简介
在之前的文章中主要介绍了神经网络的基本原理、 TensorFlow 使用和基本的全连接层模型,而本节正如题目所言:卷积神经网络。
全连接层的问题
首先分析下全连接层的问题,通过 TensorFlow 快速搭建一个网络模型,添加四个 Dense 层,使用 Sequential 容器封装为一个网络对象。
1 | model = Sequential([ |
在该网络模型中,对于输入节点数为 n,输出节点数为 m,则对于每一次的全连接层来说计算的参数量为 n * m + m。以同样的方式计算剩余层的参数量,则最终的总参数量大约为 34 万个。而在实际中,网络的计算过程中还需要缓存计算图模型、梯度信息、输入和输出中间结果等,其中关于梯度计算等占用资源非常多!
基础原理
局部相关性
在实际应用中存在着大量以位置或距离作为重要性分布衡量标准的数据。以 2D 图片为例,实心网格线中心所在的像素点为参考点,其周边欧氏距离小于或等于 k/2^(1/2) 的像素点以矩阵网格展示,其网格线内的像素点重要性较高,而外部的像素点重要性较低。
这种以距离的重要性分布假设特性被称为局部相关性,其仅关心距离自己较近部分的节点,而忽略较远部分的节点。
权值共享
在卷积神经网络(CNN)中,权值共享是指在网络的不同位置使用相同的权重参数。这种权值共享的机制使得 CNN 能够有效地处理图像等具有局部相关性的数据。通过权值共享,网络可以学习到不同位置的特征,而不需要为每个位置都学习独立的参数,从而减少需要学习的参数数量,提高网络的参数效率。
卷积计算
在 CNN 的卷积层中卷积核(filter)通过滑动窗口的方式在输入数据上进行卷积操作。如果使用权值共享,那么无论卷积核在输入数据的哪个位置进行卷积,都会使用相同的卷积核参数。这样,在不同位置学习到的特征将是共享的,而不同位置之间的参数是共享的。这种共享使得CNN能够更好地捕捉到输入数据的局部特征,从而提高了网络的性能和泛化能力。
离散卷积操作是指简化的“局部连接层”,对于 k * k 范围内的所有像素,采用权值累乘相加的方式提取信息,每个输出节点表示对应感受野区域的特征信息。
输入和卷积核
卷积神经网络通过充分利用局部相关性和权值共享思想,极大地减少了网络的参数量,从以提高训练效率,以此推动实现更大的深层网络。
下面主要介绍卷积神经网络层的具体计算流程。
以 2D 图片为例,卷积层输入高、宽分别用 h, w 来表示,通道数为 $c_{in}$ 的输入特征图 X,在 $c_{out}$ 个高、宽均为 k,通道数为 $c_{in}$ 的卷积核作用下,生成高、宽分别为 $h^*, w^*$,通道数为 $c_{out}$ 的特征图输出。
单通道输入和单卷积核
首先讨论单通道输入 $c_{in}=1$,单个卷积核 $c_{out}=1$ 的情况。以输入 X 为 5*5 的矩阵,卷积核为 3*3 的矩阵为例,如下图所示:
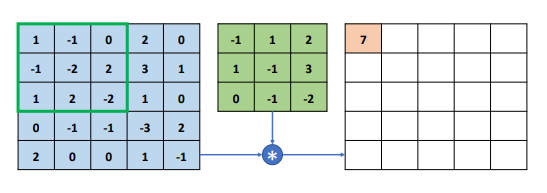
