简介
TensorFlow 是由 Google 团队开发的深度学习框架,其初衷是以最简单的方式实现机器学习和深度学习的概念。该框架融合了计算代数的优化技术,极大地方便了复杂数学表达式的计算。
TensorFlow 深度学习框架的三大核心功能:
- 加速计算。神经网络本质上由大量的矩阵相乘、矩阵相加等基本数学运算构成,
TensorFlow的重要功能就是利用GPU方便地实现并行计算加速功能。 - 自动梯度。
TensorFlow可以自动构建计算图,通过TensorFlow提供的自动求导的功能,不需要手动推导即可计算输出对网络参数的偏导数。 - 常用神经网络接口。
TensorFlow除了提供底层的矩阵相乘、相加等数学函数,还包含常用神经网络运算函数、常用网络层、网络训练、模型保存与加载、网络部署等一系列深度学习的功能。
简单示例:
1 | import tensorflow as tf |
基础
数据类型
Tensorflow 中的数据类型包含数值类型、字符串类型和布尔类型。
数值类型
按照维度区分为四种类型:标量、向量、矩阵、张量。
1 | # 标量 |
字符串类型
1 | s1 = tf.constant('Hello Tensorflow!') |
布尔类型
1 | bool_1 = tf.constant(True) |
张量
从数组、列表创建张量
1
2# tf.convert_to_tensor() 函数可以将 list 对象或 numpy 中的对象倒入到新的 Tensor 中
tf.convert_to_tensor([1, 2.]), tf.convert_to_tensor([[1, 2], [3, 4]])创建全
0或1张量1
2
3
4
5
6
7
8# 标量
tf.zeros([]), tf.ones([])
# 向量
tf.zeros([1]), tf.ones([1])
# 矩阵
tf.zeros([2, 2]), tf.ones([3, 2])
# 张量
tf.zeros([2, 2, 2]), tf.ones([3, 2, 2])创建自定义值的张量
1
2# tf.fill(shape, value)
tf.fill([2], -1), tf.fill([2, 3], -2)创建已知分布的张量
1
2# tf.random.normal(shape, mean=0.0, stddev=1.0) 创建形状为 shape,均值为 mean,标准差为 stddev 的正态分布
tf.random.normal([2, 3]), tf.random.normal([2, 2], 1, 2)创建序列
1
2# tf.range(start=0, limit, delta=1) 函数创建一段连续的整数序列
tf.range(10, delta=2), tf.range(2, 10, delta=3)
待优化张量
为了区分需要计算梯度信息的张量和不需要计算梯度信息的张量。Tensorflow 中增加了一种专门的数据类型来支持梯度信息的记录:tf.Variable()。
1 | v1 = tf.constant([-1, 0, 1, 2]) |
应用
张量的典型应用现在说明可能会有点超时,不需要完全理解,有初步印象即可。
标量
1
2
3
4
5
6
7# 就是一个简单的数字,维度数为 0,shape 为 []。常用在于误差值、各种测量指标等。
out = tf.random.normal([4, 10])
y = tf.constant([2, 3, 2, 0])
y = tf.one_hot(y, depth=10)
loss = tf.keras.losses.mse(y, out)
loss = tf.reduce_mean(loss) # 平均 mse
loss向量
1
2
3
4
5# 在 2 个输出节点的网络层,创建长度为 2 的偏置向量,并累加在每个输出节点上
z = tf.random.normal([4, 2])
b = tf.zeros([2])
z = z + b
z矩阵
1
2
3
4
5
6x = tf.random.normal([2, 4])
# 令连接层的输出节点数为 3,则权值张量 w 的shape [4, 3]
w = tf.random.normal([4, 3])
b = tf.zeros([3])
out = x @ w + b
out三维张量
1
2
3
4
5
6
7
8# 三维张量的一个典型应用就是表示序列信号,其格式是 x = [b, sequence len, feature len]
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=10000)
