(return, args1, args2): 为远程调用之后的回调事件。
- onthrow(Throwable ex, args1, args2): 为在远程出现异常时触发的事件,可以在该事件中实现服务的降级,返回一个默认值等操作。
在消费者实现事件通知时,要首先定义一个通知接口INotify ,并实现相关业务,如下:
1 | interface INotify { |
在消费者方配置指定的事件通知接口,配置如下:
1 | <bean id="notify" class="com.bill.NotifyImpl" /> |
以上实现了事件通知,其中callback 和async 属性搭配使用,async 表示结果是否需要马上返回,onreturn 表示是否需要回调,有以下几种情况:
- 异步回调:async=true onreturn=”xxx”
- 同步回调:async=false onreturn=”xxx”
- 异步无回调:async=true
- 同步无回调:async=false
缓存
由于消费者每次远程调用服务时都会有网络开销,而某些热门数据的访问量又比较大,也不经常改变,因此Dubbo 为了加速热门数据的访问速度,提供了声明式缓存,以减少用户额外添加缓存的工作量。
可以通过在消费者方配置cache 属性来开启缓存功能,用法如下:
1 | <dubb:reference interface="com.bill.IHelloService" cache="lru" /> |
Dubbo 的缓存类型有以下几种:
- Lru: 基于最少使用原则删除多余的缓存,保持最热的数据被缓存。
- Threadlocal: 当前的线程缓存。
- jcache: JSR107 集成,可以桥接各种缓存实现。
直接连接
除了消费者通过注册中心引用服务的方式,Dubbo 还提供了直接连接提供者的方式。通常情况下,在开发及测试环境下需要绕过注册中心,只测试指定的服务提供者,这时可能需要点对点的直连方式,直接以服务接口为单位,忽略注册中心的提供者列表。
直接配置有三种方式:
- 通过XML 配置
1
<dubbo:reference id="helloService" interface="com.bill.IHelloService" url="dubbo:127.0.0.1:20890" />
- 通过-D 参数配置
1
java -D com.bill.IHelloService=dubbo:127.0.0.1:20890
- 通过文件映射
1
java -Ddubbo.resolve.file=test.properties
另外,引用服务同暴露服务一样,提供了很多有用的配置属性,比如version 版本号、timeout 服务请求超时、retries 服务请求失败重试次数、group 分组、cluster 集群方式、protocol 使用协议等。
Dubbo 通信协议及序列化
Dubbo 支持的协议
- Dubbo 协议:为Dubbo 的默认协议,采用单一长连接和NIO 异步通信,适合小数据量大并发的服务调用,以及服务消费者的机器数远大于服务提供者的机器数的情况。
- Hessian 协议:用于集成Hessian 的服务,Hessian 底层采用HTTP 通信,采用Servlet 暴露服务,Dubbo 默认内嵌Jetty 作为服务器的实现。
- HTTP: 基于HTTP 表单的远程调用协议,采用Spring 的HttpInvoker 实现。
- RMI 协议: RMI 协议采用JDK 标准的java.rmi.* 实现,采用阻塞式短连接和JDK 标准序列化方式。如果正在使用RMI 提供服务给外部访问,同时应用里依赖了老的common-collections 包 的情况下,存在反序列化安全风险。
- WebService 协议: 基于WebService 的远程调用协议,基于Apache CXF 的frontend-simple 和transports-http 实现。
可以和原生WebService 服务互操作,即: - 提供者用Dubbo 的WebService 协议暴露服务,消费者直接用标准WebService 接口调用,
- 或者提供方用标准WebService 暴露服务,消费方用Dubbo 的WebService 协议调用。
- Thrift 协议: 当前dubbo 支持的thrift 协议是对thrift 原生协议的扩展,在原生协议的基础上添加了一些额外的头信息,比如service name,magic number 等。使用dubbo thrift 协议同样需要使用thrift 的idl compiler 编译生成相应的java 代码,后续版本中会在这方面做一些增强。
- Memcached 协议: 基于memcached 实现的RPC 协议。
- Redis 协议: 基于Redis 实现的RPC 协议。