与卷积核相同大小的感受野首先移动到输入 X 的最左上方,选中输入 X 中 3*3 的感受野区域,与卷积核对应元素相乘,得到运算结果 3*3 的矩阵后,该矩阵中的所有元素全部相加,然后写入输出矩阵第一行、第一列的位置上。
$$ -1 - 1 + 0 - 1 + 2 + 6 + 0 - 2 + 4 = 7$$
在完成第一个感受野区域计算后,感受野窗口向右移动一个步长单位(Strides),即可得到下一个感受野,按照相同的计算方式与卷积核相乘累加写入输出矩阵第一行、第二个位置。
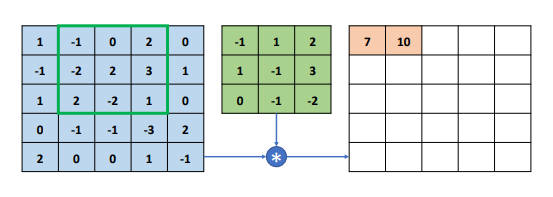
按照上述方法每次感受野区域向右移动一个步长单位,若超出边界时,则向下移动一个步长单位并回到行首,直至感受野区域移动到最右边、最下边的位置。
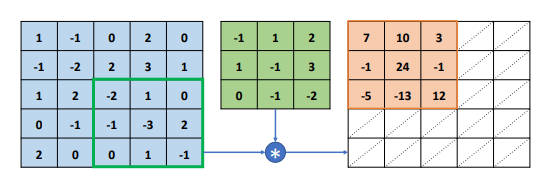
至此就完成了单通道输入、单个卷积核的运算流程。
多通道输入和单卷积核
彩色图片的多通道输入的卷积层较为常见,其包含 R/G/B 三个通道,每个通道上的数据分别表示 RGB 色彩的强度。
在多通道输入的情况下,卷积核的通道数将与输入 X 的通道数量一致,卷积核的第 i 个通道和输入 X 的第 i 个通道相互运算,由此得到第 i 个中间矩阵,此时就可以视为单通道输入与单卷积核的情况,所有通道的中间矩阵对应值再次相加即可作为最终输出。
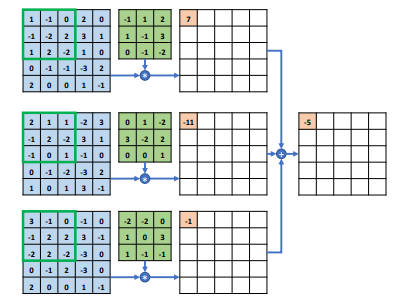
初始状态下每个通道的感受野区域同步在对应通道的最左边、最上边位置,每个通道上感受野区域元素与卷积核对应通道上的矩阵相乘累加,分别得到三个通道上的输出,再将中间变量相加得到最终值,写入输出矩阵的第一行、第一列的位置。
感受野区域同步在输入 X 的通道上向右移动一个步长单位,再次计算感受野区域与卷积核对应通道上的矩阵相乘累加,得到中间变量后再全部相加得到最终值,并写入对应位置。
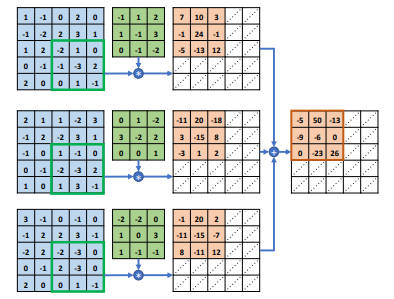
依次按照上述方式完成所有的计算,直至移动到输入 X 最下边、最右边的感受野区域,此时就完成了全部的卷积运算,得到一个 3*3 的输出矩阵。
多通道输入和多卷积核
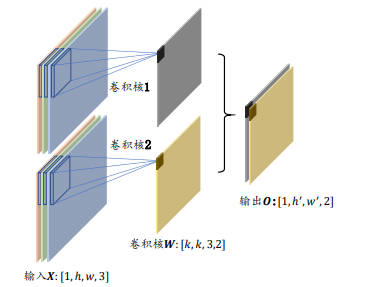
一般情况下一个卷积核只能完成某种逻辑的特征提取,而当需要同时提取多种特征时,则可以通过增加多个卷积核来得到多种特征,以提高神经网络的表达能力,这就是多通道输入、多卷积核的情况。
下面以三通道输入、两卷积核的卷积层为例。第一个卷积核与输入 X 运算得到输出 O 的第一个通道,第二个卷积核与输入 X 运算得到输出 O 的第二个通道,多个输出的通道拼接在一起后得到最终的输出 O。每个卷积核大小 k、步长 s、填充设定等都必须一致,这样最终才能保证输出通道的统一,从而满足拼接的条件。
步长和填充
步长
感受野区域密度的控制一般是通过移动步长(Strides)实现。而步长是指感受野窗口每次移动的长度单位,对于 2D 图片来说,分为向右和向下方向的移动长度。
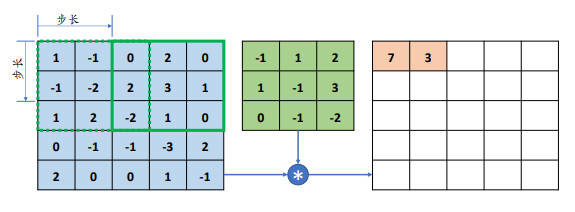