x_train = tf.keras.preprocessing.sequence.pad_sequence(x_train, maxlen=80) # 填充句子,截断为等长 80 个单词的句子
x_train.shape # (25000, 80)
embedding = tf.layers.Embedding(10000, 100) # 创建词向量 Embedding 层类
out = embedding(x_train) # 将数字编码的单词转换为词向量
out.shape # ([25000, 80, 100])四维张量
1
2# 四维张量在卷积神经网络中应用非常广泛,用于保存特征图数据,格式一般为 [b, h, w, c],b 表示输入样本的数量,h/w 表示特征图的高/宽,c表示特征图的通道数。
x = tf.random.normal([4, 32, 32, 3]) # 创造 32x32 的图片输入
数值精度
常见数值精度: tf.int16 、 tf.int32 、 tf.int64 、 tf.float16 、 tf.float32 、 tf.float64 。
1 | d1 = tf.constant(123456789, tf.int16) # 精度不足发生溢出 |
数值运算
加减乘除
加减乘除可以分别通过 tf.add() 、tf.subtract()、tf.multiply()、tf.divide() 函数实现,同时 Tnsorflow 也重载了 +, -, *, /, //, % 运算符。
1 | a = tf.range(5) |
乘方运算
tf.pow(a, x)、tf.square(x)、tf.sqrt(x) 函数分别实现乘方运算、平方和平方根运算。
1 | x = tf.range(4) |
指数对数运算
tf.exp(a) 函数实现自然对数 e 运算。
1 | tf.exp(1.) |
矩阵运算
使用 @ 运算符实现矩阵相乘,而 tf.matmul(a, b) 函数也可以实现。其中 a 的倒数第一个维度长度(行)必须要 b 的倒数第二个维度长度(列)必须相等。
1 | a = tf.random.normal([4, 3, 28, 32]) |
索引和切片
通过索引和切片可以提取张量部分的数据,实践中使用频率很高。
索引
1 | x = tf.random.normal([4, 32, 32, 3]) |
切片
1 | # 通过 start:end:step 切片方式可以提取一段数据 |
维度转换
维度变换是最核心的张量操作,算法的每个模块对于数据张量的格式有不同的逻辑需求,即现有的数据格式不能满足计算的要求,就需要通过维度变换将数据切换形式,满足不同场合的运算需求。
基本的维度变换操作函数有以下几种:改变视图 reshape() 、 插入维度 expand_dims() 、 删除维度 squeeze() 、 交换维度 transpose() 、 复制数据 tile() 。
改变视图
1 | # 张量的存储 Stroage 和视图 View 概念,同一个存储,在不同的角度观察数据,即可以产生不同的视图。 |
增删视图
tf.expand_dims(x, axis) 在指定的 axis 轴前插入一个新的维度。tf.squeeze(x, axis) 其中 axis 为待删除维度的索引号,该参数默认值会删除所有长度为 1 的维度。
1 | # 增加维度,增加一个长度为 1 的维度相当于给原有的数据添加一个新维度的概念,维度长度为 1,故数据格式不需要改变,其仅仅是改变了数据结构的理解方式。 |
交换维度
tf.transpose(x, perm) 其中 perm 表示新维度的顺序 list。
1 | x = tf.random.normal([2, 32, 32, 3]) |
复制数据
tf.tile(x, multiples) 完成数据在指定维度上的复制操作,multiples 表示每个维度上面的复制倍数,对应位置为 1 表示不复制,对应 2 表示复制一份。该函数会创建一个新的张量来保存复制后的张量,因为涉及较多的 IO 操作,计算代价较高。
1 | b = tf.constant([1, 2]) |
Broadcasting
Broadcasting 称为广播机制,是一种轻量级的张量复制手段,在逻辑上扩展张量数据的形状,但只有实际使用时才会执行数据复制操作。Broadcasting 核心设计思想是普适性,即同一份数据可以普遍适合于其他位置。
- 验证普适性之前首先需要将
shape靠右对齐,然后进行普适性判断; - 对于长度为