在实际的项目中,不同的应用对应不同的服务,选择合适的协议是一件非常重要的事情,根据自己的应用来选择。
下面说一下Dubbo 协议,这协议也是官方推荐的协议。
其中,传输层(Transporter) 可以采用Mina 框架、Netty 框架或Grizzy 框架;序列化层(Serialization) 可以采用Dubbo 格式、Hessian2 格式、Java 序列化或JSON 格式。
协议的配置方法
配置协议的方式主要有三种:
直接使用<dubbo:protocol /> 标签配置。
1
<dubbo:protocol name="dubbo" port="20880" />
通过<dubbo:provider /> 标签设置默认协议。
1
<dubbo:provider protocol="dubbo" />
使用<dubbo:service /> 标签在服务暴露时设置。
1
<dubbo:service protocol="dubbo" />
在<dubbo:protocol /> 标签中还有很多的属性,如下:1
<dubbo:protocol name="dubbo" port="9090" server="netty" client="netty" codec="dubbo" serialization="hessian2" charset="UTF-8" threadpool="fixed" threads="100" queues="0" iothreads="9" buffer="8192" accepts="1000" payload="8388608" />
相同的协议也可以使用不同的接口:
1
2<dubbo:protocol id="dubbo1" name="dubbo" port="20880" />
<dubbo:protocol id="dubbo2" name="dubbo" port="20881" />
Dubbo 协议在默认情况下在每个服务的所有提供者和消费者之间使用单一长连接,如果传输数据量较大,则可以使用多个连接,具体连接的个数通过属性connections 来设置,多个连接的配置如下:1
2<dubbo:service connections="1"/>
<dubbo:reference connections="1"/>对具体的配置参数说明如下:
- <dubbo:service connections=”0”> 或 <dubbo:reference connections=”0”> 表示该服务使用JVM 共享长连接。缺省
- <dubbo:service connections=”1”> 或 <dubbo:reference connections=”1”> 表示该服务使用独立长连接。
- <dubbo:service connections=”2”> 或<dubbo:reference connections=”2”> 表示该服务使用独立两条长连接。
在实际使用过程中,为了防止服务被大量的连接压垮,可以由服务器端设置最大允许的连接数,以实现服务的自我保护。如下:
1 | <dubbo:protocol name="dubbo" accepts="1000"> |
多协议暴露服务
Dubbo 不仅支持多种协议可供选择,还支持让不同的服务使用不同的的协议或让相同的服务使用不同的协议。
不同的服务可以使用不同的协议进行传输来提高性能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<dubbo:application name="world" />
<dubbo:registry id="registry" address="10.20.141.150:9090" username="admin" password="hello1234" />
<!-- 多协议配置 -->
<dubbo:protocol name="dubbo" port="20880" />
<dubbo:protocol name="rmi" port="1099" />
<!-- 使用dubbo协议暴露服务 -->
<dubbo:service interface="com.alibaba.hello.api.HelloService" version="1.0.0" ref="helloService" protocol="dubbo" />
<!-- 使用rmi协议暴露服务 -->
<dubbo:service interface="com.alibaba.hello.api.DemoService" version="1.0.0" ref="demoService" protocol="rmi" />
</beans>同一个服务可以使用不同的协议。
1
2
3
4
5
6
7
8
9
10
11
12
13