通过设定步长 s,可以有效地控制信息密度的提取,当步长较小时感受野以较小幅度移动窗口,可以提取更多的特征信息,由此输出的张量尺寸也更大;当步长较大时感受野以较大幅度移动窗口,减少了计算代价,过滤冗余信息,输出的张量尺寸也更小。
填充
在经过卷积运算之后的输出 O 的高宽一般都会小于输入 X 的高宽,即使步长 s=1 其输出 O 的高宽也会略小于输入 X 的高宽。因此为了输出 O 的高宽能与输入 X 的高宽相等,可以通过在原输入 X 的高宽维度上进行填充(Padding)若干个无效元素,以此得到增大的输入 $X^*$。
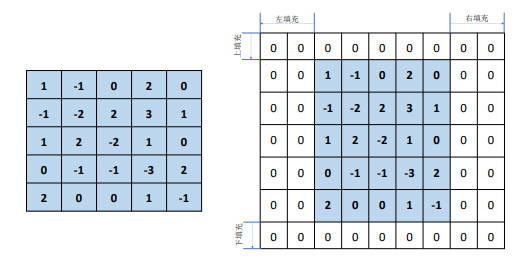
在高/行的上(Top)、下(Bottom)方向,宽/列的左(Left)、右(Right)方向均可以进行不定数量的填充操作,填充的值默认为 0,不过也可以填充自定义值。
卷积层
卷积层实现
在 TensorFlow 中可以通过自定义权值的底层实现方式搭建神经网络,也可以直接调用现成的卷积层类的高层实现方式快速搭建神经网络。
自定义权值
在 TensorFlow 中通过 tf.nn.conv2d() 函数可以实现 2D 卷积运算。tf.nn.conv2d() 基于输入 $x:[b,h,w,c_{in}]$ 和卷积核 $w:[k,k,c_{in},c_{out}]$ 进行卷积运算,得到输出 $o:[b,h^*,w^*,c_{out}]$,其中 $c_{in}$ 表示输入通道数,$c_{out}$ 表示卷积核数量,也是特征图的输出通道数。
1 | x = tf.random.normal([2,5,5,3]) # 模拟输入,高宽为5,通道数为3 |
其中 padding 的参数格式为:padding=[[0,0],[上,下],[左,右],[0,0]]
特别地通过设置 padding='SAME', strides=1 可以得到输入、输出同样大小的卷积层。
1 | x = tf.random.normal([2,5,5,3]) # 模拟输入,高宽为5,通道数为3 |
卷积层和全连接层一样均可以设置偏置向量,但 tf.nn.conv2d() 函数没有实现偏置向量计算,不过可以手动添加。
1 | b = tf.zeros(4) |
卷积层类
通过卷积层类 layers.Conv2D 则可以不需要手动定义卷积核 W 和偏置张量 B,直接调用类实例即可完成卷积层的前向计算。
在新建卷积层类时,只需要指定卷积核数量参数 filters、卷积核大小 kernel_size、步长 strides、填充 padding 等即可。
1 | layer = layers.Conv2D(4, kernel_size=3, strides=3, padding='SAME') |
在创建完成后,通过调用实例 __call__() 函数即可完成前向计算。
1 | x = tf.random.normal([2,5,5,3]) # 模拟输入,高宽为5,通道数为3 |
梯度传播
前面了解了如何通过感受野区域移动的方式实现离散卷积计算,那这其中的梯度又是如何计算的呢?