1的维度,默认这个数据普遍适合于当前维度的其他位置。 - 对于不存在的维度,则在增加维度后默认当前数据是普适于新维度的,从而可以扩展更多维度数、任意长度的张量形状。
1 | x = tf.random.normal([2,4]) |
进阶
合并与分割
合并
合并是指将多个张量在某个维度上合并为一个张量。张量的合并可以通过拼接(Concatenate)和堆叠(Stack)来实现,其中拼接不会产生新的维度,而堆叠会创造新的维度。
拼接和堆叠的唯一约束在于非合并维度的长度必须一致。
1 | # tf.contact(tensors, axis) 函数拼接张量,tensors 表示所有需要合并的张量 list,而 axis 表示拼接张量的维度索引 |
分割
合并的逆操作就是分割,即将一个张量分拆为多个张量。
1 | # tf.split(x, num_or_size_splits, axis),其中参数 num_or_size_splits 指切割方案:单个数值时等长切割;列表时按列表内数值切分。 |
数据统计
在神经网络的计算中通常需要统计数据的各种属性,例如最值、最值位置、均值、范数等。
向量范数
向量范数是表征向量“长度”的一种度量方法,其可以推广到张量上,常用于表示张量的权值大小、梯度大小等。
常用的向量范数:
L1范数,定义为向量x的所有元素绝对值之和。L2范数,定义为向量x的所有元素的平方和,再开根号。np.inf范数,定义为向量x的所有元素绝对值得最大值。
1 | x = tf.ones([2,2]) |
最值、均值、和
tf.reduce_max(x,axis), tf.reduce_min(x,axis), tf.reduce_mean(x,axis), tf.reduce_sum(x,axis) 函数可以求解张量在某个维度或全局上的最大值、最小值、平均值、和。
1 | x = tf.random.normal([4,10]) |
`tf.argmax(x, axis)`, `tf.argmin(x, axis)` 可以获取 `axis` 轴上的最大值、最小值。
1
2
3
out = tf.random.normal([2,10])
out = tf.nn.softmax(out, axis=1) # 通过softmax() 函数转化为概率值
tf.argmax(out, axis=0), tf.argmin(out, axis=1)
张量比较
为了计算分类任务的准确率,一般需要将预测结果和真实标签比较,统计比较结果中的正确值来计算准确率。
1 | out = tf.random.normal([100, 10]) |
tf.equal(a, b) 或者 tf.math.equal(a, b) 均可以实现比较两个张量是否相等,返回布尔类型的张量比较结果。
类似的比较函数还有 tf.math.greater(), tf.math.less(), tf.math.grater_equal(), tf.math.less_equal(), tf.math.not_equal(), tf.math.is_nan()。
1 | y = tf.random.uniform([100], dtype=tf.int64, maxval=10) # 构建真实值 |
填充与复制
填充
在需要长度的数据开始或结束处填充足够数量的特定数值,这些数值通常代表无意义。
1 | # tf.pad(x, padding) padding 包含多个 [Left Padding, Right Padding] 嵌套方案 list |
复制
1 | # tf.tile() 函数可以在任意维度将数据重复复制多份 |
数据限幅
考虑如何实现非线性激活函数 ReLU 的问题,那么其可以通过数据限幅运算实现,限制元素的范围即可。
1 | # tf.maximum(x, a) 函数实现限制数据的下限幅。tf.minimum(x, a) 函数实现限制数据的上限幅。 |
高级操作
tf.gather
根据索引号收集数据。1
2x = tf.random.uniform([4,35,8], maxval=100, dtype=tf.int32)
tf.gather(x, [0,1], axis=0)tf.gather_nd
通过指定每次采样点的多维坐标来实现采样多个点的目的。1
2x = tf.random.uniform([4,35,8], maxval=100, dtype=tf.int32)
tf.gather_nd(x, [[1,1], [2,2], [3,3]])tf.boolean_mask
除了上述索引号的方式采样,还可以通过给定掩码(Mask)的方式进行采样。1