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<dubbo:application name="world" />
<dubbo:registry id="registry" address="10.20.141.150:9090" username="admin" password="hello1234" />
<!-- 多协议配置 -->
<dubbo:protocol name="dubbo" port="20880" />
<dubbo:protocol name="hessian" port="8080" />
<!-- 使用多个协议暴露服务 -->
<dubbo:service id="helloService" interface="com.alibaba.hello.api.HelloService" version="1.0.0" protocol="dubbo,hessian" />
</beans>
Dubbo 协议的使用注意事项
- 在实际情况下消费者的数据比提供者的数量要多。
- 不能传输大的数据包。
- 推荐使用异步单一长连接方式。
Dubbo 协议的约束
- 参数及返回值需要实现Serialization 接口。
- 参数及返回值不能自定义实现List、Map、Number、Date、Calendar 等接口,只能使用JDK 自带的实现,因为Hessian 会做特殊处理,自定义实现类中的属性值会丢失。
- Hessian 序列化,只传成员属性值和值的类型,不传方法或静态变量。
- 更多的兼容情况请参考官网。
I/O 线程模型
Dubbo 中I/O模型分析
Dubbo 的服务提供者主要有两种线程池模型:
- I/O 处理线程池。
作为I/O 处理线程池,由于Dubbo 是基于Mina、Grizzly 和Netty 等框架实现的I/O 组件,所以他的I/O 线程池都是基于这些框架配置的。
对于这些框架,Dubbo 默认配置无限制大小的CachedThreadPool 线程池,这意味着他对所有的服务的请求都不会拒绝,但是Dubbo 限制I/O 线程数,默认是核数+1,而服务调用的默认线程数是200。
Dubbo 的I/O 示意图如下:
- 业务调度线程池。
Dubbo 中的线程池使用说明如下:
- 如果事件处理的逻辑能迅速完成,并且不会发起新的IO 请求,比如只是在内存中记个标识,则直接在IO 线程上处理更快,因为减少了线程池调度。
- 但如果事件处理逻辑较慢,或者需要发起新的IO 请求,比如需要查询数据库,则必须派发到线程池,否则IO 线程阻塞,将导致不能接收其它请求。
- 如果用IO 线程处理事件,又在事件处理过程中发起新的IO 请求,比如在连接事件中发起登录请求,会报“可能引发死锁”异常,但不会真死锁。
Dubbo 中线程配置的参数
Dubbo 线程相关的配置,可以通过<dubbo:protocol /> 标签的dispatcher、threadpool、threads 和accepts 这四个属性值设置,配置如下:
1 | <dubbo:protocol name="dubbo" dispatcher="all" threadpool="fixed" threads="100" /> |
在实际项目中需要通过不同的派发策略和线程池配置的组合来应对不同的场景,对相关的配置参数说明如下。
Dispatcher 参数如下:
- all: 所有消息都派发到线程池,包括请求,响应,连接事件,断开事件,心跳等。
- direct: 所有消息都不派发到线程池,全部在 IO 线程上直接执行。
- message: 只有请求响应消息派发到线程池,其它连接断开事件,心跳等消息,直接在 IO 线程上执行。
- execution: 只请求消息派发到线程池,不含响应,响应和其它连接断开事件,心跳等消息,直接在 IO 线程上执行。
- connection: 在 IO 线程上,将连接断开事件放入队列,有序逐个执行,其它消息派发到线程池。
ThreadPool 参数如下:
- fixed: 固定大小线程池,启动时建立线程,不关闭,一直持有。(缺省)
- cached: 缓存线程池,空闲一分钟自动删除,需要时重建。
- limited: 可伸缩线程池,但池中的线程数只会增长不会收缩。只增长不收缩的目的是为了避免收缩时突然来了大流量引起的性能问题。
- eager: 优先创建Worker 线程池。在任务数量大于corePoolSize 但是小于maximumPoolSize 时,优先创建Worker 来处理任务。当任务数量大于maximumPoolSize 时,将任务放入阻塞队列中。阻塞队列充满时抛出RejectedExecutionException 。(相比于cached:cached 在任务数量超过maximumPoolSize 时直接抛出异常而不是将任务放入阻塞队列)
Dubbo 线程方面的坑