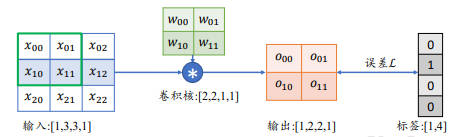
可以得出输出张量 O 的表达式:
$$ o_{00} = x_{00}w_{00} + x_{01}w_{01} + x_{10}w_{10}+ x_{11}w_{11} + b $$
以计算 $w_{00}$ 为例,通过链式法则分解:
$$ {\frac {\delta L} {\delta_{w_{00}}}} = sum_{i \in [00, 01, 10, 11]} {\frac {\delta L} {\delta_{o_i}}} {\frac {\delta_{o_i}} {\delta_{w_{00}}}} $$
其中 ${\frac {\delta L} {\delta_{o_i}}}$ 可以由误差函数推导而得,则 ${\frac {\delta_{o_i}} {\delta_{w_{00}}}}$:
$$ {\frac {\delta_{o_{00}}} {\delta_{w_{00}}}} = {\frac {\delta (x_{00}w_{00} + x_{01}w_{01} + x_{10}w_{10}+ x_{11}w_{11} + b)} {w_{00}}} = x_{00} $$
由上述可以看出通过循环移动感受野区域的方式并没有改变网络层的可导性,同时梯度的计算也并不复杂,只是当网络层数增加后人工推导梯度将很难进行。
卷积表示
池化层
卷积层可以通过 strides 的大小来动态调整特征图的高宽成倍缩小,从而降低参数量。除此之外还有一种专门的网络层可以实现尺寸缩减功能,那就是池化层(Pooling Layer)。
池化层同样基于局部相关性的思想,通过从局部相关的一组元素中进行采样或信息聚合,从而得到新的元素值。目前共有两种类型:
- 最大池化层(
Max Pooling):从相关元素集中提取最大的一个元素值。 - 平均池化层(
Average Pooling):从相关元素集中计算平均值并返回。
以 5*5 的输入 X 的最大池化层为例,其中感受野窗口大小 k=2,步长 s=1。

取第一个感受野区域元素集合 [1,-1,-1,-2],其中的最大值为 1,写入对应的位置。之后的以此类推,可得到最终的输出 O。
BN 层
卷积神经网络的出现使得网络参数量大大减低,使得几十层的神经网络成为现实,然而在实际中网络训练中,网络层数的增加使得训练变得很不稳定,有时会出现长时间不收敛的情况,同时网络对于超参数的轻微变会非常敏感。
为解决上述问题就提出来一种参数标准化(Normalize)的方法,基于参数标准化设计了 Batch Normalization (BN) 层。BN 层使得网络的超参数设定更加自由,其被广泛应用于各种深度网络模型中,卷积层、BN 层、ReLU 层、池化层等成为网络模型的标准基础模块,通过堆叠 Conv-BN-ReLU-Pooling 方式可以获得不错的模型性能。
说到这里那就看看 BN 层进行参数标准化后有哪些变化?