2x = tf.random.uniform([4,35,8], maxval=100, dtype=tf.int32)
tf.boolean_mask(x, mask=[True, False, False, False], axis=0) # 掩码长度必须与维度长度一致tf.where
通过th.where(cond,a,b)操作可以根据cond条件的真假从参数A或参数B中读取数据。1
2
3
4a = tf.ones([3,3])
b = tf.zeros([3,3])
cond = tf.constant([[True,False,False], [False,True,False], [True,True,False]])
tf.where(cond, a, b)tf.scatter_nd
通过tf.scatter_nd(indices, updates, shape)函数可以高效地刷新张量的部分数据,但该函数只能在全0的白板张量上面执行刷新操作。1
2
3indices = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([4.4, 3.3, 1.1, 7.7])
tf.scatter_nd(indices, updates, [8])tf.meshgrid
通过tf.meshgrid()函数可以方便地生成二维网格的采样点坐标,方便可视化。1
2
3
4
5
6
7
8
9
10
11
12
13x = tf.linspace(-8, 8, 100)
y = tf.linspace(-8, 8, 100)
x,y = tf.meshgrid(x, y)
z = tf.sqrt(x**2 + y**2)
z = tf.sin(z) / z
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig)
ax.contour3D(x.numpy(), y.numpy(), z.numpy(), 50)
plt.show()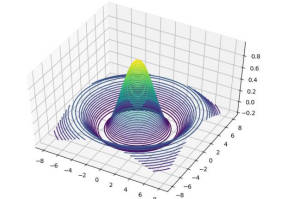
神经网络
神经网络属于机器学习的一个分支,特指利用多个神经元去参数化映射函数的模型。
感知机
感知机模型如下: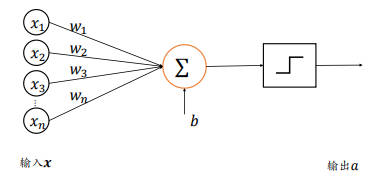
其接受长度为 n 的一维向量 x=[x1,x2,...,x],每个输入节点通过权值 w 的连接汇集为变量 z,即 z = w1*x1 + w2*x2 + ... + w*x + b。
全连接层
感知机模型的不可导特征严重束缚其潜力,使得其只能解决简单的任务。在感知机的基础上,将不连续的阶跃激活函数更换成平滑连续可导的激活函数,并通过堆叠多个网络层来增强网络的表达能力。
通过替换感知机的激活函数,同时并行堆叠多个神经元来实现多输入、多输出的网络结构。
由于每个输出节点与全部的输入节点相连接,这种网络层被称为全连接层 Fully-connected layer 或者稠密连接层 Dense layer ,而 W 矩阵叫做全连接层的权值矩阵 ,b 向量叫做全连接层的偏置向量 。
张量实现
在 TensorFlow 中,要实现全连接层,只需要定义好权值张量 W 和 偏执张量 B,并利用 TensorFlow 提供的批量矩阵相乘函数 tf.matmul() 即可完成网络层的计算。
1 | x = tf.random.normal([2, 784]) |
层实现
全连接层本质上是矩阵的相乘和相加运算,实现并不复杂。但 Tensorflow 中有更方便的实现:layers.Dense(units, activation),函数参数 units 指定输出节点数,activation 激活函数类型。
1 | x = tf.random.normal([4, 28*28]) |
全连接层梯度
在将单个感知机模型推广到全连接的网络时,输入层通过一个全连接层得到输出 o,其与真实结果 t 计算均方误差,均方误差可以表示为:
$$ L = {\frac {1} {2}} sum_{i=1}^K (o_i - t_i)^2 $$
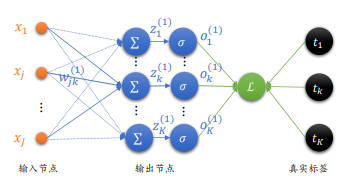
由于 ${\frac {\delta L} {\delta w_{jk}}}$ 仅与节点 $o_k$ 有关系,因此上式中的求和符号可以省略,即 i==k:
$$ {\frac {\delta L} {\delta w_{jk}}} = (o_k - t_k) * {\frac {\delta o_k} {\delta w_{jk}}} $$