- 线程设置过少的问题。在使用过程中如多出现了以下异常,则可以适当增加threads 的数量来解决线程不足的问题,Dubbo 默认threads 为200。
- 线程设置过多的问题。如果线程数过多,则可能会受Linux 用户线程数的限制而导致异常。
- 连接不上服务端的问题。大多数情况下因为服务器没有正常启动或者网络连接无法连接,不过也可能是因为超过了服务端的最大连接数。
Dubbo 线程使用建议
在消费者和提供者之间默认只会建立一条TCP 连接。为了增加服务消费者调用服务提供者的吞吐量,也可以在消费者的<dubbo:reference /> 中配置connections 来单独增加消费者和服务提供者的TCP 长连接,但线上业务由于有多个消费者和多个提供者,因此不建议增加connections 参数。
在连接成功后,具体的请求就会交给I/O 线程处理。由于I/O 线程是异步读写数据的,因此他消耗更多的CPU 资源,所以I/O 线程数默认为CPU 的个数加1 比较合理,不建议调整此参数。
数据在被读取并被序列化后,会被交给业务线程池处理,在默认情况下线程池为固定的大小,因此他的最大并发量等于业务线程池的大小。但是,如果希望有请求的堆积能力,则可以调整queues 属性来设置队列的大小,一般建议不要设置,因为在线程池满时应该立即失败,再自动重试其他服务提供者,而不是排队。
集群的容错机制和负载均衡
集群容错机制原理
假设我们使用的是单机模式的Dubbo 服务,则如果在服务提供者(Provider) 发布服务以后,服务消费者(Consumer) 发出一次调用请求,恰好这次由于网络延迟调用失败,我们可以配置服务消费者的重试策略,可能消费者的第二次调用就会成功。
但是如果服务提供者所在的节点发生故障,那么消费者再怎么重试都会失败,因此才需要采用集群容错模式。
如果单个服务节点发生故障无法提供服务,则我们可以根据配置的集群容错模式,调用其他的可用服务节点,这就提高了服务的可用性。
Dubbo 官方文档中及各组件中的关系如下:
上述组件中的关系:
- Invoker 是Provider 的一个可调用的Service 抽象,Invoker 封装了Provider 的地址及Service 的接口信息。
- Directory 代表多个Invoker,可以把它看成List
,但与List 不同的是,它的值可能是动态变化的。比如注册中心推送变更。 - Cluster 将Directory 中的多个Invoker 伪装成一个Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,则重试另一个。
- Router 负责从多个Invoker 中按路由规则选出子集,比如读写分离,应用隔离等。
- LoadBalance 负责从多个Invoker 中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,则需要重选。
集群容错机制配置
服务提供者和服务消费者配置集群模式如下:
1 | <!-- 服务提供者配置 --> |
或者
1 | <!-- 服务消费者配置 --> |
其中,容错模式就是通过cluster 属性进行配置的,目前Dubbo 支持6中模式:Failover、Failfast、Failsafe、Failback、Forking 和Broadcast 。
集群容错模式
Failover Cluster 模式
配置值为failover ,是Dubbo 集群容错默认选择的模式,在调用失败后会自动切换,重新尝试其他节点上可用的服务。可通过retries 属性来设置重试次数(不包含第一次),配置方式有以下几种:1
2
3
4
5
6
7
8<!-- 在服务提供者一方配置重试次数 -->
<dubbo:server retries="2" />
<!-- 在服务消费者一方配置次数 -->
<dubbo:reference retries="2" />
<!-- 还可以在方法级别上配置重试次数 -->
<dubbo:reference>
<dubbo:method name="sayHello" retries="2" />
</dubbo:reference>Failfast Cluster 模式
配置值为failfast ,又叫作快速迭代失败模式,调用只执行一次,若失败则立即报错。
这种模式适用于非幂等性操作,每次调用的副作用是不同的,比如数据库的写操作,或者交易系统中的订单操作,如果失败了一次就应该让他直接失败,不需要重试。Failsafe Cluster 模式
配置值为failsafe ,又叫失败安全模式,如果调用失败,则直接忽略失败的调用,记录失败的调用到日志文件中,以便后续审计。Failback Cluster 模式
配置值为failback ,在失败后自动恢复,后台记录失败的请求,定时重发,通常用于消息通知操作。Forking Cluster 模式