在之前了解过 Sigmoid 激活函数和其梯度分布,当输入值 x 无限大时,其导数就会变得很小,趋近于 0,此时就会出现梯度弥散现象。而为了避免 Sigmoid 函数出现梯度弥散现象,就需要将函数输入 x 映射到 0 附近的一段较小区间内,通过标准化重映射后此处的导数不至于过小,而从减少梯度弥散现象。
举个例子,现在有两个输入参数的线性模型:
$$ L = a = w_1 * x_1 + w_2 * x_2 + b $$
考虑不同输入分布的优化情况:
- $x_1 \in [1,10], x_2 \in [1,10]$
- $x_1 \in [1,10], x_2 \in [100,1000]$
根据求导公式可得:
$$ {\frac {\delta L} {\delta w_1}} = x_1 $$
$$ {\frac {\delta L} {\delta w_2}} = x_2 $$
当 $x_1, x_2$ 的输入数据范围大致相当时,其偏导数基本一致;而当 $x_1, x_2$ 的输入数据范围相差较大时,例如 $x_1 << x_2$ 时,则会出现 ${\frac {\delta L} {\delta w_1}} << {\frac {\delta L} {\delta w_2}}$,此时 $w_2$ 的更新会出现梯度弥散现象。
那数据标准化操作如何实现?将数据 x 映射到 $\hat x$:
$$ \hat x = {\frac {x - \mu_r} {\sqrt {\sigma_{r^2} + \epsilon}}} $$
$\mu_r, \sigma_{r^2}$ 来自统计的数据的均值和方差,$\epsilon$ 是为了防止出现除 0 错误而设置的较小数字。
在基于 Batch 的训练阶段,计算 Batch 内部的均值 $\mu_B$ 和方差 $\sigma_{B^2}$,其可以被视为近似于 $\mu_r, \sigma_{r^2}$:
$$ \mu_B = {\frac {1} {m}} sum_{i=1}^m x_i $$
$$ \sigma_{B^2} = {\frac {1} {m}} sum_{i=1}^m (x_i - \mu_B)^2 $$
前向传播
BN 层的输入标记为 x,输出标记为 $\hat x$,分别就训练阶段和测试阶段说明前向传播过程:
- 训练阶段
首先计算当前Batch的 $\mu_B, \sigma_{B^2}$,根据
$$ \hat x_{train} = {\frac {x_{train} - \mu_B} {\sqrt {\sigma_{B^2} + \epsilon}}} * \gamma + \beta $$
计算BN层输出。
同时按照
$$\mu_r \leftarrow momentum * \mu_r + (1 - momentum) * \mu_B$$
$$ \sigma_{r^2} \leftarrow momentum * \sigma_{r^2} + (1 - momentum) * \sigma_{B^2} $$
迭代更新全局训练参数的统计值 $\mu_r, \sigma_{r^2}$,其中 $momentum$ 是设置的一个超参数,其用于确定 $\mu_r, \sigma_{r^2}$ 的更新幅度(类似于学习率)。在TensorFlow中 $momentum$ 的默认设置为0.99。 - 测试阶段