考虑 Sigmoid 函数的导数 $\alpha^` = \alpha (1-\alpha)$,代入其中可得:
$$ {\frac {\delta L} {\delta w_{jk}}} = (o_k - t_k) * o_k * (1 - o_k) * {\frac {\delta o_k} {\delta w_{jk}}} $$
再将 ${\frac {\delta o_k} {\delta w_{jk}}} = x_j$ 替换,其最终可得:
$$ {\frac {\delta L} {\delta w_{jk}}} = (o_k - t_k) * o_k * (1 - o_k) * x_j $$
由此可得某条连接 $w_{jk}$ 上的偏导数,仅与当前连接的输出节点 $o_k$、对应真实值节点的结果 $t_k$ 和对应的输入节点 $x_j$ 有关。
链式法则
使用 TensorFlow 自动求导功能验证链式法则:
1 | x = tf.constant(1.) |
通过以上代码,通过自动求导计算出 ${\frac {\delta y_2} {\delta y_1}}$、 ${\frac {\delta y_1} {\delta w_1}}$ 和 ${\frac {\delta y_2} {\delta w_1}}$ 三个值,借助链式法则可以发现:
$$ {\frac {\delta y_2} {\delta w_1}} = {\frac {\delta y_2} {\delta y_1}} * {\frac {\delta y_1} {\delta w_1}} $$
由此可以发现偏导数的传播是符合链式法则的。
神经网络
在设计全连接网络时,网络的结构配置等超参数可以按经验法则自由设置,只需要遵循少量的约束即可。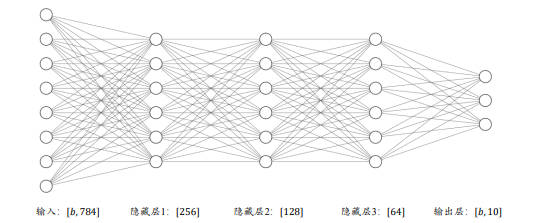
张量实现
网络模型实现如下:
1 | # 隐藏层 1 张量 |
使用 TensorFlow 自动求导计算梯度时,需要将前向计算过程放置在 tf.GradientTape() 环境中,利用 GradientTape()`` 对象的 gradient()`` 函数自动求解参数的梯度,并利用 optimizer 对象更新参数。
层实现
1 | fc1 = layers.Dense(256, activation=tf.nn.relu) |
激活函数
激活函数与阶跃函数、符号函数不同,因为这些函数都是平滑可导的,适合用于于梯度下降算法。
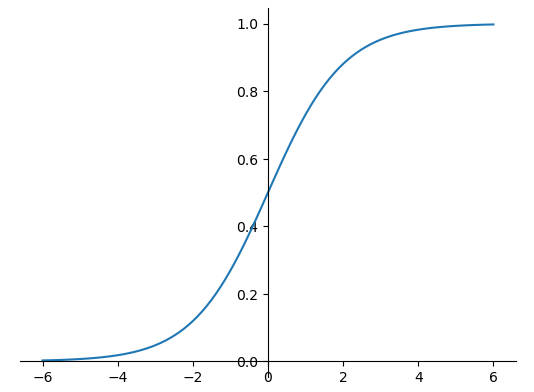
Sigmoid
Sigmoid 函数也被称为 Logistic 函数,其定义为
$$ Sigmoid(x) = {\frac {1} {1 + e^{-x}}} $$
该函数最大的特性在于可以将 x 的输入压缩到 $x \in (0,1)$ 区间,这个区间的数值在机器学习中可以表示以下含义:
- 概率分布
(0,1)区间的输出和概率的分布范围[0,1]一致,可以通过Sigmoid函数将输出转译为概率输出。 - 信号,可以将
0,1理解为某种信号,如像素的颜色强度,1表示当前通道颜色最强,0则表示当前通道无颜色。
1 | x = tf.linspace(-6.0, 6.0, 100) |
ReLU
在使用 Sigmoid 函数时,遇到输入值较大或较小时容易出现梯度为 0 的现象,该现象被称为梯度弥散现象,而在出现梯度弥散时,梯度长时间无法更新,会导致训练难以收敛或训练停止不动的现象发生。
为了解决上述问题 ReLU 函数被开始广泛使用,其函数定义如下:
$$ ReLU(x) = max(0, x) $$
1 | x = tf.linspace(-6.0, 6.0, 100) |
ReLU 函数的设计来源于神经科学,其函数值和导数值的计算十分简单,同时有着优秀的梯度特性,是目前最广泛应用的激活函数之一。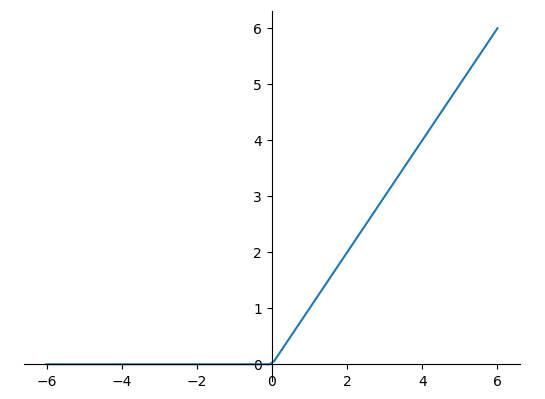
LeakyReLU
ReLU 函数在遇到输入值 x<0 时也会出现梯度弥散现象,因此 LeakyReLU 函数被提出,其表达式如下:
$$ LeakyReLU =
\begin{cases}
x, & x >= 0 \\
px, & x < 0
\end{cases} $$
其中 p 为用户自行设置的较小参数的超参数。
1 | x = tf.linspace(-6.0, 6.0, 100) |
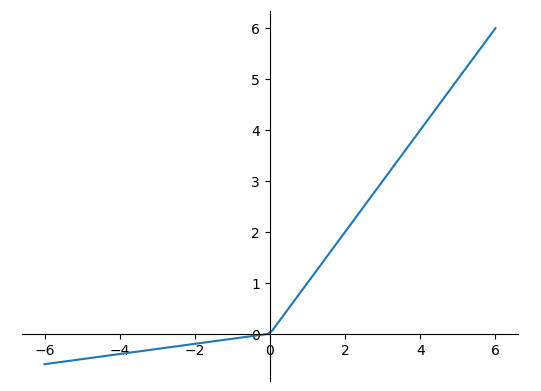
Tanh
Tanh 函数可以将 x 的输入压缩到 $x \in (-1,1)$ 区间,其定义为:
$$ tanh(x) = {\frac {e^x - e^{-x}} {e^x + e^{-x}}} = 2 * sigmoid(2x) - 1 $$tanh 激活函数可通过 Sigmoid 函数缩放平移后实现。
1 | x = tf.linspace(-6.0, 6.0, 100) |
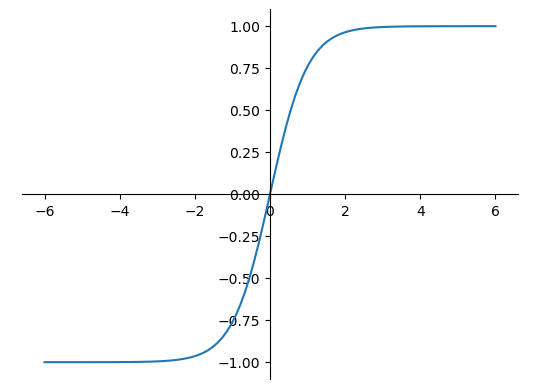
误差函数
在搭建完模型结构后,接下来就是选择合适的误差函数来计算误差。常见的误差函数有均方、交叉熵、 KL散度 、 Hinge Loss 函数等。
其中均方差函数和交叉熵函数较为常见,均方差函数用于回归问题,交叉熵函数用于分类问题。
均方误差函数
均方差 MSE 函数将输出向量和真实向量映射到笛卡尔坐标系的两个点上,通过计算这两个点之间的欧式距离(准确来讲是欧式距离的平方)来衡量两个向量之间的差距。MSE 误差函数的值总是大于等于 0,当 MSE 达到最小值 0 时,输出等于真实值,此时的神经网络的参数达到最优状态。
均方误差损失函数表达式为:
$$ L = {\frac {1} {2}} sum_{k=1}^K (y_k - o_k)^2 $$
其偏导数 ${\frac {\delta L} {\delta o_i}}$ 可以展开为:
$$ {\frac {\delta L} {\delta o_i}} = {\frac {1} {2}} sum_{k=1}^K {\frac {\delta} {\delta o_i}} (y_k - o_k)^2 $$
利用复合函数导数法则分解为:
$$ \begin{equation}
\begin{split}
{\frac {\delta L} {\delta o_i}} = {\frac {1} {2}} sum_{k=1}^K 2 (y_k - o_k) {\frac {\delta (y_k - o_k)} {\delta o_i}} \\
= sum_{k=1}^K (y_k - o_k) -1 {\frac {\delta o_k} {\delta o_i}} \\
= sum_{k=1}^K (o_k - y_k) {\frac {\delta o_k} {\delta o_i}}
\end{split}
\nonumber
\end{equation}$$
考虑 ${\frac {\delta o_k} {\delta o_i}}$ 仅当 k==i 时才为 1,也就是说偏导数 ${\frac {\delta L} {\delta o_i}}$ 只与第 i 号节点有关,与其他节点无关。均方误差函数的导数可以推导为:
$$ {\frac {\delta L} {\delta o_i}} = (o_i - y_i) $$
在 TensorFlow 中可以通过函数方式或层方式实现 MSE 误差计算。
1 | # 通过函数方式计算 |
交叉熵误差函数
熵用于衡量信息中的不确定度。熵越大代表不确定性越大,信息量也就越大。
基于熵引出交叉熵(Cross Entropy)的定义:
$$ H(p||q) = - sum_i p(i) log_2 q(i) $$
通过变换,交叉熵可以分解为 p 的熵 $H(p)$ 和 p 与 q 的 KL 散度(Kullback-Leibler Divergence)的和:
$$ H(p||q) = H(p) + D_{KL}(p||q) $$
而其中 KL 定义为:
$$ D_{KL}(p||q) = sum_i p(i) log({\frac {p(i)} {q(i)}}) $$KL 散度是用于衡量两个分布之间距离的指标。
根据 KL 散度定义推导分类问题中交叉熵的计算表达式:
$$ H(p||q) = H(p) + D_{KL}(p||q) = D_{KL}(p||q) = sum_j y_j log({\frac {y_j} {o_j}}) = 1*log{\frac {1} {o_i}} + sum_{j!=i} 0*log({\frac {0} {o_j}}) = - log o_i $$
二分类问题时 $H(p)=0$
最小化交叉熵损失函数的过程就是最大化正确类别的预测概率的过程。
1 | # 二分类交叉熵损失 |
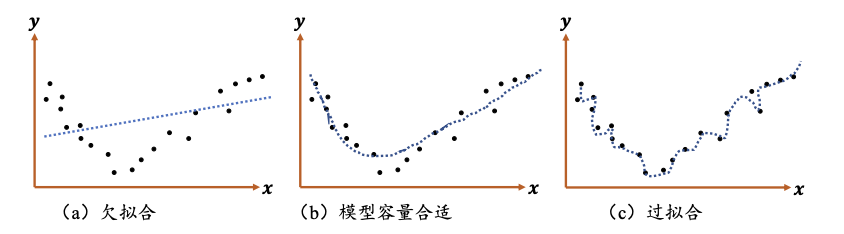
过拟合与欠拟合
当模型的容量过大时,网络模型除了学习训练集的模态之外,还会把额外的观测误差也学习,这样就会导致学习的模型在训练集上表现较好,但在未知的样本上表现不佳,也就是模型泛化能力较弱,这种现象被称为过拟合(Overfitting)。