配置值为forking ,并行调用多个服务器,只要一个成功便返回。通常用于实时性要求较重的读操作,但需要浪费更多的服务资源。可通过forks 属性来设置最大的并行数。Broadcast Cluster 模式
配置值为broadcast ,广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
集群的负载均衡
Dubbo 框架内置了负载均衡的功能及扩展接口,我么可以透明地扩展一个服务或服务集群,根据需要能非常容易地增加或移除节点,提高服务的可伸缩性,Dubbo 内置了4种负载均衡策略:随机(Random) 、**轮询(RoundRobin)、最少活跃调用数(LeastActive)、一致性Hash(ConsistentHash)**。
集群的负载均衡配置方法
集群的负载均衡可以在服务端的服务接口级别进行配置:
1 | <dubbo:server interface="..." loadbalance="roundrobin" /> |
也可以在客户端的服务接口级别进行配置:
1 | <dubbo:reference interface="..." loadbalance="roudrobin" /> |
还可以在服务端的方法级别进行配置:
1 | <dubbo:service interface="..."> |
并且也可以在客户端的方法级别进行配置:
1 | <dubbo:reference interface="..." > |
集群的四种负载均衡策略
- 随机模式。
随机,指按权重设置随机概率。
在一个截面上碰撞的概率较高,但调用量越大时分布越均匀,而且按概率使用权重后分布也比较均匀,有利于动态调整提供者的权重。 - 轮询模式。
轮询,指按公约后的权重设置轮询比率。
该模式会存在响应慢的提供者会累积请求的问题。 - 最少活跃调用数。
指响应慢的提供者受到更少的请求的一种调用方式,如果活跃数相同的则随机。
活跃数指调用前后的技术差,而响应越慢的提供者调用前后的技术差越大。 - 一致性Hash。
指带有相同参数的请求总是被发给同一个提供者。
在某台提供者挂掉时,原本发往该提供者的请求会基于虚拟节点平摊到其他提供者上,不会引起剧烈变动。
监控和运维
日志适配
对于应用系统来说,日志是其非常重要的一个方面,Dubbo 内置了log4j、slf4j、jcl、jdk 这些日志框架的适配,可以通过以下方式配置日志的输出策略。
- 命令行
1
java -Ddubbo.appication.logger=log4j
- 在dubbo.properties 中指定
1
dubbo.application.logger=log4j
- 在dubbo.xml 中配置 如果想记录每一次的请求信息,则可以开启访问日志,类似于Apache 的访问日志,可以通过一下两种方式设置:
1
<dubbo:application logger="log4j" />
- 将访问日志输出到当前的Log4j 日志中
1
<dubbo:protocol accesslog="true" />
- 将访问日志输出到指定文件中 Dubbo 的访问日志量较大,请注意磁盘的容量。
1
<dubbo:protocol accesslog="http://192.168.1.100/log/accesslog.log" />
监控管理后台
Dubbo 官方开源管理后台
dubbo-moniter 开源管理后台
DubboKeeper 开源管理后台
服务降级
服务熔断是一种保护措施,一般用于防止在软件系统中由于某些原因使服务出现了过载现象,从而造成整个系统发生故障,有时也被称为过载保护。
服务降级则是在服务器压力剧增的情况下,根据当前的业务情况下及流量对一些服务和页面有策略地进行降级,以释放服务器资源并保证核心任务的正常运行。
Hystrix 使Netfix 的开源框架,主要用于解决分布式系统交互时的超时处理和容错,具有保护系统稳定性的功能,是目前最流行和最广泛地容错系统。Hystrix 的设计主要包括资源隔离、熔断器、命令模式。而Dubbo 同样具备一定的服务熔断和降级功能,下面说一下Dubbo 中如何实现服务降级功能。
本地伪装
Dubbo 通过使用mock 配置来实现服务降级,mock 在出现非业务异常时执行,mock 支持如下两种配置:
- 配置为boolean 值。默认配置为false ,如果配置为true ,则默认使用mock 的类名,即类名+Mock 后缀。
- 配置为return null ,可以很简单地会略掉异常。
在Spring 配置文件中按以下方式配置:
1 | <dubbo:service interface="com.bill.IHelloService" mock="true" /> |
再在项目中提供Mock 地实现类:
1 | package com.bill; |
如果只是想简单的忽略异常,则可以值设置mock 属性值为“return null”。