BN层根据
$$ \hat x_{test} = {\frac {x_{test} - \mu_B} {\sqrt {\sigma_{B^2} + \epsilon}}} * \gamma + \beta $$
计算输出 $\hat x_{test}$,其中 $\mu_r, \sigma_{r^2}, \gamma, \beta$ 来自于训练阶段统计或优化的结果,在测试阶段直接使用即可并不会更新这些参数。
反向更新
在训练模式下的反向更新阶段中,反向传播算法根据损失 L求解梯度 ${\frac {\delta L} {\delta \gamma}}, {\frac {\delta L} {\delta \beta}}$,并按梯度更新法则自动优化 $\gamma, \beta$ 参数。
以 shape 为 [100,32,32,3] 的输入为例,在通道轴 c 上面的均值计算如下:
1 | x = tf.random.normal([100,32,32,3]) # 构造输入 |
通道有 c 个通道数,则有 c 个均值产生。
除了在 c 轴上统计数据 $\mu_B, \sigma_{B^2}$ 的方式,也很容易将其推广到其他维度的计算均值的方式:
Layer Norm:统计每个样本的所有特征的均值和方差。Instance Norm:统计每个样本的每个通道上特征的均值和方差。Group Norm:将c通道分为若干个组,统计每个样本的通道组内特征的均值和方差。
BN 层实现
在 TensorFlow 中通过 layers.BatchNormalization() 类可以非常方便地实现 BN 层:
1 | layer = layers.BatchNormalization() |
与全连接层、卷积层不同,由于 BN 层在训练阶段和测试阶段行为不同,需要通过设置 training 标志来区分训练模式或测试模式。
1 | network = Sequential([ |
激活层
激活层又名非线性映射层(non-linearity mapping),其主要是通过激活函数增加整个网络的的非线性能力(表达能力或抽象能力)。
激活函数中最经典当属 Sigmoid 函数和 ReLU 函数。
激活函数在之前已经说过,这里就不过多赘述,忘记的可以看看之前的内容。
变种卷积层
空洞卷积
普通的卷积层为了减少网络的参数量,通常卷积核使用较小的 1*1 或 3*3 感受野。由于小卷积核提取网络特征时的感受野区域有限,增大感受野区域又会使得网络的参数量计算增大,因此其在实际中需要权衡比较。
空洞卷积(Dilated/Atrous Convolution)就较好的解决了该问题,空洞卷积是在原有卷积的基础上增加一个 Dilated Rate 参数,用于控制感受野区域的采样步长。
当感受野的采样步长 Dilated Rate 为 1 时,每个感受野采样点之间的距离为 1,此时空洞卷积就与普通的卷积一致;当 Dilated Rate 为 2 时,感受野每两个单元采样一个点,每个采样格子之间的距离为 2;尽管 Dilated Rate 的增大会使得感受野区域增大,但实际中参与运算的点数仍未保持不变。
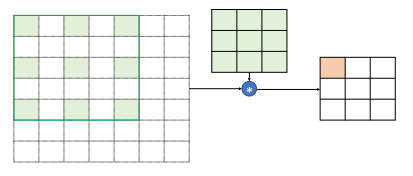
上述图片中的 Dilated Rate 为 2。