当模型的容量过小时,模型不能够很好地学习到训练集数据的模态,导致模型在训练集上表现不佳,同时在未知的样本上也表现不佳,这种现象被称为欠拟合(Underfitting)。
用一个例子来解释模型容量和数据分布之间的关系:
a:使用简单线性函数去学习时,会很难学习到一个较好的函数,从而出现训练集和测试集均表现不佳。b:学习的模型和真实模型之间容量大致匹配时,模型才具有较好的泛化能力。c:使用过于复杂的函数去学习时,学习到的函数会过度“拟合”训练集,从而导致在测试集上表现不佳。
Keras 高层接口
Keras 是一个由 Python 语言开发的开源神经网络计算库,其被设计为高度模块化和易扩展的高层神经网络接口,使用户可以不需要通过过多的专业知识就可以轻松、快速地完成模型的搭建和训练。
在 TensorFlow 中 Keras 被实现在 tf.keras 子模块中。
常见功能模块
tf.keras 提供了一系列高层的神经网络相关类和函数,如经典数据集加载函数、网络层类、模型容器、损失函数类、优化器类、经典模型类等。
网络层
对于常见的神经网络层,可以直接使用张量方式的底层接口函数来实现,这些接口函数一般在 tf.nn 模块中。
在 tf.keras.layers 命名空间下提供了大量常见的网络层类,如全连接层、激活函数层、池化层、卷积层、循环神经网络层等。对于这些网络层类,只需要在创建时指定相关参数,并调用 __call__ 方法即可完成前向计算。在调用 __call__ 方法时,Keras 会自动触发每个层的前向传播逻辑,而这些逻辑也一般实现在 call 方法中。
1 | x = tf.constant([2., 1., 0.1]) |
网络
通过 Keras 的网络容器 Sequential 可以将多个网络层封装成一个网络模型,只需要调用一次网络模型即可完成数据从第一层到最后一层的顺序传播运算。
1 | model = Sequential([ |
模型装配、训练与测试
在训练网络模型时,一般的流程是通过前向计算获得网络的输出值,再通过损失函数计算网络误差,然后通过自动求导工具计算梯度并更新,同时间隔性地测试网络的性能。
模型装配
在 Keras 中有两个比较特殊的类:
keras.Layer类:网络层的母类,其定义了网络层的一些常见功能,如添加权值、管理权值列表等。keras.Model类:网络的母类,除了具有Layer类的功能之外,还具有保存模型、加载模型、训练与测试模型等功能。Sequential也是Model的子类。
1 | network = Sequential([ |
创建网络之后,正常流程就是迭代数据集多个 epoch,每次按批产生训练数据集、前向计算,然后通过损失函数计算误差值,并反向传播自动计算梯度、更新网络参数。
1 | from tensorflow.keras import optimizers, losses |
模型训练
模型装配完成后,通过 Model.fit() 函数传入待训练和测试的数据集,其会返回训练过程中的数据记录。
1 | # train_db 为 tf.data.Dataset 对象;epochs 指定训练迭代的数量;validation_data 指定用于验证的数据集和验证的频率 |
模型测试
通过 Model.predict() 方法即可完成模型的预测。
1 | x, y = next(iter(db_test)) |
模型保存与加载
模型在训练完成后,需要将模型保存到文件系统上,从而方便后续的模型测试与部署工作。
在 Keras 中有三种常用的模型保存与加载方法:
张量方式
网络的状态主要体现在网络结构以及网络层内部张量数据上,因此在拥有网络数据结构的前提下,直接保存网络张量参数是最轻量级的方式。通过Model.save_weights(path)将当前的网络参数保存到path文件上。1
network.save_weights('path')
在需要使用网络参数时可以通过
load_weights(path)加载保存的张量数据,但其需要使用相同的网络结构才能够正确恢复网络状态。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15network = Sequential([
layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)
]) # 构建网络层
network.build(input_shape=(4, 28*28))
network.summary()
network.compile(
optimizer=optimizers.Adam(learning_rate=0.001), # 采用 Adam 优化器,学习率设置为 0.001