1 | <dubbo:service interface="com.foo.BarService" mock="return null" /> |
当然也可以通过向注册中心写入动态配置来覆盖规则来忽略异常:
1 | RegistryFactory registryFactory = ExtensionLoader.getExtensionLoader(RegistryFactory.class).getAdaptiveExtension(); |
其中:
- mock=force:return+null 表示消费方对该服务的方法调用都直接返回null 值,不发起远程调用。用来屏蔽不重要服务不可用时对调用方的影响。
- 还可以改为mock=fail:return+null 表示消费方对该服务的方法调用在失败后,再返回null 值,不抛异常。用来容忍不重要服务不稳定时对调用方的影响。
优雅停机
Dubbo 是通过JDK 的ShutdownHook 来完成优雅停机的,所以如果用户使用kill -9 PID 等强制关闭指令,是不会执行优雅停机的,只有通过kill PID 时,才会执行。
设置优雅停机超时时间,缺省超时时间是 10 秒,如果超时则强制关闭。
1 | # dubbo.properties |
如果ShutdownHook 不能生效,可以自行调用,使用tomcat 等容器部署的場景,建议通过扩展ContextListener 等自行调用以下代码实现优雅停机:
1 | ProtocolConfig.destroyAll(); |
服务提供方的实现原理如下:
- 停止时,先标记为不接收新请求,新请求过来时直接报错,让客户端重试其它机器。
- 然后,检测线程池中的线程是否正在运行,如果有,等待所有线程执行完成,除非超时,则强制关闭。
服务消费方的实现原理如下:
- 停止时,不再发起新的调用请求,所有新的调用在客户端即报错。
- 然后,检测有没有请求的响应还没有返回,等待响应返回,除非超时,则强制关闭。
灰度发布
灰度发布(又名金丝雀发布)是指在黑与白之间,能够平滑过渡的一种发布方式。在其上可以进行A/B testing,即让一部分用户继续用产品特性A,一部分用户开始用产品特性B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。
灰度发布的部署过程如下:
- 从负载均衡列表中移除“金丝雀”服务器,切断用户流量。
- 对“金丝雀”服务器进行更新部署,此时的服务器为新版本。
- 对“金丝雀”服务器上的新版本进行测试。
- 将“金丝雀”服务器重新添加到负载均衡列表中。
- 如“金丝雀”果服务在线使用测试成功,则继续升级剩余的其他服务器,否则回滚。
Dubbo 可以通过group 分组的方式进行灰度发布,具体如下:
- 将服务提供者(provider)分为A、B 两组,将新版本的group 修改为B 组,例如/service/B ,并将B 组发布到线上。此时的旧版本的group 为A 组,例如/service/A 。
- 发布新版本的消费者(consumer),并修改消费者的group 为/service/B 。
- 结合反向代理服务的功能权重设置,将部分流量切换到group 为/service/B 的消费者上进行测试。
- 如果测试没有问题,则继续将旧的服务提供者各消费者都更新版本,同时设置group 为/service/B 。
上线案例解析
线上问题的通用解决方案
发现问题
发现问题通常通过自动化的监控和报警系统来实现,线上游戏服搭建了一个完善、有效的日志中心、监控和报警系统,通常我们会从系统层面、应用层面和数据库层面进行监控。
对系统层面的监控包括对系统的CPU利用率、系统负载、内存使用情况、网络I/O负载、磁盘负载、I/O等待、交换区的使用、线程数及打开的文件句柄数等进行的监控,一旦超出阈值,就需要报警。
对应用层面的监控包括对服务接口的响应时间、吞吐量、调用频次、接口成功率及接口的波动率等进行的监控。
对资源层的监控包括对数据库、缓存和消息队列的监控。我们通常会对数据库的负载、慢SQL、连接数等进行监控;对缓存的连接数、占用内存、吞吐量、响应时间等进行监控;并对消息队列的响应时间、吞吐量、负载、积压情况等进行监控。定位问题
定位问题时,首先要根据经验来分析,如果应急团队中有人对相应的问题有经验,并确定能够通过某种手段进行恢复,则应该第一时间恢复,同时保留现场,然后定位问题。
应急人员在定位过程中需要与业务负责人、技术负责人、核心技术开发人员、技术专家、架构师、运营人员和运维人员一起,对产生问题的原因进行快速分析。在分析的过程中要先考虑系统最近的变化,考虑如下问题。
问题系统最近是否进行了上线?
依赖的基础平台和资源是否进行了上线或者升级?
依赖的系统最近是否进行了上线?
运营人员是否在系统里做过运营变更?
网络是否有波动?
最近的业务是否上量?