在 TensorFlow 中可以通过设置 layers.Conv2D() 类中 dilation_rate 参数来选择使用普通卷积还是空洞卷积。
1 | x = tf.random.normal([1,7,7,1]) |
分离卷积
普通卷积在对多通道输入进行运算时,卷积核的每个通道与输入的每个通道分别进行卷积运算,得到多通道的特征图,之后对应元素相加产生单个卷积核的最终输出。而深度可分离卷积(Depth-wise Separable Convolution)的计算流程则不同,卷积核的每个通道与输入的每个通道进行卷积运算,得到多个通道的中间特征,这些多通道的中间特征接下来进行多个 1*1 卷积核的普通卷积运算,得到多个高宽不变的输出,这些输出在通道轴上进行拼接,从而产生最终的分离卷积层输出。
分离卷积层包含两次卷积运算:
- 第一步卷积运算是单个卷积核。
- 第二步卷积运算包含多个卷积核。
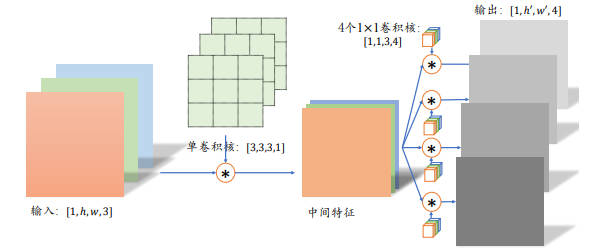
分离卷积有什么优势呢?一个很明显的优势就是分离卷积的参数计算量约是普通卷积的 1/3。以上述为例:
- 普通卷积的参数量:
3 * 3 * 3 * 4 = 108 - 分离卷积的参数量:
3 * 3 * 3 * 1 + 1 * 1 * 3 * 4 = 39
分离卷积使用更少的参数量却也能完成普通卷积同样的输入输出尺寸变换,其在计算敏感的网络中应用很多。
经典卷积网络
AlexNet
AlexNet 网络特点:
- 层数达到了较深的
8层。 - 采用了
ReLU激活函数,之前的神经网络大多采用Sigmoid激活函数,计算相对复杂且容易出现梯度弥散现象。 - 引用
Dropout层,其极大提高模型的泛化能力,防止过拟合。
AlexNet 网络结构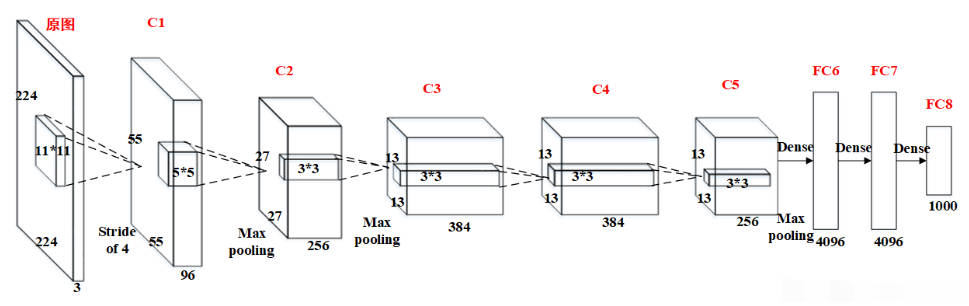
VGG 系列
VGG 系列网络特点:
- 层数提升至
19层。 - 全部采用更小的
3*3卷积核,相比AlexNet参数量更少,计算代价更低。 - 采用更小的池化层
2*2窗口和s=2步长。
VGG 系列网络结构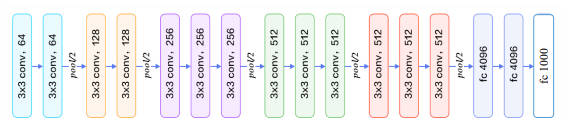
GoogleNet
GoogleNet 网络采用模块化设计思想,通过堆叠大量 Inception 模块,以此形成复杂的网络结构。Inception 模块输入为 X,通过 4 个子网络得到 4 个网络输出,在通道轴上进行拼接合并,最终形成 Inception 模块的输出。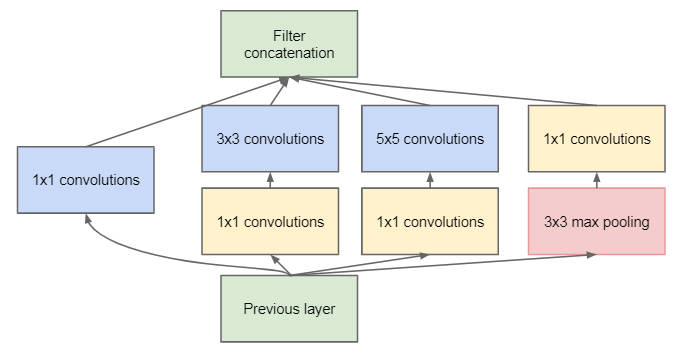
GoogleNet 网络特点:
- 引入
Inception模块。 - 使用
1*1卷积核进行降维及映射处理。 - 添加两个辅助分类器帮助训练。
- 放弃使用全连接层,使用平均池化层。
GoogleNet 网络结构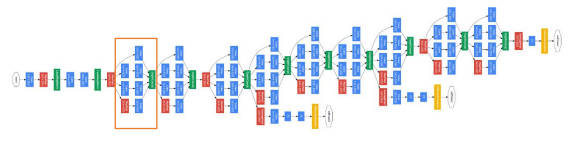
总结
一入深度学习深似海,回首机器学习在招手。😭
引用
https://cs231n.github.io/
卷积神经网络
深度学习之图像分类(五)– GoogLeNet网络结构
经典卷积神经网络 bilibili 课程
个人备注
此博客内容均为作者学习《TensorFlow深度学习》所做笔记,侵删!
若转作其他用途,请注明来源!