loss=losses.CategoricalCrossentropy(from_logits=True), # 使用交叉熵损失函数,
metrics=['accuracy']
) # 模型装配
network.load_weights('')网络方式
通过Model.save(path)即可将模型的结构和模型的参数保存到path文件中。
通过keras.models.load_model(path)可以恢复网络结构和网络参数。1
2network.save('path') # 保存模型结构与模型参数
network = keras.models.load_model('path') # 从文件加载模型结构与模型参数SavedModel方式tf.saved_model.save(network, path)即可将模型以SaveModel的方式保存到path目录中,用户无需关心文件的保存格式。
通过tf.saved_model.load(path)函数可以实现从文件中恢复模型对象。1
2tf.saved_model.save(network, 'path') # 保存模型结构与模型参数到文件
tf.saved_model.load('path') # 从文件中恢复模型对象
测量指标
Keras 提供了一些常用的指标测量工具,其位于 keras.metrics 模块中,专门用于统计训练过程中常用的指标数据。
Keras 的指标测量工具使用方法一般分为四个主要步骤:新建测量器、写入数据、读取统计数据和清零测量器。
新建测量器
keras.metrics模块中有常用的测量器类,例如平均值Mean类,准确率Accuracy类,余弦相似度CosineSimilarity类等。1
2# 适合 Loss 数据
loss_meter = metrics.Mean()写入数据
通过测量器的update_state()函数写入新的数据,测量器会根据自身逻辑记录并处理采样数据。1
2# 记录采样数据,通过 float() 函数将张量转换为普通数值
loss_meter.update_state(float(loss))读取统计数据
在多次采样数据后,可以在需要的地方调用测量器的result()函数来获取统计值。1
2# 打印统计提前的平均 loss
print('loss:', loss_meter.result())清零测量器
通过reset_states()函数即可实现清除状态功能。1
2
3if step % 100 == 0:
print('loss:', loss_meter.result())
loss_meter.reset_states() # 打印完成后,清零测量器实战
1
2
3
4
5
6
7
8
9
10
11
12# 利用准确率测量器 Accuracy 类来统计训练过程中的准确率
# 创建准确率测量器
acc_meter = metrics.Accuracy()
# 将当前 batch 样本的标签和预测结果写入测量器
out = network(x)
pred = tf.argmax(out, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
acc_meter.update_state(y, pred)
# 输出统计的平均准确率
print('acc', acc_meter.result().numpy())
acc_meter.reset_states()
自定义网络
对于需要创建自定义逻辑的网络层,可以通过自定义类来实现。在创建自定义网络层类时,需要继承自 layers.Layer 基类;创建自定义网络类时,需要继承自 keras.Model 基类,这样建立的自定义类才能够方便地利用 Layer/Model 基类提供的参数管理等功能,同时也可以与其他标准网络层类交互使用。
自定义网络层
对于自定义网络层,至少需要实现初始化 __init__ 方法和前向传播逻辑 call 方法。
1 | # 创建自定义类,并继承自 layers.Layer。创建初始化方法,并调用母类的初始化方法,由于是全连接层,因此需要设置两个参数:输入特征的长度和输出特征的长度。 |
自定义网络
1 | # 自定义网络类,需要继承自 keras.Model |
总结
之前在学习机器学习内容的时候,感觉好难啊,我怎么什么都不会,但自从开始看深度学习相关的内容,就发现好些东西突然醒悟,之前好多不理解的东西也能理解,哈哈哈哈哈哈哈。这就是学习新东西的魅力。
总之就是持续学习,继续进步。
引用
个人备注
此博客内容均为作者学习《TensorFlow深度学习》所做笔记,侵删!
若转作其他用途,请注明来源!