服务的使用方是否有促销活动?解决问题
解决问题的阶段有时处于应急处理中,有时处于应急处理后。
在理想情况下,每个系统都会对各种严重情况设计止损和降级开关,因此在发生严重问题时先使用止损策略,在恢复问题后再定位和解决问题。解决问题要以定位问题为基础,必须清晰地定位问题产生的根本原因,再提出解决问题的有效方案,切记在没有明确原因之前,不要使用各种可能的方法来尝试修复问题,这样可能导致还没有解决这个问题又引出另一个问题。消除影响
在解决问题时,某个问题可能还没被解决就已恢复,在任何情况下都需要消除问题带来的影响。
- 技术人员在应急过程中对系统做的临时性改变,若在后面证明是无效的,则要尝试恢复到原来的状态。
- 技术人员在应急过程中对系统进行的降级开关操作,在事后需要恢复。
- 运营人员在应急过程中对系统做的特殊设置如某些流量路由的开关,在事后需要恢复。
- 对使用方或者用户造成的问题,尽量采取补偿的策略进行修复,在极端情况下需要一一核实。
- 对外由专门的客服团队整理话术,统一对外宣布发生故障的原因并安抚用户,话术要贴近客观事实,并从用户的角度出发。
在详细了解如何发现问题、定位问题、解决问题和消除造成的影响后,接下来让我们看看在实际情况下如何应用。
首先,找运维看日志。如果在日志监控系统中有报错,则能很好地定位问题,我们只需根据日志报错的堆栈信息来解决问题即可。如果在日志监控系统中没有任何异常信息,就得保存现场了。
其次,保存现场并恢复服务。在日志系统中找不到任何线索的情况下,我们需要赶紧保存现场快照,并尽快恢复服务,以达到最大程度止损的目的。在JVM中保存现场快照通常包括保存当前运行线程的快照和保存JVM内存堆栈快照。如下所述。
- 保存当前运行线程的快照,可以使用jstack [pid]命令实现,在通常情况下需要保存三份不同时刻的线程快照,时间间隔为1~2分钟。
- 保存JVM内存堆栈快照,可以使用jmap –heap、jmap –histo、jmap -dump:format=b、file=xxx.hprof等命令实现。
快速恢复服务的常用方法如下:
- 隔离出现问题的服务,使其退出线上服务,便于后续的分析处理。
- 尝试快速重启服务,第一时间恢复系统,而不是彻底解决问题。
- 对服务降级处理,只使用少量的请求来重现问题,以便我们全程跟踪观察,因为之前可能没太注意这个问题是如何发生的。
通过上面的一系列操作后,要分析日志并定位问题。这一步很关键,也需要有很多实战经验,需要先查看服务器的“当前症状”,才能进一步对症下药。下面提供从服务器的CPU、内存和I/O三方面查看症状的基本方法。
查看CPU或内存情况的命令如下:
- top:查看服务器的负载状况。
- top+1:在top视图中按键盘数字“1”查看每个逻辑CPU的使用情况。
- jstat –gcutil pid:查看堆中各内存区域的变化及GC的工作状态。
- top+H:查看线程的使用情况。
- ps -mp pid -o THREAD,tid,time | sort -rn:查看指定进程中各个线程占用CPU的状态,选出耗时最多、最繁忙的线程id。
- jstack pid:打印进程中的线程堆栈信息。
判断内存溢出(OOM)方法如下:
- 堆外内存溢出:由JNI的调用或NIO中的DirectByteBuffer等使用不当造成。
- 堆内内存溢出:容易由程序中创建的大对象、全局集合、缓存、ClassLoader加载的类或大量的线程消耗等造成。
- 使用jmap –heap命令、jmap –histo命令或者jmap-dump:format=b,file=xxx.hprof等命令查看JVM内存的使用情况。
分析I/O读写问题的方法如下:
- 文件I/O:使用命令vmstat、lsof –c -ppid等。
- 网络I/O:使用命令netstat –anp、tcpdump -i eth0 ‘dst host 239.33.24.212’ -w raw.pcap和wireshark工具等。
- MySQL数据库:查看慢查询日志、数据库的磁盘空间、排查索引是否缺失,或使用show processlist检查具体的SQL语句情况。
最后,在Hotfix 后继续观察情况。在测试环境或预生产环境修改测试后,如果问题不能再复现了,就可以根据公司的Hotfix流程进行线上的Bug更新,并继续观察。如果一切都正常,就需要消除之前可能造成的影响。
耗时服务耗尽线程池的案例
有一次,我们线上的某个Web服务访问报HTTP 500错误,在查看log日志时报异常,异常的关键信息如下:
1 | Caused by:java.util.concurrent.RejectedExecutionException: |
我们并没有手动设置过服务端线程池的大小,默认使用200,从报错日志来看,明显是服务端的线程池被用光了。
接下来使用jstack pid 打印进程中的线程堆栈信息,确实有200个Dubbo 线程在不断地执行,Dubbo 线程的命名格式为:DubboServerHandler-192.168.168.101:20880-thread-num。
为什么突然有这么多线程不断执行呢?是用户量突然增大了,还是有爬虫攻击?带着这些问题,笔者查看了网络流量监控,并未发现有明显的流量突增。
我们通过日志和监控暂时没有发现问题的成因,就添加了些日志,添加了请求时长打印,也增加了服务端的线程数。问题依然存在,不过可以排除服务端的线程数设置的问题了。
最后,通过新添加的日志打印发现,服务的请求时间普遍很长,这引起了我们的注意,顺着该线索找下去,才发现是服务调用数据库的时间太长,所以最后定位为数据库的问题。
在定位为是数据库执行慢导致很多线程占用不释放后,我们开始查看MySQL慢查询日志。由于之前慢查询的阀值时间被设置为1秒,所以在慢查询日志中没有任何记录;然后使用show processlist 查看SQL 的执行情况,发现有一条SQL 语句占用的时间较长;最后,修改慢查询的时间为500毫秒,并记录下相关的慢查询SQL语句。
我们采取的解决方法为:为慢查询语句添加索引并修改逻辑代码,恢复之前的修改。通过查看codereview 相关的代码,我们发现有部分业务逻辑在for 循环中多次查询数据库,便将其修改为一次查询多条数据,然后在for 循环中使用。
记一次log4j日志导致线上OOM问题案例
项目各项环境参数
项目使用dubbo框架,dubbo线程池配置500
项目内存配置2G,old区1.5G
项目使用: og4j + Disruptor 实现的异步记录日志
log4j-api版本2.6.2
log4j-core版本2.6.2
disruptor版本3.3.6问题分析
都知道发生OOM 问题是因为内存不够,造成原因却有很多。具体的场景具体分析,通过gc日志发现每次full gc回收的内存越来越少,造成最后OutOfMemoryError: GC overhead limit exceeded。
通过Java MAT工具分析dump发现,一个最大dubbo线程占用内存12M,总的dubbo线程占用内存加起来都已经1.6G了。
为什么一个dubbo线程会占用这个大的内存呢,很是奇怪,节点打开一个具体线程信息看到,一个dubbo线程是有一个threadlocal对象,threadlocal对象里面引用了一个java StringBuilder对象,改对象有char数组6百多万,占用内存12M。
通过ThreadLocalMap$Entry 对象里referent 属性找到引用ThreadLocal 对象。
看到这里,觉得有点希望了,继续打开代码搜索log4j中ParameterizedMessage类,看到里面有一行代码:1
2// storing JDK classes in ThreadLocals does not cause memory leaks in web apps, so this is okay
private static ThreadLocal<StringBuilder> threadLocalStringBuilder = new ThreadLocal<>();这个StringBuilder 不就是上面看到打对象吗,知道了这个对象,接下来就是看这个ThreadLocal 是怎么使用的。
继续查看log4j + Disurptor源码,发现在打日志代码中,RingBufferLogEvent中setMessage方法会进行打印日志的一个格式化。
继续跟进去,看看格式化具体做了什么即 ParameterizedMessage.getFormattedmessage()方法。
问题就出在这个方法里,方法是从当前线程ThreadLocal里面拿到StringBuilder对象,然后每次将length置0,然后将日志append进去。
所以从这里就知道,只要有一次日志内容打印很多情况下,会造成StringBuilder里字段串对象很大,而且是不会销毁(除非当前ThreadLocal线程死了,前面说了项目配置了dubbo 500个线程,dubbo 线程不死,所以这个对象一直都在),打印大日志对象次数多了,基本上造成所有dubbo 线程ThreadLocal、StringBuilder 对象都很大。正如第一幅图看到一样,最终造成OOM。
log4j 2.6.2这里进行日志格式化,打印日志内容过大时候确实会造成这个问题然后拉取了下log4j新一些的,发现在log4j 在2.9.0版本解决了这个问题,如何解决的呢,具体来看看代码吧,还是ParameterizedMessage.getFormattedmessage() 这个方法。
发现只多了一行代码,继续看,这里回判断如果stringbuilder不为null并且容量大于maxSize(这个参数可配,默认518),会将长度置为maxSize,然后调用trimToSize 方法。
刚方法就是将原char数组进行了一次copy,copy了一个maxSize大小的数组。
这样即就是每次格式化之后会进行一次判断,如果对象ThreadLocal stringbuilder对象太大会将该对象重新copy一个固定大小,避免老版本出现OOM问题。
Dubbo 源码解析
个人备注
此博客内容均为作者学习《可伸缩服务架构-框架与中间件》与官方文档所做笔记,侵删!
若转作其他用途,请注明来源!